
Python 내장형 dict 소스코드 분석

- 王林앞으로
- 2023-04-24 12:01:071881검색
Python 내장 유형에 대한 심층적인 이해 - dict
참고: 이 문서는 튜토리얼에 기록된 메모를 기반으로 합니다. 재인쇄하려면 링크를 작성해야 하기 때문에 일부 내용은 튜토리얼과 동일합니다. 아니오이므로 원본을 기재하여 침해사항이 있는 경우 바로 삭제됩니다.
"Python의 내장 유형에 대한 심층적 이해" 콘텐츠에서는 Python에서 일반적으로 사용되는 다양한 내장 유형을 소스 코드 관점에서 소개합니다.
Dict는 일상적인 개발에서 가장 일반적으로 사용되는 내장 유형 중 하나이며 Python 가상 머신의 작동도 dict 개체에 크게 의존합니다. 데이터 구조에 대한 기본 지식을 이해하든, 개발 효율성을 높이든, dict에 대한 기본 지식을 익히는 것이 도움이 될 것입니다.
1 실행 효율성
Java의 Hashmap이든 Python의 dict이든 둘 다 매우 효율적인 데이터 구조입니다. 해시맵은 Java 인터뷰의 기본 테스트 지점이기도 합니다. 배열 + 연결 목록 + 레드-블랙 트리 해시 테이블은 시간 효율적입니다. 마찬가지로 Python의 dict도 기본 해시 테이블 구조로 인해 삽입, 삭제 및 검색과 같은 작업에 대해 O(1)(최악의 경우 O(n))의 평균 복잡도를 갖습니다. 여기서는 list와 dict를 비교하여 둘 사이의 검색 효율성에 얼마나 큰 차이가 있는지 확인합니다. (데이터는 원본 기사에서 가져온 것이므로 직접 테스트할 수 있습니다.)
| Container scale | Scale 성장 계수 | dict 시간 소비 | dict 시간 소비 성장 계수 | 목록 시간 소비 성장 계수 | 목록 시간 소비 성장 계수 |
|---|---|---|---|---|---|
| 1000 | 1 | 0.000129s | 1 | 0.036s | 1 |
| 10000 | 10 | 0.000172s | 1.33 | 0.348s | 9.67 |
| 100000 | 100 | 0.000216s | 1.67 | 3.679s | 102.19 |
| 1000000 | 1000 | 0.000382s | 2.96 | 48.044s | 1335.56 |
생각: 여기 원문에서는 검색할 데이터를 목록의 요소와 dict의 키로 비교하고 있습니다. 개인적으로 이런 비교는 의미가 없다고 생각합니다. 목록은 본질적으로 키가 0에서 n-1이고 값이 우리가 찾고 있는 요소이고 여기의 dict는 우리가 찾고 있는 요소를 키로 사용하고 값이 True인 해시 테이블이기 때문입니다. 원본 기사의 코드는 다음과 같이 설정되어 있습니다.) 정말 비교하고 싶다면 쿼리 목록의 0~n-1과 쿼리 dict의 해당 키를 비교하면 됩니다. 이것이 제어변수 방식인 hh입니다. 물론 개인적으로 여기서 부적절하다고 느끼는 근본적인 이유는 list가 저장 의미를 갖는 곳이 값 부분이고 dict의 키와 값 모두 특정 저장 의미를 갖고 있기 때문입니다. 개인적으로는 크게 걱정할 필요가 없다고 생각합니다. 둘의 검색 효율성에 대해서는 둘의 기본 원리를 이해하고 실제 프로젝트에 적용하는 것이 가장 중요합니다. 思考:这里原文章是比较的将需要搜索的数据分别作为list的元素和dict的key,个人认为这样的比较并没有意义。因为本质上list也是哈希表,其中key是0到n-1,值就是我们要查找的元素;而这里的dict是将要查找的元素作为key,而值是True(原文章中代码是这样设置的)。如果真要比较可以比较下查询list的0~n-1和查询dict的对应key,这样才是控制变量法,hh。当然这里我个人觉得不妥的本质原因是:list它有存储意义的地方是它的value部分,而dict的key和value都有一定的存储意义,个人认为没必要过分纠结这两者的搜索效率,弄清楚二者的底层原理,在实际工程中选择运用才是最重要的。
2 内部结构
2.1 PyDictObject
由于关联式容器使用的场景非常广泛,几乎所有现代编程语言都提供某种关联式容器,而且特别关注键的搜索效率。例如C++标准库中的map就是一种关联式容器,其内部基于红黑树实现,此外还有刚刚提到的Java中的Hashmap。红黑树是一种平衡二叉树,能够提供良好的操作效率,插入、删除、搜索等关键操作的时间复杂度都是O(logn)。
Python虚拟机的运行重度依赖dict对象,像名字空间、对象属性空间等概念的底层都是由dict对象来管理数据的。因此,Python对dict对象的效率要求更为苛刻。于是,Python中的dict使用了效率优于O(logn)的哈希表。
dict对象在Python内部由结构体PyDictObject表示,源码如下:
typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;源码分析:
ma_used:对象当前所保存的键值对个数
ma_version_tag:对象当前版本号,每次修改时更新(版本号感觉在业务开发中也挺常见的)
ma_keys:指向由键对象映射的哈希表结构,类型为PyDictKeysObject
ma_values:splitted模式下指向所有值对象组成的数组(如果是combined模式,值会存储在ma_keys中,此时ma_values为空)
2.2 PyDictKeysObject
从PyDictObject的源码中可以看到,相关的哈希表是通过PyDictKeysObject来实现的,源码如下:
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
/* Size of the hash table (dk_indices). It must be a power of 2. */
Py_ssize_t dk_size;
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception.
- lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR.
- lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the <dummy> value.
- lookdict_split(): Version of lookdict() for split tables. */
dict_lookup_func dk_lookup;
/* Number of usable entries in dk_entries. */
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, SIZEOF_VOID_P is minimum. */
char dk_indices[]; /* char is required to avoid strict aliasing. */
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};源码分析:
dk_refcnt:引用计数,和映射视图的实现有关,类似对象引用计数
-
dk_size:哈希表大小,必须是2的整数次幂,这样可以将模运算优化成位运算(
可以学习一下,结合实际业务运用2 내부 구조
2.1 PyDictObject - 연관 컨테이너의 광범위한 사용 시나리오로 인해 거의 모든 최신 프로그래밍 언어는 키 검색에 특별한 주의를 기울여 일종의 연관 컨테이너를 제공합니다. 능률. 예를 들어 C++ 표준 라이브러리의 맵은 레드-블랙 트리를 기반으로 내부적으로 구현되는 연관 컨테이너입니다. 또한 방금 언급한 Java의 Hashmap도 있습니다. 레드-블랙 트리는 삽입, 삭제, 검색 등 핵심 연산의 시간복잡도가 O(logn)으로 좋은 연산 효율성을 제공할 수 있는 균형 이진 트리이다.
- Python 가상 머신의 작동은 dict 객체에 크게 의존합니다. 네임스페이스 및 객체 속성 공간과 같은 기본 개념은 dict 객체를 사용하여 데이터를 관리합니다. 따라서 Python에는 dict 객체에 대한 효율성 요구 사항이 더 엄격합니다. 따라서 Python의 dict는 O(logn)보다 효율성이 뛰어난 해시 테이블을 사용합니다.
- dict 객체는 Python 내부의 PyDictObject 구조로 표현됩니다. 소스 코드는 다음과 같습니다.
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;- ma_keys: 주요 개체에 매핑된 해시 테이블 구조를 가리키며 유형은 PyDictKeysObject
- ma_values: 분할 모드에서 모두를 가리킴 값 개체의 배열(결합 모드인 경우 값은 ma_keys에 저장되며, 이때 ma_values는 비어 있음)
- 2.2 PyDictKeysObject최대한 PyDictObject의 소스 코드를 보면, 관련 해시 테이블은 PyDictKeysObject Implemented를 통해 얻어지며, 소스 코드는 다음과 같습니다.
>>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240소스 코드 분석:
dk_refcnt: 매핑 뷰 구현과 관련된 참조 카운팅, 객체 참조 카운팅과 유사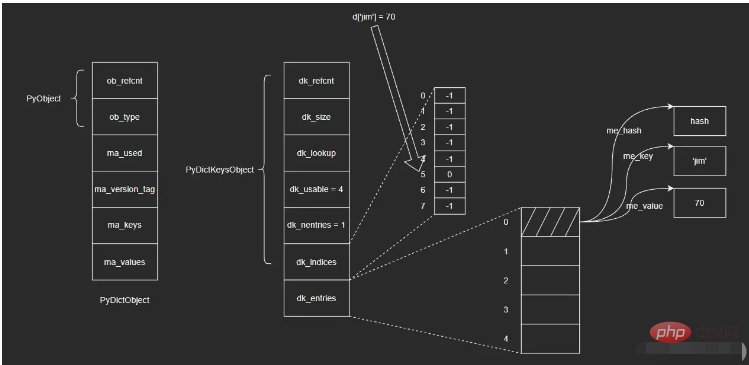
dk_size: 해시 테이블 크기는 2의 정수 거듭제곱이어야 하며 모듈 연산을 비트 연산으로 최적화할 수 있습니다(학습하여 실제 비즈니스 애플리케이션과 결합할 수 있음 )
dk_lookup: 해시 검색 함수 포인터, dict
의 현재 상태에 따라 최적의 함수를 선택할 수 있습니다.
dk_usable: 사용 가능한 키-값 쌍 배열 수
dk_nentries: 사용된 수 키-값 쌍 배열
🎜dk_indices: 해시 테이블의 시작 주소, 그 뒤에 키-값 쌍 배열 dk_entries가 옵니다. DK_ENTRIES의 유형은 PydictKeysObject의 pydictKeyentry🎜🎜🎜🎜2.3 PydictKeyentry🎜🎜입니다. 반복 계산 방지 🎜🎜🎜🎜me_key: 키 개체 포인터 🎜🎜🎜🎜me_value: 값 개체 포인터 🎜🎜🎜🎜2.4 그림 및 예 🎜🎜dict 내부의 해시 테이블은 다음과 같습니다. 🎜🎜🎜🎜🎜dict 객체는 두 개의 키 배열을 포함하는 PyDictKeysObject에 있습니다. 하나는 해시 인덱스 배열 dk_indices이고 다른 하나는 키-값 쌍 배열 dk_entries입니다. dict에 의해 유지되는 키-값 쌍은 선착순으로 키-값 쌍 배열에 저장되며 해시 인덱스 배열의 해당 슬롯은 배열의 키-값 쌍 위치를 저장합니다. 🎜🎜예를 들어 빈 dict 객체 d에 {'jim': 70}을 삽입하는 경우 단계는 다음과 같습니다. 🎜🎜i. dk_entries 배열 끝에 키-값 쌍을 저장합니다(여기서 배열은 처음에 비어 있고 끝은 배열 아래 첨자 "0" 위치입니다. 🎜🎜ii. 키 개체 'jim'의 해시 값을 계산하고 오른쪽 3비트를 가져옵니다(예: 모듈로 8, dk_indices 배열의 길이는 8입니다. 여기서 우리는 앞서 배열의 길이가 2제곱의 정수라고 언급했습니다. 모듈식 연산을 비트 연산으로 변환할 수 있습니다. 여기서는 오른쪽 3비트만 취할 수 있습니다. 이때 얻은 마지막 값은 5라고 가정합니다. dk_indices 배열의 첨자 5 위치에 🎜🎜iii가 삽입됩니다. dk_entries 배열의 키-값 쌍에 해당하는 첨자 "0"이 해시 인덱스 배열 dk_indices의 첨자 5 위치에 저장됩니다. 🎜🎜검색 작업을 수행합니다. 단계는 다음과 같습니다. 🎜🎜i. 키 개체 'jim'의 해시 값을 계산하고 올바른 3자리 숫자를 가져와 해시 인덱스 배열 dk_indices에서 키의 아래 첨자 5를 가져옵니다. 🎜🎜ii. 해시 인덱스 배열 dk_indices에서 아래 첨자 5가 있는 위치를 선택하고 거기에 저장된 값인 0을 가져옵니다. 이는 dk_entries 배열의 키-값 쌍 위치입니다.iii. 找到dk_entries数组下标为0的位置,取出值对象me_value。(这里我不确定在查找时会不会再次验证me_key是否为'jim',感兴趣的读者可以自行去查看一下相应的源码)
这里涉及到的结构比较多,直接看图示可能也不是很清晰,但是通过上面的插入和查找两个过程,应该可以帮助大家理清楚这里的关系。我个人觉得这里的设计还是很巧妙的,可能暂时还看不出来为什么这么做,后续我会继续为大家介绍。
3 容量策略
示例:
>>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240可以看到,dict和list在容量策略上有所不同,Python会为空dict对象也分配一定的容量,而对空list对象并不会预先分配底层数组。下面简单介绍下dict的容量策略。
哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种稀疏的表结构,越稀疏则性能越好。但是由于内存开销的制约,哈希表不可能无限度稀疏,需要在时间和空间上进行权衡。实践经验表明,一个1/3到2/3满的哈希表,性能是较为理想的——以相对合理的内存换取相对高效的执行性能。
为保证哈希表的稀疏程度,进而控制哈希冲突频率,Python底层通过USABLE_FRACTION宏将哈希表内元素控制在2/3以内。USABLE_FRACTION根据哈希表的规模n,计算哈希表可存储元素个数,也就是键值对数组dk_entries的长度。以长度为8的哈希表为例,最多可以保持5个键值对,超出则需要扩容。USABLE_FRACTION是一个非常重要的宏定义:
# define USABLE_FRACTION(n) (((n) << 1)/3)
此外,哈希表的规模一定是2的整数次幂,即Python对dict采用翻倍扩容策略。
4 内存优化
在Python3.6之前,dict的哈希表并没有分成两个数组实现,而是由一个键值对数组(结构和PyDictKeyEntry一样,但是会有很多“空位”)实现,这个数组也承担哈希索引的角色:
entries = [ ['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
]哈希值直接在数组中定位到对应的下标,找到对应的键值对,这样一步就能完成。Python3.6之后通过两个数组来实现则是出于对内存的考量。
-
由于哈希表必须保持稀疏,最多只有2/3满(太满会导致哈希冲突频发,性能下降),这意味着至少要浪费1/3的内存空间,而一个键值对条目PyDictKeyEntry的大小达到了24字节。试想一个规模为65536的哈希表,将浪费:
65536 * 1/3 * 24 = 524288 B 大小的空间(512KB)
为了尽量节省内存,Python将键值对数组压缩到原来的2/3(原来只能2/3满,现在可以全满),只负责存储,索引由另一个数组负责。由于索引数组indices只需要保存键值对数组的下标,即保存整数,而整数占用的空间很小(例如int为4字节),因此可以节省大量内存。
此外,索引数组还可以根据哈希表的规模,选择不同大小的整数类型。对于规模不超过256的哈希表,选择8位整数即可;对于规模不超过65536的哈希表,16位整数足以;其他以此类推。
对比一下两种方式在内存上的开销:
| 哈希表规模 | entries表规模 | 旧方案所需内存(B) | 新方案所需内存(B) | 节约内存(B) |
|---|---|---|---|---|
| 8 | 8 * 2/3 = 5 | 24 * 8 = 192 | 1 * 8 + 24 * 5 = 128 | 64 |
| 256 | 256 * 2/3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2/3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
5 dict中哈希表
这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。
5.1 哈希函数
根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作:
i. 哈希值在对象的整个生命周期内不能改变
ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同
满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是:
>>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键:
>>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等:
>>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。
5.2 哈希冲突
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
-
解决哈希冲突的常用方法有两种:
i. 链地址法(seperate chaining)
ii. 开放定址法(open addressing)
为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测:di是一个线性函数,如:di = 2 * i
平方探测:di是一个二次函数,如:di = i ^ 2
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下:
static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。
5.3 哈希攻击
Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章)
>>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182
>>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182
如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
-
产生上述问题的原因是:Python3.3之前的哈希算法只根据对象本身来计算哈希值,这样会导致攻击者很容易构建哈希值相同的key。于是,Python之后在计算对象哈希值时,会加盐。具体做法如下:
i. Python解释器进程启动后,产生一个随机数作为盐
ii. 哈希函数同时参考对象本身以及盐计算哈希值
这样一来,攻击者无法获知解释器内部的随机数,也就无法构造出哈希值相同的对象了。
5.4 删除操作
示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:
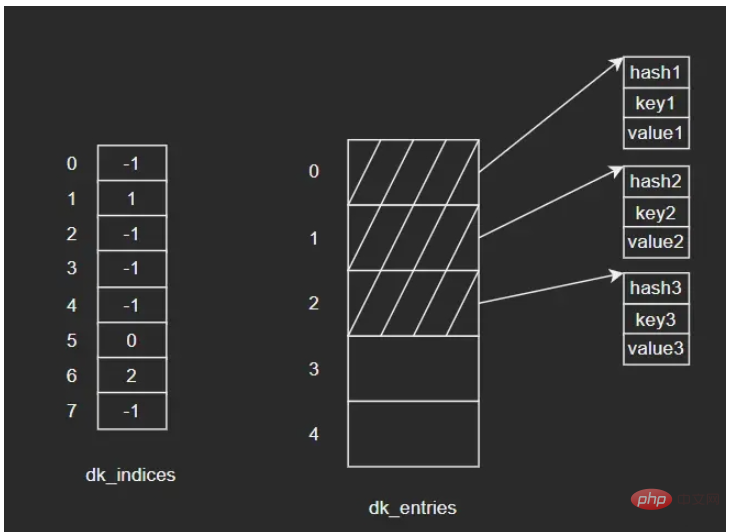
如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。
哈希槽位状态常量如下:
#define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
对于被删除元素在dk_entries中对应的存储单元,Python是不做处理的。假设此时再插入key4,Python会直接使用dk_entries[3],而不会使用被删除的key2所占用的dk_entries[1]。这里会存在一定的浪费。
5.5 问题
删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由GROWTH_RATE宏计算。这里给大家简单列下源码:
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析:
如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。
函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入:
#define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}这里的for循环就是不断对newsize进行翻倍变化,找到大于minsize的最小值
扩容时,Python分配新的哈希索引数组和键值对数组,然后将旧数组中的键值对逐一拷贝到新数组,再调整数组指针指向新数组,最后回收旧数组。这里的拷贝并不是直接拷贝过去,而是逐个插入新表的过程,这是因为哈希表的规模改变了,相应的哈希函数值对哈希表长度取模后的结果也会变化,所以不能直接拷贝。
위 내용은 Python 내장형 dict 소스코드 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!