



코호트 분석
코호트 분석 개념
코호트는 말 그대로 다양한 성별, 연령 등 (공통의 특성이나 유사한 행동을 가진) 사람들의 집단을 의미합니다.
코호트 분석: 시간 경과에 따른 유사한 그룹의 변화를 비교합니다.
제품은 개발 및 테스트하면서 계속 반복되므로 제품 출시 첫 주에 가입하는 사용자와 나중에 가입하는 사용자가 서로 다른 경험을 하게 됩니다. 예를 들어, 각 사용자는 무료 평가판부터 유료 사용까지, 그리고 최종적으로 사용을 중단하는 수명 주기를 거치게 됩니다. 동시에, 이 기간 동안 귀하는 비즈니스 모델을 지속적으로 조정하고 있습니다. 따라서 제품 출시 후 첫 달에 '게를 먹는' 사용자는 4개월 후에 가입하는 사용자와 다른 온보딩 경험을 갖게 될 것입니다. 이것이 이탈률에 어떤 영향을 미치나요? 우리는 이를 알아보기 위해 코호트 분석을 사용했습니다.
각 사용자 그룹은 코호트를 형성하고 전체 평가판 과정에 참여합니다. 다양한 집단을 비교함으로써 주요 지표에 대한 전반적인 성과가 향상되고 있는지 확인할 수 있습니다.
다양한 달에 획득한 사용자, 다양한 채널의 신규 사용자, 다양한 특성을 가진 사용자(예: 매일 WeChat에서 최소 10명의 친구와 소통하는 WeChat 사용자)와 같은 사용자 분석 수준과 결합됩니다.
코호트 분석, 서로 다른 특성을 가진 이러한 그룹을 비교 분석하여 시간 차원에서 행동의 차이를 발견합니다.
따라서 코호트 분석은 주로 다음 두 가지 점에 사용됩니다.
제품 반복 최적화의 효과를 확인하기 위해 서로 다른 코호트 그룹의 동일한 경험 주기의 데이터 지표를 비교합니다.
다양한 경험 주기를 비교합니다( 동일한 코호트 그룹의 기간) 데이터 지표를 통해 장기적인 경험 문제 발견
코호트 분석을 수행할 때 크게 두 가지 프로세스로 나눌 수 있습니다. 코호트 그룹 결정 그룹화 논리 및 키 결정입니다. 코호트 분석의 데이터 지표 .
행동 특성이 비슷한 그룹
같은 기간의 그룹
예:
고객 확보 월별(주별 또는 일별 그룹화)
고객 확보 채널별
사용자가 웹사이트를 방문한 횟수, 구매 횟수 등 사용자가 완료한 특정 작업에 따라 분류됩니다.
핵심 데이터 지표는 보유, 수익, 자체 전파 계수 등과 같은 시간 차원을 기반으로 해야 합니다.
다음은 유지율을 지표로 사용한 사례입니다.
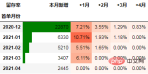
다음은 전자상거래 회사의 운영 데이터입니다. 이 데이터를 Python을 사용한 코호트 분석에 활용하겠습니다.
코호트 분석 사례에 대한 자세한 설명:
데이터는 전자상거래 사용자의 결제 로그이며 로그 필드에는 민감하지 않은 날짜, 결제 금액 및 사용자 ID가 포함됩니다.
데이터 읽기
import pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
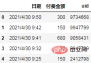
분석 방향
그룹 논리:
로그에 더 많은 분류 필드(예: 채널, 성별, 연령 등)가 포함된 경우에만 그룹화됩니다. , 더 많은 종류의 그룹화 논리를 고려할 수 있습니다.
주요 데이터 지표:
이 데이터에는 분석할 수 있는 데이터 지표가 3개 이상 있습니다:
유지율
1인당 결제 금액
-
1인당 구매 수
데이터 전처리
월별로 그룹화하기 때문에 먼저 날짜를 월 단위로 다시 샘플링해야 합니다.
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()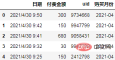
매월 각 사용자의 총 지불액 계산:
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()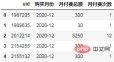
각 사용자 계산 첫 구매 월을 동일한 기간으로 그룹화하여 원본 데이터에 매핑:
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()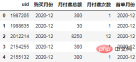
각 구매 기록 시점과 첫 구매 시점 간의 월 차이를 계산하고 월 차이 라벨 재설정:
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head() 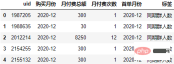
두 달 모두 기간 유형을 빼면 객체 유형의 열이 얻어지며 이 열의 각 요소 유형은 pandas._libs.tslibs.offsets.MonthEnd
MonthEnd 유형에는 n 속성이 있고 가능합니다. 특정 차이 정수를 반환합니다.
동일 코호트 분석
앞서 분석할 수 있는 데이터 지표가 3개 이상 있다고 말씀드렸습니다.
유지율
1인당 결제 금액
1인당 구매 수
从留存率角度进行同期群分析
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number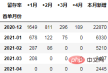
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
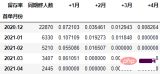
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1
至此计算完毕。
从人均付款金额角度进行同期群分析
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2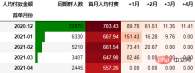
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
从人均购买次数角度进行同期群分析
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3
可以得到类似上述一致的结论。
每月总体付费情况
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)
可以看到总体付费人数和付费金额都在逐月下降。
将结果导出网页或截图
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
整体完整代码
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')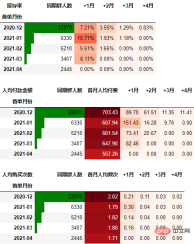
위 내용은 코호트 분석에 Python을 적용하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Python vs. C : 주요 차이점 이해Apr 21, 2025 am 12:18 AM
Python vs. C : 주요 차이점 이해Apr 21, 2025 am 12:18 AMPython과 C는 각각 고유 한 장점이 있으며 선택은 프로젝트 요구 사항을 기반으로해야합니다. 1) Python은 간결한 구문 및 동적 타이핑으로 인해 빠른 개발 및 데이터 처리에 적합합니다. 2) C는 정적 타이핑 및 수동 메모리 관리로 인해 고성능 및 시스템 프로그래밍에 적합합니다.
 Python vs. C : 프로젝트를 위해 어떤 언어를 선택해야합니까?Apr 21, 2025 am 12:17 AM
Python vs. C : 프로젝트를 위해 어떤 언어를 선택해야합니까?Apr 21, 2025 am 12:17 AMPython 또는 C를 선택하는 것은 프로젝트 요구 사항에 따라 다릅니다. 1) 빠른 개발, 데이터 처리 및 프로토 타입 설계가 필요한 경우 Python을 선택하십시오. 2) 고성능, 낮은 대기 시간 및 근접 하드웨어 제어가 필요한 경우 C를 선택하십시오.
 파이썬 목표에 도달 : 매일 2 시간의 힘Apr 20, 2025 am 12:21 AM
파이썬 목표에 도달 : 매일 2 시간의 힘Apr 20, 2025 am 12:21 AM매일 2 시간의 파이썬 학습을 투자하면 프로그래밍 기술을 효과적으로 향상시킬 수 있습니다. 1. 새로운 지식 배우기 : 문서를 읽거나 자습서를 시청하십시오. 2. 연습 : 코드를 작성하고 완전한 연습을합니다. 3. 검토 : 배운 내용을 통합하십시오. 4. 프로젝트 실무 : 실제 프로젝트에서 배운 것을 적용하십시오. 이러한 구조화 된 학습 계획은 파이썬을 체계적으로 마스터하고 경력 목표를 달성하는 데 도움이 될 수 있습니다.
 2 시간 극대화 : 효과적인 파이썬 학습 전략Apr 20, 2025 am 12:20 AM
2 시간 극대화 : 효과적인 파이썬 학습 전략Apr 20, 2025 am 12:20 AM2 시간 이내에 Python을 효율적으로 학습하는 방법 : 1. 기본 지식을 검토하고 Python 설치 및 기본 구문에 익숙한 지 확인하십시오. 2. 변수, 목록, 기능 등과 같은 파이썬의 핵심 개념을 이해합니다. 3. 예제를 사용하여 마스터 기본 및 고급 사용; 4. 일반적인 오류 및 디버깅 기술을 배우십시오. 5. 목록 이해력 사용 및 PEP8 스타일 안내서와 같은 성능 최적화 및 모범 사례를 적용합니다.
 Python과 C : The Hight Language 중에서 선택Apr 20, 2025 am 12:20 AM
Python과 C : The Hight Language 중에서 선택Apr 20, 2025 am 12:20 AMPython은 초보자 및 데이터 과학에 적합하며 C는 시스템 프로그래밍 및 게임 개발에 적합합니다. 1. 파이썬은 간단하고 사용하기 쉽고 데이터 과학 및 웹 개발에 적합합니다. 2.C는 게임 개발 및 시스템 프로그래밍에 적합한 고성능 및 제어를 제공합니다. 선택은 프로젝트 요구와 개인적인 이익을 기반으로해야합니다.
 Python vs. C : 프로그래밍 언어의 비교 분석Apr 20, 2025 am 12:14 AM
Python vs. C : 프로그래밍 언어의 비교 분석Apr 20, 2025 am 12:14 AMPython은 데이터 과학 및 빠른 개발에 더 적합한 반면 C는 고성능 및 시스템 프로그래밍에 더 적합합니다. 1. Python Syntax는 간결하고 학습하기 쉽고 데이터 처리 및 과학 컴퓨팅에 적합합니다. 2.C는 복잡한 구문을 가지고 있지만 성능이 뛰어나고 게임 개발 및 시스템 프로그래밍에 종종 사용됩니다.
 하루 2 시간 : 파이썬 학습의 잠재력Apr 20, 2025 am 12:14 AM
하루 2 시간 : 파이썬 학습의 잠재력Apr 20, 2025 am 12:14 AM파이썬을 배우기 위해 하루에 2 시간을 투자하는 것이 가능합니다. 1. 새로운 지식 배우기 : 목록 및 사전과 같은 1 시간 안에 새로운 개념을 배우십시오. 2. 연습 및 연습 : 1 시간을 사용하여 소규모 프로그램 작성과 같은 프로그래밍 연습을 수행하십시오. 합리적인 계획과 인내를 통해 짧은 시간에 Python의 핵심 개념을 마스터 할 수 있습니다.
 Python vs. C : 학습 곡선 및 사용 편의성Apr 19, 2025 am 12:20 AM
Python vs. C : 학습 곡선 및 사용 편의성Apr 19, 2025 am 12:20 AMPython은 배우고 사용하기 쉽고 C는 더 강력하지만 복잡합니다. 1. Python Syntax는 간결하며 초보자에게 적합합니다. 동적 타이핑 및 자동 메모리 관리를 사용하면 사용하기 쉽지만 런타임 오류가 발생할 수 있습니다. 2.C는 고성능 응용 프로그램에 적합한 저수준 제어 및 고급 기능을 제공하지만 학습 임계 값이 높고 수동 메모리 및 유형 안전 관리가 필요합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

Video Face Swap
완전히 무료인 AI 얼굴 교환 도구를 사용하여 모든 비디오의 얼굴을 쉽게 바꾸세요!

인기 기사
뜨거운 도구

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

안전한 시험 브라우저
안전한 시험 브라우저는 온라인 시험을 안전하게 치르기 위한 보안 브라우저 환경입니다. 이 소프트웨어는 모든 컴퓨터를 안전한 워크스테이션으로 바꿔줍니다. 이는 모든 유틸리티에 대한 액세스를 제어하고 학생들이 승인되지 않은 리소스를 사용하는 것을 방지합니다.

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

