



Midjourney v5 출시 이후 생성된 이미지의 문자 및 손가락 디테일의 현실감이 크게 향상되었으며 신속한 이해의 정확성, 미적 다양성 및 언어 이해에서도 진전이 이루어졌습니다.
반면 Stable Diffusion은 무료이며 오픈 소스이지만 매번 긴 프롬프트 목록을 작성해야 하며 고품질 이미지 생성은 여러 번 드로잉 카드에 따라 달라집니다.

최근 Stability AI는 개발 중인 Stable Diffusion XL이 대중을 대상으로 테스트를 시작했으며 현재 Clipdrop 플랫폼에서 무료 평가판을 사용할 수 있다고 공식 발표했습니다.

평가판 링크: https://clipdrop.co/stable-diffusion
Stability AI 창립자이자 CEO인 Emad Mostaque는 이 모델이 아직 훈련 단계에 있다고 말했습니다. 매개변수가 안정된 후 오픈 소스로 제공되며 SD-XL은 "악수"와 같은 이미지 세부 사항에서 더 나은 성능을 발휘하며 거의 완벽하게 제어할 수 있습니다.

Stable Diffusion XL은 최종 출시 버전의 이름도 아니고 v3도 아닙니다. SD-XL의 아키텍처가 SD-v2 시리즈의 모델 아키텍처와 매우 유사하기 때문입니다. ㅋㅋㅋ 홈짐, 고무바닥, 벽걸이형 TV, 웨이트벤치, 메디신볼, 덤벨, 요가매트, 첨단장비, 하이디테일, 정리정돈 및 효율성

 때때로 일부 네티즌들은 SD-XL이 "나쁜 취향"을 없애기 위해 너무 많은 규칙을 설정했다고 생각합니다. 커스터마이징을 위한 공간은 점점 작아지고 있으며 대부분의 사람들의 선호도를 충족시키지 못합니다. 현재 v1.5인 Stable Diffusion은 여전히 커뮤니티에서 가장 인기 있는 기본 모델입니다.
때때로 일부 네티즌들은 SD-XL이 "나쁜 취향"을 없애기 위해 너무 많은 규칙을 설정했다고 생각합니다. 커스터마이징을 위한 공간은 점점 작아지고 있으며 대부분의 사람들의 선호도를 충족시키지 못합니다. 현재 v1.5인 Stable Diffusion은 여전히 커뮤니티에서 가장 인기 있는 기본 모델입니다.


일부 네티즌들은 SD-XL의 성능이 네티즌들이 시빗 홈페이지에서 공유한 모델과 유사하다고 생각하고 있으며, 새 모델의 효과는 특별히 놀랍지 않아 평균 수준입니다.


SD - 모델.
SD-v2.1에는 9억 개의 매개변수가 포함되어 있고, SD-XL에는 약 23억 개의 매개변수가 포함되어 있으며, Emad는 공식 버전이 더 작은 증류 버전을 추가로 출시할 수도 있다고 말했습니다.
SD-XL은 이전 버전에 비해 다음과 같은 개선 사항이 있습니다.
더 짧은 설명 프롬프트를 사용하여 고품질 이미지 생성
- 프롬프트에 더 잘 맞는 이미지 생성 가능
- images 의 인체 구조가 더 합리적입니다
- v2.1 및 v1.5 버전에 비해(적은 정도) SD-XL로 생성된 사진은 공공 미학에 더 부합합니다
- 부정 프롬프트 가능합니다 옵션
- 결과 인물 사진이 더 사실적으로 나옵니다.
- 이미지의 텍스트가 더 선명해졌습니다
- SD-XL은 이전 버전의 플러그인과 호환되지 않을 수 있습니다.
명확하고 읽기 쉬운 텍스트
v1 시리즈 및 v2.1 버전의 Stable Diffusion 모델에서는 이미지에서 읽을 수 있는 텍스트를 생성하는 기능이 없습니다.
SD-XL에서 생성된 텍스트 정보가 항상 정확하지는 않지만 상당한 개선을 제공합니다.

라는 표지판을 들고 있는 남자의 사진 “라고 말한다 안정확산”
"안정확산"이라고 적힌 팻말을 들고 있는 젊은 여성, 머리카락에 하이라이트, 식당 밖에 앉아 있음, 갈색 눈, 드레스를 입고, 측면 조명
Liang, 밖에 앉아 있음 레스토랑, 갈색 눈, 치마 착용, 측면 조명
더 나은 인체 구조
안정적인 확산은 인체 해부학을 생성하는 데 항상 많은 문제가 있었으며, 다리가 많고, 팔이 적다는 것은 매우 일반적인 문제이며 일반적으로 이미지 세부 사항을 추가로 수정하기 위해 inpaint 기능을 사용하거나 ControlNet의 Open Pose 기능을 사용하여 참조 이미지에서 인체의 자세를 복사하는 데 필요합니다.예를 들어 SD-v1.5가 요가 이미지를 생성하면 왜곡된 인체가 자주 등장합니다.
요가 복장, 삼각형 자세, 저녁 해변, 림 조명을 입은 여성의 사진

SD-XL로 생성된 이미지는 완벽하지는 않지만 인간의 자세에 있어서 상당한 발전을 이루었습니다.

더 심미적입니다
예를 들어, 집이라는 동일한 테마로 SD-XL은 더 대칭적이고 더 나은 시각 효과를 갖는 사진을 생성할 수 있습니다.

SD-XL은 인물 사진에서도 상당한 개선이 이루어졌습니다.

여성의 사진
프롬프트에 더 잘 맞는 이미지
, 더욱 정확한 이미지를 연출합니다.
예를 들어 이중톤(2색)을 예로 들면 SD-v1.5는 흑백 이미지만 생성하는 반면 SD-XL은 여러 색상의 이중톤 이미지를 생성할 수 있습니다.
v1 모델에 비해 프롬프트 이해 능력이 향상되었습니다.
duotone Portrait of a Woman
Duotone Portrait of a Woman
SD-XL은 동일한 v2 시리즈 모델에 속하기 때문에 텍스트 모델 크기가 더 크고 더 클 수 있습니다. v1 모델과 비교하여 프롬프트 단어를 더 잘 이해합니다.
예를 들어 아래 예에서 v1.5 모델은 이미지의 두 피사체(로봇과 인간)를 결코 이해할 수 없지만 SD-XL 모델은 일반 이미지를 생성할 수 있습니다(로봇은 아직 충분히 크지 않습니다.)

인간 옆에 앉아 있는 큰 로봇 친구, 껍데기 스타일의 유령, 애니메이션 배경화면
인간 옆에 앉아 있는 큰 로봇 친구, 껍데기 스타일의 유령, 애니메이션 배경화면
젊은 남자, 하이라이트 머리, 갈색 눈, 흰 셔츠와 청바지를 입고 화산을 배경으로 해변에서
젊은 남자, 하이라이트 머리, 갈색 눈, 화산을 배경으로 해변에 있는 흰색 셔츠와 청바지 화산을 배경으로 해변에 서 있는 흰색 셔츠와 청바지
아트 스타일
아트 스타일로 보면 SD-XL 크게 개선되지는 않았으며 이전 버전과의 차이점도 있습니다.
예를 들어, 두 모델은 서로 다른 각도에서 에드워드 호퍼 스타일의 이미지를 생성합니다.

Edward Hopper의 뉴욕시
Edward Hopper가 뉴욕을 그립니다
Leonid Afmov 스타일, SD-v1.5가 더 정확함, SD-XL에는 다양한 색상의 브러시가 없음 다채로운 보드 브러시 스트로크).

Leonid Afremov의 뉴욕시
Leonid Afemov
William-Adolphe Bouguereau 스타일로 그린 뉴욕, V1.5와 SDXL 모두 유사한 콘텐츠를 생성할 수 있습니다. 중 SD-XL은 Bouguereau가 만든 고전적인 학문적 그림에 더 가깝고 얼굴 세부 묘사가 더 많습니다. William-Adolphe Bouguereau의 아름다운 여인의 초상 관련 없는 키 추가 작성 후 모델의 스타일이 갑자기 바뀔 수 있습니다.

젊은 남자, 하이라이트 머리, 갈색 눈, 흰 셔츠와 청바지를 입고 화산을 배경으로 해변에서
젊은 남자, 하이라이트 머리, 갈색 눈, 흰색 셔츠와 청바지를 입고 화산을 배경으로 해변에서 눈, 흰색 셔츠와 청바지를 입고 화산을 배경으로 해변에 서 있음
노란색 스카프를 추가하면 이미지 스타일이 만화가 됩니다 스타일.

노란색 스카프 착용,흰색 셔츠와 청바지를 입고 화산을 배경으로 해변에서
젊은 남자, 밝게 염색한 머리, 갈색 눈, 노란색 스카프 착용, 흰색 셔츠와 청바지 착용, 화산을 배경으로 한 해변에 서 있음
미공개 문제로 인한 오류일 수 있습니다. 정식 출시 전까지는 이 문제가 나중에 해결될 수 있을지 모르겠습니다.
위 내용은 Stable Diffusion-XL은 공개 베타 버전으로 공개되어 길고 번거로운 메시지가 표시되지 않습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

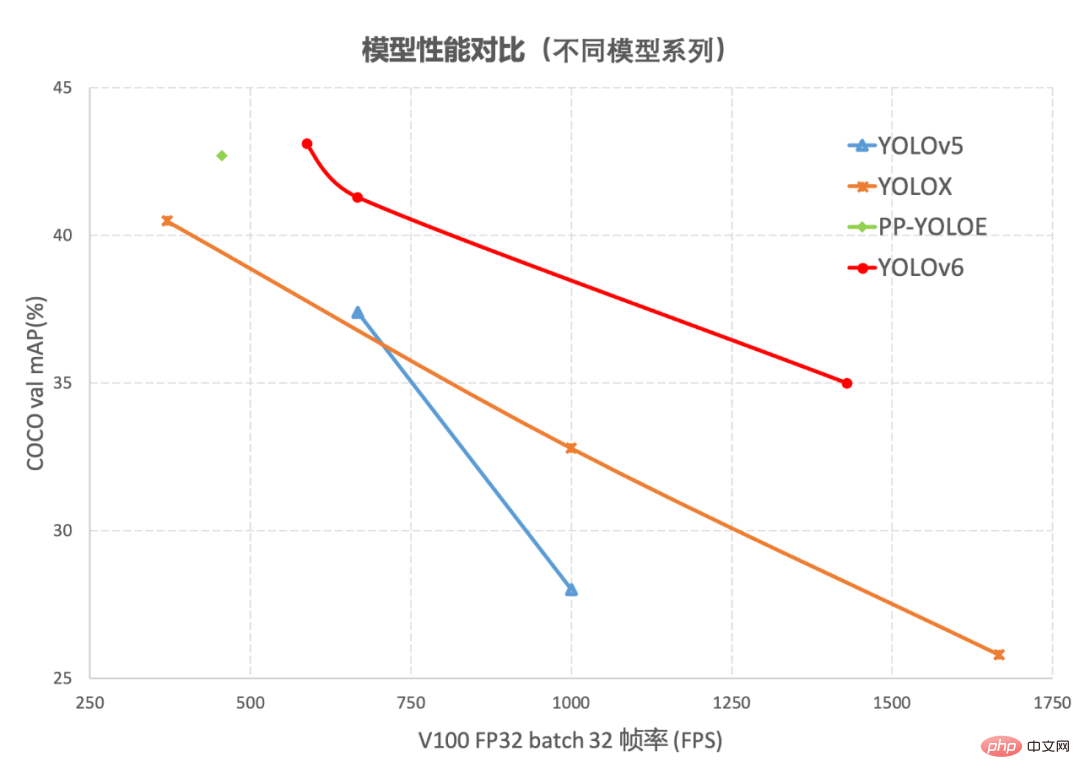 YOLOv6又快又准的目标检测框架已经开源了May 09, 2023 pm 02:52 PM
YOLOv6又快又准的目标检测框架已经开源了May 09, 2023 pm 02:52 PM作者:楚怡、凯衡等近日,美团视觉智能部研发了一款致力于工业应用的目标检测框架YOLOv6,能够同时专注于检测的精度和推理效率。在研发过程中,视觉智能部不断进行了探索和优化,同时吸取借鉴了学术界和工业界的一些前沿进展和科研成果。在目标检测权威数据集COCO上的实验结果显示,YOLOv6在检测精度和速度方面均超越其他同体量的算法,同时支持多种不同平台的部署,极大简化工程部署时的适配工作。特此开源,希望能帮助到更多的同学。1.概述YOLOv6是美团视觉智能部研发的一款目标检测框架,致力于工业应用。
 基于开源的 ChatGPT Web UI 项目,快速构建属于自己的 ChatGPT 站点Apr 15, 2023 pm 07:43 PM
基于开源的 ChatGPT Web UI 项目,快速构建属于自己的 ChatGPT 站点Apr 15, 2023 pm 07:43 PM作为一个技术博主,了不起比较喜欢各种折腾,之前给大家介绍过ChatGPT接入微信,钉钉和知识星球(如果没看过的可以翻翻前面的文章),最近再看开源项目的时候,发现了一个ChatGPTWebUI项目。想着刚好之前没有将ChatGPT接入过WebUI,有了这个开源项目可以拿来使用,真是不错,下面是实操的安装步骤,分享给大家。安装官方在Github的项目文档上提供了很多中的安装方式,包括手动安装,docker部署,以及远程部署等方法,了不起在选择部署方式的时候,一开始为了简单想着
 MLC LLM:开源AI聊天机器人,支持离线运行,适用于集成显卡电脑和iPhone。May 06, 2023 pm 03:46 PM
MLC LLM:开源AI聊天机器人,支持离线运行,适用于集成显卡电脑和iPhone。May 06, 2023 pm 03:46 PM5月2日消息,目前大多数AI聊天机器人都需要连接到云端进行处理,即使可以本地运行的也配置要求极高。那么是否有轻量化的、无需联网的聊天机器人呢?一个名为MLCLLM的全新开源项目已在GitHub上线,完全本地运行无需联网,甚至集显老电脑、苹果iPhone手机都能运行。MLCLLM项目介绍称:“MLCLLM是一种通用解决方案,它允许将任何语言模型本地部署在一组不同的硬件后端和本地应用程序上,此外还有一个高效的框架,供每个人进一步优化自己用例的模型性能。一切都在本地运行,无需服务器支持,并通过手机和笔
 仅需1% Embedding参数,硬件成本降低十倍,开源方案单GPU训练超大推荐模型Apr 12, 2023 pm 03:46 PM
仅需1% Embedding参数,硬件成本降低十倍,开源方案单GPU训练超大推荐模型Apr 12, 2023 pm 03:46 PM深度推荐模型(DLRMs)已经成为深度学习在互联网公司应用的最重要技术场景,如视频推荐、购物搜索、广告推送等流量变现业务,极大改善了用户体验和业务商业价值。但海量的用户和业务数据,频繁地迭代更新需求,以及高昂的训练成本,都对 DLRM 训练提出了严峻挑战。在 DLRM 中,需要先在嵌入表(EmbeddingBags)中进行查表(lookup),再完成下游计算。嵌入表常常贡献 DLRM 中 99% 以上的内存需求,却只贡献 1% 的计算量。借助于 GPU 片上高速内存(High Bandwidth
 用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统May 11, 2023 pm 07:25 PM
用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统May 11, 2023 pm 07:25 PM在人类的感官中,一张图片可以将很多体验融合到一起,比如一张海滩图片可以让我们想起海浪的声音、沙子的质地、拂面而来的微风,甚至可以激发创作一首诗的灵感。图像的这种「绑定」(binding)属性通过与自身相关的任何感官体验对齐,为学习视觉特征提供了大量监督来源。理想情况下,对于单个联合嵌入空间,视觉特征应该通过对齐所有感官来学习。然而这需要通过同一组图像来获取所有感官类型和组合的配对数据,显然不可行。最近,很多方法学习与文本、音频等对齐的图像特征。这些方法使用单对模态或者最多几种视觉模态。最终嵌入仅
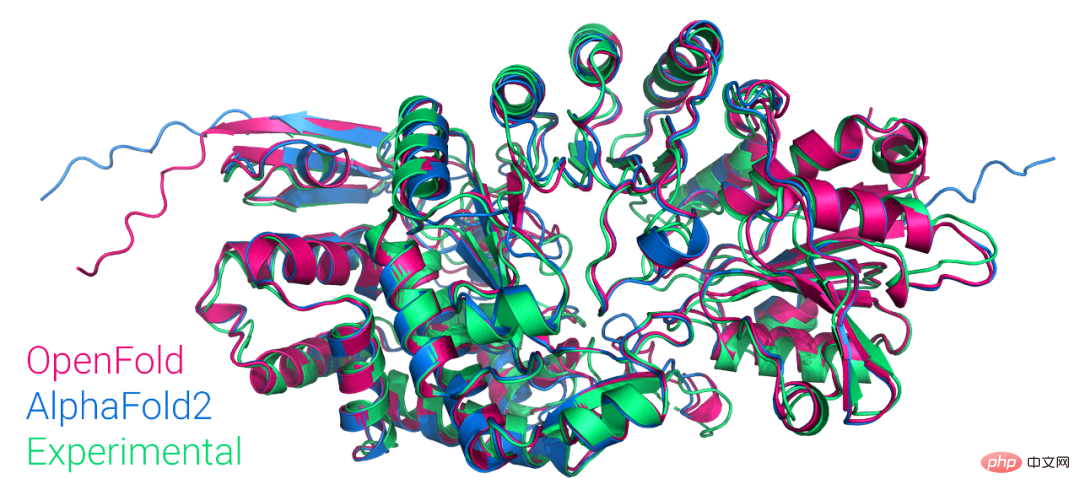 首个大众可用PyTorch版AlphaFold2复现,哥大开源,star量破千Apr 13, 2023 am 09:58 AM
首个大众可用PyTorch版AlphaFold2复现,哥大开源,star量破千Apr 13, 2023 am 09:58 AM刚刚,哥伦比亚大学系统生物学助理教授 Mohammed AlQuraishi 在推特上宣布,他们从头训练了一个名为 OpenFold 的模型,该模型是 AlphaFold2 的可训练 PyTorch 复现版本。Mohammed AlQuraishi 还表示,这是第一个大众可用的 AlphaFold2 复现。AlphaFold2 可以周期性地以原子精度预测蛋白质结构,在技术上利用多序列对齐和深度学习算法设计,并结合关于蛋白质结构的物理和生物学知识提升了预测效果。它实现了 2/3 蛋白质结构预测的卓
 Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!Apr 23, 2023 am 10:16 AM
Stable Diffusion-XL开启公测,让你摆脱繁琐的长prompt!Apr 23, 2023 am 10:16 AM自从Midjourney发布v5之后,在生成图像的人物真实程度、手指细节等方面都有了显著改善,并且在prompt理解的准确性、审美多样性和语言理解方面也都取得了进步。相比之下,StableDiffusion虽然免费、开源,但每次都要写一大长串的prompt,想生成高质量的图像全靠多次抽卡。最近StabilityAI的官宣,正在研发的StableDiffusionXL开始面向公众测试,目前可以在Clipdrop平台免费试用。试用链接:https://clipdrop.co/stable-diff
 伯克利开源首个泊车场景下的高清数据集和预测模型,支持目标识别、轨迹预测Apr 12, 2023 pm 11:40 PM
伯克利开源首个泊车场景下的高清数据集和预测模型,支持目标识别、轨迹预测Apr 12, 2023 pm 11:40 PM在自动驾驶技术不断迭代的当下,车辆的行为和轨迹预测对高效、安全驾驶有着极为重要的意义。动力学模型推演、可达性分析等传统的轨迹预测的方法虽然有着形式明晰、可解释性强的优点,但在复杂的交通环境中,其对于环境和物体交互的建模能力较为有限。因此,近年来大量研究和应用都基于各种深度学习方法(例如 LSTM、CNN、Transformer、GNN 等),各类数据集例如 BDD100K、nuScenes、Stanford Drone、ETH/UCY、INTERACTION、ApolloScape 等也纷纷涌现


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

드림위버 CS6
시각적 웹 개발 도구

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

