
Java에서 손으로 쓴 분산 눈송이 SnowFlake를 통해 ID를 생성하는 방법

- PHPz앞으로
- 2023-04-24 21:34:161175검색
SnowFlake 알고리즘
SnowFlake 알고리즘으로 생성된 id의 결과는 64비트 정수입니다. 그 구조는 다음과 같습니다.
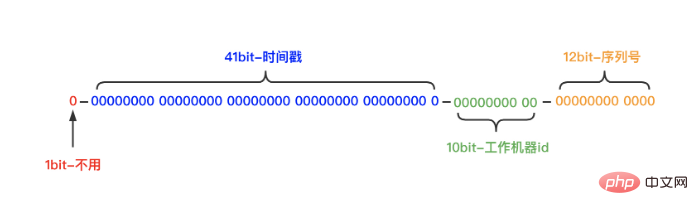
은 4개의 섹션으로 나뉩니다.
첫 번째 섹션: 1비트는 사용되지 않으며 항상 고정됩니다. 0 .
(바이너리의 가장 높은 비트가 부호 비트이므로 1은 음수, 0은 양수를 나타냅니다. 생성된 ID는 일반적으로 양의 정수이므로 가장 높은 비트는 0으로 고정됩니다.)
두 번째 단락: 41 비트는 밀리초 시간입니다(41비트 길이는 69년 동안 사용할 수 있음)
세 번째 단락: 10비트는 작업자 ID입니다(10비트 길이는 최대 1024개 노드 배포를 지원합니다)
(여기서 10비트는 두 부분으로 나뉘는데, 첫 번째 부분은 5비트로 표시됩니다. 데이터 센터 ID(0-31)의 두 번째 5자리 부분은 컴퓨터 ID(0-31)를 나타냅니다.)
네 번째 문단: 12비트 수 밀리초 이내(12비트 계산 시퀀스 번호는 밀리초당 4096개의 ID 일련 번호를 생성하는 각 노드를 지원합니다)
코드 구현:
import java.util.HashSet;
import java.util.concurrent.atomic.AtomicLong;
public class SnowFlake {
//时间 41位
private static long lastTime = System.currentTimeMillis();
//数据中心ID 5位(默认0-31)
private long datacenterId = 0;
private long datacenterIdShift = 5;
//机房机器ID 5位(默认0-31)
private long workerId = 0;
private long workerIdShift = 5;
//随机数 12位(默认0~4095)
private AtomicLong random = new AtomicLong();
private long randomShift = 12;
//随机数的最大值
private long maxRandom = (long) Math.pow(2, randomShift);
public SnowFlake() {
}
public SnowFlake(long workerIdShift, long datacenterIdShift){
if (workerIdShift < 0 ||
datacenterIdShift < 0 ||
workerIdShift + datacenterIdShift > 22) {
throw new IllegalArgumentException("参数不匹配");
}
this.workerIdShift = workerIdShift;
this.datacenterIdShift = datacenterIdShift;
this.randomShift = 22 - datacenterIdShift - workerIdShift;
this.maxRandom = (long) Math.pow(2, randomShift);
}
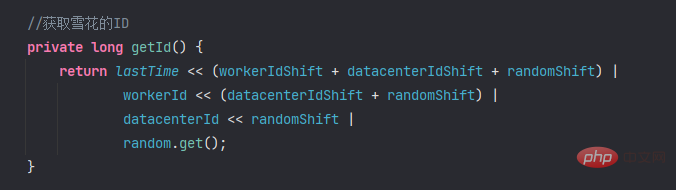
//获取雪花的ID
private long getId() {
return lastTime << (workerIdShift + datacenterIdShift + randomShift) |
workerId << (datacenterIdShift + randomShift) |
datacenterId << randomShift |
random.get();
}
//生成一个新的ID
public synchronized long nextId() {
long now = System.currentTimeMillis();
//如果当前时间和上一次时间不在同一毫秒内,直接返回
if (now > lastTime) {
lastTime = now;
random.set(0);
return getId();
}
//将最后的随机数,进行+1操作
if (random.incrementAndGet() < maxRandom) {
return getId();
}
//自选等待下一毫秒
while (now <= lastTime) {
now = System.currentTimeMillis();
}
lastTime = now;
random.set(0);
return getId();
}
//测试
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake();
HashSet<Long> set = new HashSet<>();
for (int i = 0; i < 10000; i++) {
set.add(snowFlake.nextId());
}
System.out.println(set.size());
}
}코드에서 ID를 얻는 방법은 비트 연산을 사용하여 구현됩니다
1 12
0|0001100 10100010 10111110 10001001 01011100 00|00000| 0 0000|0000 00000000 //41자리 시간
0|0000000 000000 00 00000000 00000000 00000000 00|10001|0 0000|0000 00000000 //5자리 데이터 센터 ID
0|0000000 00000000 00000000 00000000 00000000 00| 00000|1 1001|0000 00000000 //5비트 머신 ID
또는 0|0000000 00000000 00000000 00000000 00000000 00|00000|0 0000|0000 00000000 //12자리 시퀀스
--------- ---------------------------- ---------- ---------------------
0|0001100 10100010 10111110 10001001 01011100 00|10001|1 1001| 0000 00000000 //결과: 910499571847892992
SnowFlake 장점:
생성된 모든 ID는 시간 추세에 따라 증가합니다. s는 전체 분산 시스템에서 생성됩니다(왜냐하면 datacenterId 및 작업자 ID 구분) SnowFlake 단점:
SnowFlake는 타임스탬프에 크게 의존하므로 시간이 변경되면 SnowFlake 알고리즘에 오류가 발생합니다.
위 내용은 Java에서 손으로 쓴 분산 눈송이 SnowFlake를 통해 ID를 생성하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!