
GPT-3를 사용하여 비즈니스 요구 사항을 충족하는 엔터프라이즈 챗봇 구축

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-24 21:43:111618검색

Background
챗봇 또는 고객 서비스 도우미는 인터넷을 통해 문자나 음성을 통해 사용자에게 전달함으로써 비즈니스 가치를 달성하고자 하는 AI 도구입니다. 단순한 논리를 기반으로 한 초기 로봇에서부터 자연어 이해(NLU)를 기반으로 한 현재의 인공지능에 이르기까지 챗봇의 개발은 지난 몇 년간 급속도로 발전해 왔습니다. 후자의 경우 이러한 챗봇을 구축할 때 가장 일반적으로 사용되는 프레임워크나 라이브러리로는 해외 RASA, Dialogflow, Amazon Lex 등이 있으며 국내 대기업 Baidu, iFlytek 등도 있습니다. 이러한 프레임워크는 자연어 처리(NLP)와 NLU를 통합하여 입력 텍스트를 처리하고, 의도를 분류하고, 올바른 작업을 트리거하여 응답을 생성할 수 있습니다.
대규모 언어 모델(LLM)의 출현으로 이러한 모델을 직접 사용하여 완전한 기능을 갖춘 챗봇을 구축할 수 있습니다. 유명한 LLM 사례 중 하나는 대화 또는 세션 데이터를 사용하여 모델을 미세 조정할 수 있는 OpenAI의 Generative Pre-trained Transformer 3(GPT-3: chatgpt는 gpt 미세 조정 및 인간 피드백 모델 추가를 기반으로 함)입니다. 자연스러운 대화와 유사한 텍스트. 이 기능은 맞춤형 챗봇을 구축하는 데 가장 적합한 선택입니다.
오늘은 GPT-3 모델을 미세 조정하여 나만의 간단한 대화형 챗봇을 구축하는 방법에 대해 이야기하겠습니다.
종종 우리는 고객 서비스 대화 기록, 채팅 로그 또는 영화 자막과 같은 자체 비즈니스 대화 사례의 데이터 세트에서 모델을 미세 조정하고 싶습니다. 미세 조정 프로세스는 이 대화 데이터에 더 잘 맞도록 모델의 매개변수를 조정하여 챗봇이 사용자 입력을 더 잘 이해하고 응답하도록 만듭니다.
GPT-3을 미세 조정하려면 사전 훈련된 모델과 미세 조정 도구를 제공하는 Hugging Face의 Transformers 라이브러리를 사용할 수 있습니다. 라이브러리는 다양한 크기와 기능을 갖춘 여러 GPT-3 모델을 제공합니다. 모델이 클수록 처리할 수 있는 데이터가 많아지고 정확도도 높아집니다. 하지만 단순화를 위해 이번에는 소량의 코드 작성으로 미세 조정을 구현할 수 있는 OpenAI 인터페이스를 사용합니다.
다음 단계는 OpenAI GPT-3를 사용하여 미세 조정을 구현하는 것입니다. 여기에서 데이터 세트를 얻을 수 있습니다. 죄송합니다. 중국에는 이러한 처리된 데이터 세트가 정말 적습니다.
1. 오픈 API 키 만들기
계정 만들기는 매우 간단합니다. 이 링크를 열면 됩니다. openai 키를 통해 OpenAI의 모델에 액세스할 수 있습니다. API 키를 생성하는 단계는 다음과 같습니다.
- 계정에 로그인합니다.
- 페이지 오른쪽 상단으로 이동하여 계정 이름을 클릭하고 드롭다운을 클릭한 다음 "API 키 보기"를 클릭합니다.
- "새 키 만들기"를 클릭하고 생성된 키를 즉시 복사하고 기억하고 저장하세요. 그렇지 않으면 다시 볼 수 없습니다.
2. 데이터 준비
API 키를 생성한 후 미세 조정 모델을 위한 데이터 준비를 시작할 수 있으며 여기에서 데이터 세트를 볼 수 있습니다.

1단계:
OpenAI 라이브러리 설치 pip install openai
설치 후 데이터를 로드할 수 있습니다.
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))질문을 인터뷰 AI 열에 로드하고 해당 답변을 인간 열에 로드합니다. OPENAI_API_KEY
를 저장하려면 환경 변수 .env 파일도 만들어야 합니다. 다음으로 데이터를 GPT-3 표준으로 변환합니다. 문서에 따르면 데이터가 두 개의 키가 있는 JSONL 형식인지 확인하는 것이 중요합니다. 예: 완료
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }
{ "prompt" :"<prompt text>" ,"completion" :"<ideal generated text>" }위의 내용에 맞게 데이터 세트를 재구성하고 기본적으로 데이터 프레임의 각 행을 반복하고 텍스트를 Human 에 할당합니다. 인터뷰 AI 텍스트를 완료로 할당합니다.
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')prepare_data 명령을 사용하면 메시지가 표시될 때 몇 가지 질문이 표시되며 Y 또는 N 응답을 제공할 수 있습니다.
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")마지막으로 data_prepared.jsonl이라는 파일이 디렉터리에 덤프됩니다.
3. 재미있는 모델 조정
모델을 재미있게 조정하려면 다음 명령 한 줄만 실행하면 됩니다.
os .system( "openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci " )
这基本上使用准备好的数据从 OpenAI 训练davinci模型,fine-tuning后的模型将存储在用户配置文件下,可以在模型下的右侧面板中找到。
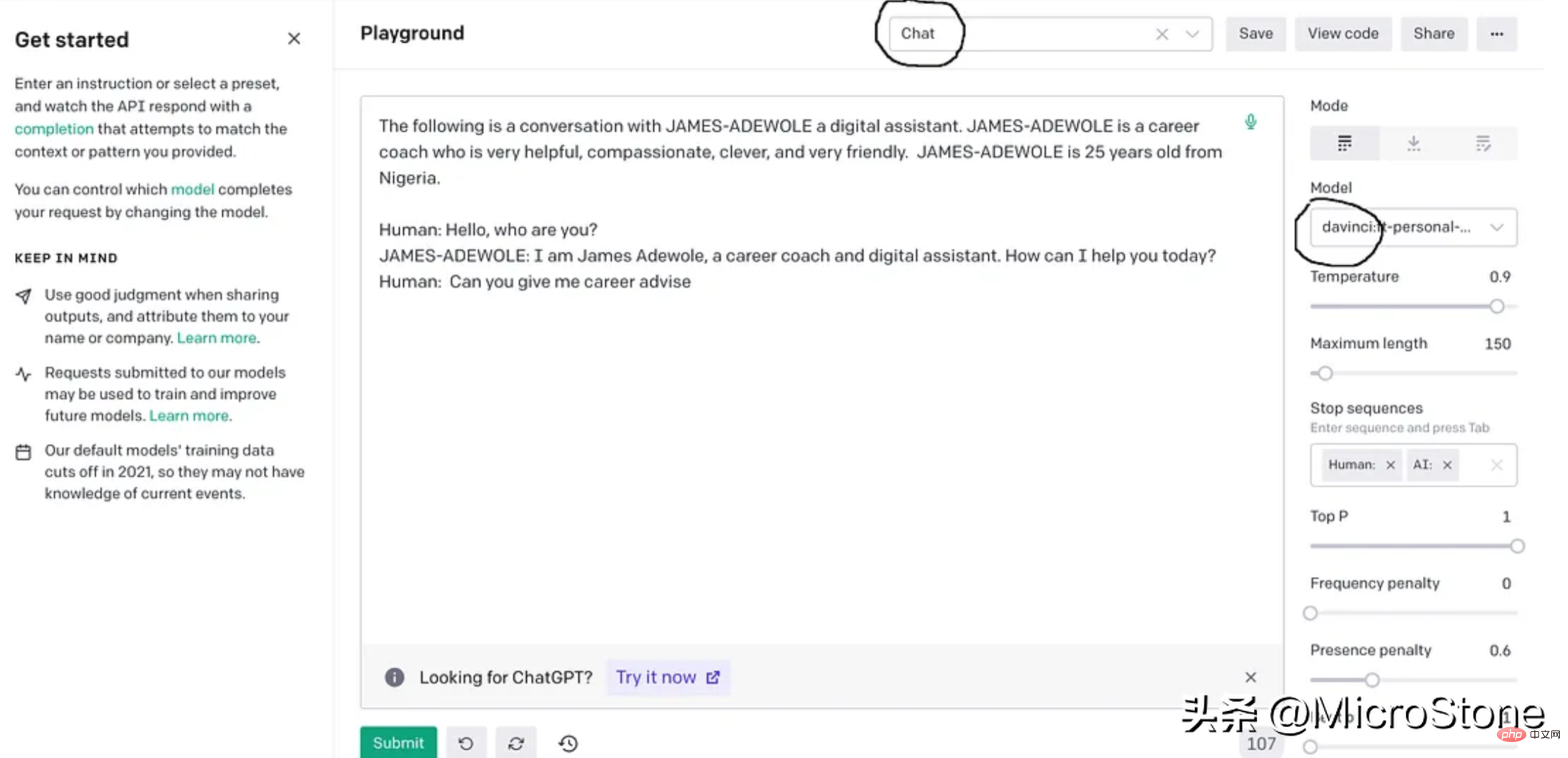
4、模型调试
我们可以使用多种方法来验证我们的模型。可以直接从 Python 脚本、OpenAI Playground 来测试,或者使用 Flask 或 FastAPI 等框构建 Web 服务来测试。
我们先构建一个简单的函数来与此实验的模型进行交互。
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()
output = generate_response(input_text)
print(output)把它们放在一起。
import os
import json
import openai
import pandas as pd
from dotenv import load_dotenv
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_KEY')
openai.api_key = os.getenv('OPENAI_KEY')
data = pd.read_csv('data/data.csv')
new_df = pd.DataFrame({'Interview AI': data['Text'].iloc[::2].values, 'Human': data['Text'].iloc[1::2].values})
print(new_df.head(5))
output = []
for index, row in new_df.iterrows():
print(row)
completion = ''
line = {'prompt': row['Human'], 'completion': row['Interview AI']}
output.append(line)
print(output)
with open('data/data.jsonl', 'w') as outfile:
for i in output:
json.dump(i, outfile)
outfile.write('n')
os.system("openai tools fine_tunes.prepare_data -f 'data/data.jsonl' ")
os.system("openai api fine_tunes.create -t 'data/data_prepared.jsonl' -m davinci ")
def generate_response(input_text):
response = openai.Completion.create(
engine="davinci:ft-personal-2023-01-25-19-20-17",
prompt="The following is a conversation with DSA an AI assistant. "
"DSA is an interview bot who is very helpful and knowledgeable in data structure and algorithms.nn"
"Human: Hello, who are you?n"
"DSA: I am DSA, an interview digital assistant. How can I help you today?n"
"Human: {}nDSA:".format(input_text),
temperature=0.9,
max_tokens=150,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.6,
stop=["n", " Human:", " DSA:"]
)
return response.choices[0].text.strip()示例响应:
input_text = "what is breadth first search algorithm" output = generate_response(input_text)
The breadth-first search (BFS) is an algorithm for discovering all the reachable nodes from a starting point in a computer network graph or tree data structure
结论
GPT-3 是一种强大的大型语言生成模型,最近火到无边无际的chatgpt就是基于GPT-3上fine-tuning的,我们也可以对GPT-3进行fine-tuning,以构建适合我们自己业务的聊天机器人。fun-tuning过程调整模型的参数可以更好地适应业务对话数据,让机器人更善于理解和响应业务的需求。经过fine-tuning的模型可以集成到聊天机器人平台中以处理用户交互,还可以为聊天机器人生成客服回复习惯与用户交互。整个实现可以在这里找到,数据集可以从这里下载。
위 내용은 GPT-3를 사용하여 비즈니스 요구 사항을 충족하는 엔터프라이즈 챗봇 구축의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!