
LeCun은 하드웨어 교체로 600달러짜리 GPT-3.5를 칭찬합니다! 스탠포드의 70억 매개변수 '알파카'가 인기를 끌고 있는데, LLaMA의 성능이 굉장하네요!

- 王林앞으로
- 2023-04-23 16:04:081147검색
정신을 차려보니 스탠포드의 대형모델 알파카가 인기를 끌더군요.

예, Alpaca는 Meta의 LLaMA 7B에서 미세 조정된 새로운 모델입니다. 52k 데이터만 사용하며 성능은 GPT-3.5와 거의 같습니다.
핵심은 교육 비용이 $600 미만으로 매우 낮다는 것입니다. 구체적인 비용은 다음과 같습니다.
80GB A100 8개를 3시간 동안 훈련한 비용은 100달러 미만입니다.
OpenAI API를 사용하여 생성한 데이터는 500달러입니다.
Stanford University의 컴퓨터 과학 부교수인 Percy Liang은 다음과 같이 말했습니다. GPT 3.5와 같은 유능한 교육 모델에 대한 투명성 부족/완전한 액세스 불가능으로 인해 이 중요한 분야에 대한 학문적 연구가 제한되었습니다. 알파카(LLaMA 7B + text-davinci-003)로 작은 발걸음을 내디뎠습니다.

다른 사람이 자신의 대형 모델로 새로운 결과를 얻은 것을 보고 Yann LeCun은 이를 미친 듯이 리트윗했습니다(홍보가 필요함). ㅋㅋㅋ
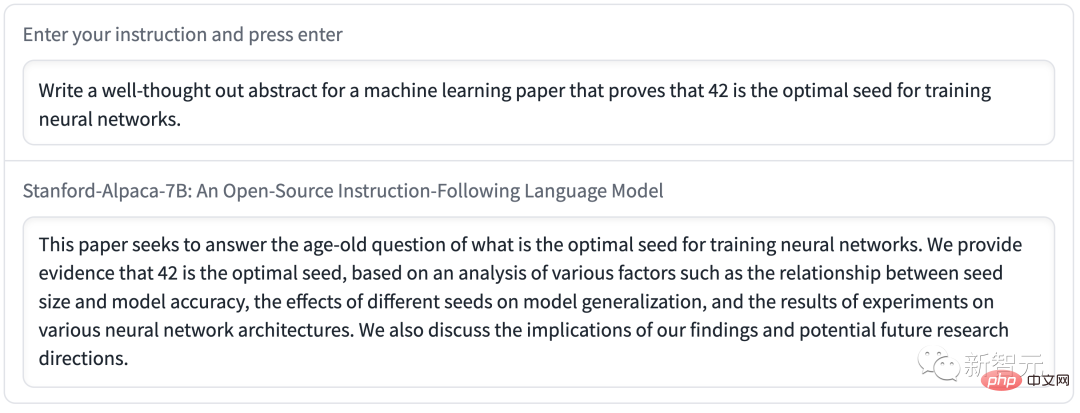
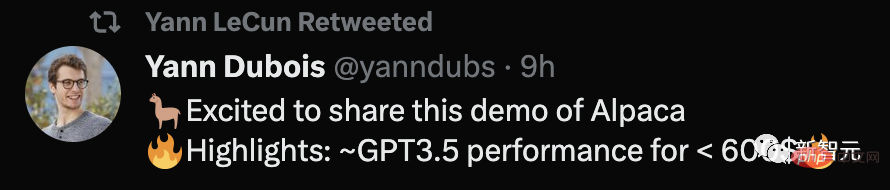 Q: 알파카에 대해 알려주세요.
Q: 알파카에 대해 알려주세요.

체험 링크: https://crfm.stanford.edu/alpaca/
예산 내에서 고품질 교육을 원하는 스탠포드 팀을 위해 모델을 따르면 강력한 사전 훈련된 언어 모델과 고품질 명령 준수 데이터라는 두 가지 중요한 과제에 직면해야 합니다.
바로, 학계 연구자에게 제공되는 LLaMA 모델이 첫 번째 문제를 해결했습니다.
두 번째 챌린지에서는 "Self-Instruct: Aligning Language Model with Self-Generated Instructions"라는 논문이 좋은 영감을 주었습니다. 즉, 기존의 강력한 언어 모델을 사용하여 자동으로 명령어 데이터를 생성하는 것입니다. 
그러나 LLaMA 모델의 가장 큰 약점은 지침 미세 조정이 부족하다는 것입니다. OpenAI의 가장 큰 혁신 중 하나는 GPT-3에서 명령어 튜닝을 사용하는 것입니다.
이와 관련하여 Stanford는 기존의 대규모 언어 모델을 사용하여 다음 지침의 데모를 자동으로 생성했습니다.

자체 생성 명령 시드 세트에서 사람이 작성한 175개의 "명령-출력" 쌍으로 시작한 다음 text-davinci-003이 해당 시드 세트를 상황별 예로 사용하여 더 많은 명령을 생성하도록 유도합니다.
생성 파이프라인을 단순화하여 자체 생성 명령 방법을 개선하여 비용을 크게 절감했습니다. 데이터 생성 프로세스 동안 52K개의 고유한 명령과 해당 출력이 생성되었으며 OpenAI API를 사용하여 500달러 미만의 비용이 소요되었습니다.
이 지시 따르기 데이터 세트를 사용하여 연구원들은 Hugging Face의 훈련 프레임워크를 사용하여 FSDP(완전 샤딩 데이터 병렬 처리) 및 혼합 정밀도 훈련과 같은 기술을 활용하여 LLaMA 모델을 미세 조정했습니다.
또한 7B LLaMA 모델을 미세 조정하는 데 8개의 80GB A100에서 3시간 이상이 걸렸고 대부분의 클라우드 제공업체에서 비용이 100달러 미만이었습니다.
GPT-3.5와 거의 동일
Alpaca를 평가하기 위해 Stanford 연구원들은 자체 생성된 교육 평가 세트의 입력에 대해 수동 평가(5명의 학생 저자가 수행)를 수행했습니다.
이 리뷰 모음은 자체 생성 지침 작성자가 수집했으며 이메일 작성, 소셜 미디어 및 생산성 도구를 포함하여 다양한 사용자 대상 지침을 다루고 있습니다.
GPT-3.5(text-davinci-003)와 Alpaca 7B를 비교한 결과 두 모델의 성능이 매우 유사하다는 것을 확인했습니다. 알파카는 GPT-3.5를 상대로 90대 89로 승리했습니다.
모델의 크기와 지시 데이터의 양이 적다는 점을 고려하면 이 결과는 이미 놀라운 것입니다.
이 정적 평가 세트를 활용하는 것 외에도 Alpaca 모델에 대한 대화형 테스트를 수행한 결과 Alpaca가 다양한 입력에서 GPT-3.5와 유사한 성능을 보이는 경우가 많다는 사실을 발견했습니다.
Alpaca를 사용하여 Stanford에서 실시한 데모:
Demo 1 Alpaca와 LLaMA의 차이점에 대해 이야기해 보세요.
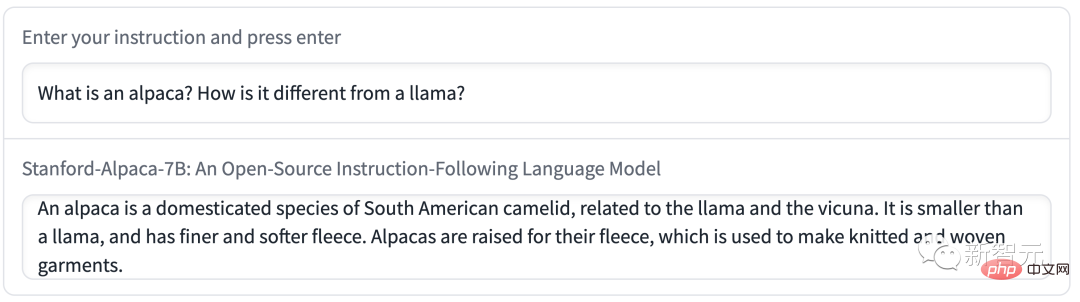
Demo 2에서는 알파카에게 이메일 작성을 요청했는데 내용은 간결하고 명확했으며 형식도 매우 표준적이었습니다.
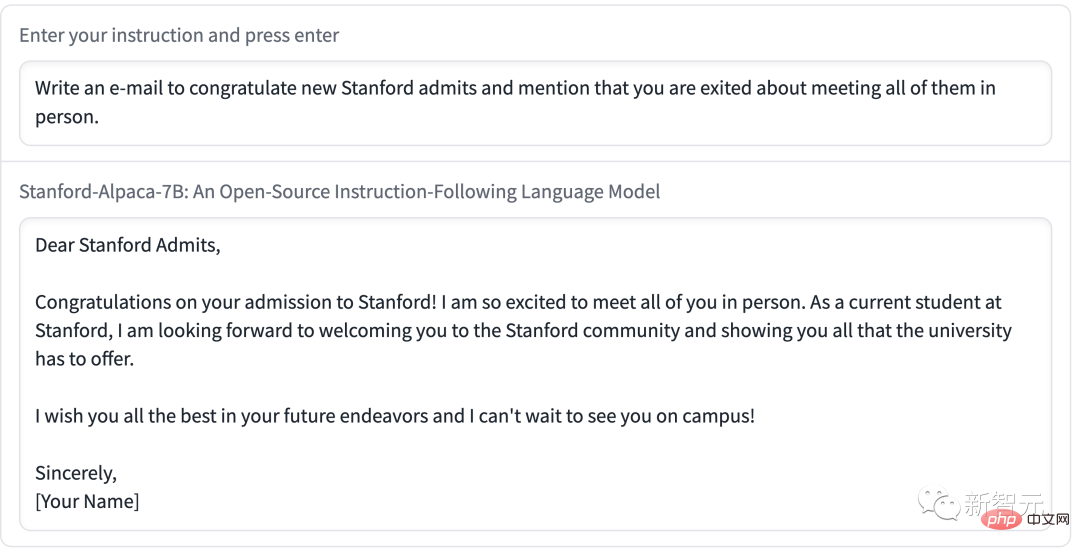
위의 예에서 볼 수 있듯이 Alpaca의 출력 결과는 일반적으로 잘 작성되었으며 답변은 일반적으로 GPT-3.5의 짧은 출력 스타일을 반영하여 ChatGPT보다 짧습니다.
물론 Alpaca는 언어 모델에 공통적인 결함을 나타냅니다.
예를 들어 탄자니아의 수도는 다르에스살람(Dar es Salaam)입니다. 실제로 1974년 이후 도도마는 탄자니아의 새로운 수도가 되었고, 다르에스살람은 탄자니아에서 가장 큰 도시에 불과했습니다.
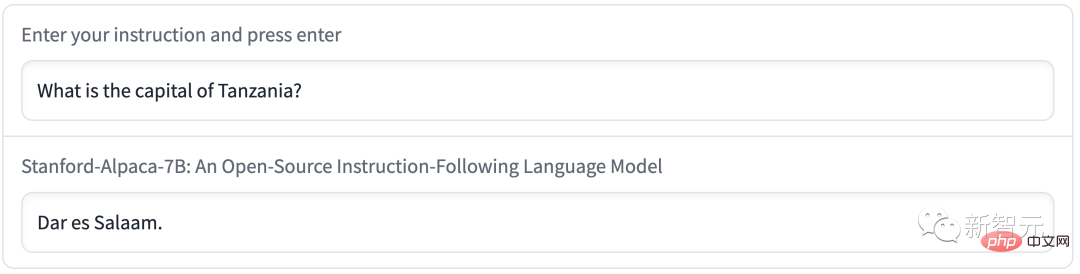
Alpaca는 사려 깊은 초록을 작성할 때 잘못된 정보를 퍼뜨립니다.
또한 Alpaca에는 기본 언어 모델 및 명령어 미세 조정 데이터와 관련하여 많은 제한 사항이 있을 수 있습니다. 그러나 Alpaca는 더 큰 모델의 중요한 결함에 대한 향후 연구의 기초를 형성할 수 있는 상대적으로 가벼운 모델을 제공합니다.
현재 스탠포드에서는 알파카의 훈련 방법과 데이터만 발표했으며, 향후 모델의 가중치를 공개할 계획입니다.
그러나 알파카는 상업적인 목적으로 사용할 수 없으며 학술 연구에만 사용할 수 있습니다. 세 가지 구체적인 이유가 있습니다:
1. LLaMA는 비상업적 라이센스 모델이며 Alpaca는 이 모델을 기반으로 생성됩니다.
2 명령 데이터는 OpenAI의 text-davinci를 기반으로 합니다. -003, 이는 OpenAI와 경쟁하는 모델의 개발을 금지합니다.
3. 보안 조치가 충분하지 않아 알파카는 널리 사용될 준비가 되어 있지 않습니다. 스탠포드 연구진 알파카에 대한 향후 연구 방향을 세 가지로 요약했다.
평가:
- HELM(언어 모델의 전체적 평가)으로 시작하여 보다 생성적이고 지시에 따르는 시나리오를 포착하세요.
보안:
- 자동화된 레드 팀 구성, 감사, 적응형 테스트와 같은 방법을 사용하여 Alpaca의 위험에 대한 추가 연구와 보안을 향상합니다.
이해:
- 학습 방법에서 모델 기능이 어떻게 발생하는지 더 잘 이해할 수 있기를 바랍니다. 기본 모델의 어떤 속성이 필요합니까? 모델을 확장하면 어떻게 되나요? 명령 데이터의 어떤 속성이 필요합니까? GPT-3.5에서 자체 생성 지시문을 사용하는 것에 대한 대안은 무엇입니까?
대형 모델의 안정적 확산이제 스탠포드 '알파카'는 네티즌들에게 직접적으로 '대형 텍스트 모델의 안정적 확산'으로 평가받고 있습니다.
Meta의 LLaMA 모델은 연구자들이 무료로(물론 신청 후) 사용할 수 있어 AI계에 큰 이점이 됩니다.
ChatGPT가 등장한 이후 많은 사람들이 AI 모델에 내재된 한계로 인해 좌절감을 느꼈습니다. 이러한 제한 사항은 ChatGPT가 OpenAI가 민감하다고 간주하는 주제를 논의하는 것을 방지합니다.
따라서 AI 커뮤니티는 OpenAI에 대한 검열이나 API 수수료 지불 없이 누구나 로컬에서 실행할 수 있는 오픈 소스 LLM(대형 언어 모델)을 갖기를 희망합니다.
이제 GPT-J 등 이런 오픈소스 대형 모델도 나와있지만 유일한 단점은 GPU 메모리와 저장공간을 많이 필요로 한다는 점입니다.
반면에 다른 오픈 소스 대안은 기성 소비자급 하드웨어에서 GPT-3 수준 성능을 달성할 수 없습니다.
2월 말 Meta는 매개변수 양이 70억(7B), 130억(13B), 330억(33B), 650억(65B)인 최신 언어 모델 LLaMA를 출시했습니다. 평가 결과는 13B 버전이 GPT-3과 유사한 것으로 나타났습니다.
논문 주소: https://research.facebook.com/publications/llama-open-and-efficient-foundation-언어-models/
Meta는 지원하는 연구자에게 오픈 소스이지만, 그런데 의외로 , 네티즌들은 먼저 GitHub에서 LLaMA의 무게를 유출했습니다.
그 이후로 LLaMA 언어 모델에 대한 개발이 폭발적으로 증가했습니다.
일반적으로 GPT-3을 실행하려면 여러 개의 데이터 센터급 A100 GPU가 필요하며 GPT-3의 가중치는 공개되지 않습니다.
네티즌들이 LLaMA 모델을 직접 운영하기 시작하며 센세이션을 일으켰습니다.
양자화 기술을 통해 모델 크기를 최적화한 LLaMA는 이제 M1 Mac, 더 작은 Nvidia 소비자 GPU, Pixel 6 휴대폰, 심지어 Raspberry Pi에서도 실행할 수 있습니다.
네티즌들은 LLaMA 출시부터 현재까지 모두가 LLaMA를 사용하여 만들어낸 결과 중 일부를 요약했습니다.
2월 24일 LLaMA가 출시되어 비공식적으로 정부와 정부에 제공되었습니다.
3월 2일에 4chan 네티즌들이 전체 LLaMA 모델을 유출했습니다. 3월 10일에 Georgi Gerganov가 llama.cpp 도구를 만들었습니다. M1/M2 칩이 장착된 Mac에서 LLaMA를 실행할 수 있습니다.
3월 11일: llama.cpp를 통해 4GB RaspberryPi에서 7B 모델을 실행할 수 있지만 속도는 토큰당 10초로 비교적 느립니다.
3월 12일: LLaMA 7B가 node.js 실행 도구 NPX에서 성공적으로 실행되었습니다.3월 13일: llama.cpp가 Pixel 6 휴대폰에서 실행될 수 있습니다.
그리고 이제 Stanford Alpaca " 알파카'가 출시됐다.
한 가지 더
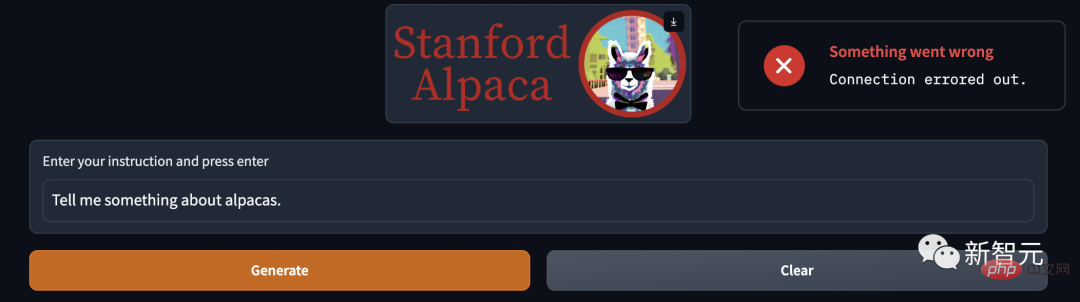
프로젝트가 공개된 지 얼마 지나지 않아 알파카는 더 이상 사용할 수 없을 정도로 인기를 얻었고....
많은 네티즌들이 떠들썩했고, "생성"을 클릭해도 응답이 없습니다. 일부는 플레이를 위해 줄을 서서 기다리고 있습니다.
위 내용은 LeCun은 하드웨어 교체로 600달러짜리 GPT-3.5를 칭찬합니다! 스탠포드의 70억 매개변수 '알파카'가 인기를 끌고 있는데, LLaMA의 성능이 굉장하네요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!