
신경망의 해석 가능성 문제: 30년 전의 NN에 대한 비판 재검토

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-21 14:19:091382검색
1주차) 단순히 예측 점수를 산출하는 것보다 이러한 결정을 설명하는 것이 중요합니다.
설명 가능한 인공 지능(XAI)에 대한 연구는 최근 반사실적 예의 개념에 중점을 두고 있습니다. 아이디어는 간단합니다. 먼저 예상되는 출력으로 몇 가지 반사실적 예제를 생성하고 이를 원래 네트워크에 입력한 다음, 숨겨진 레이어 유닛을 읽어 네트워크가 다른 출력을 생성한 이유를 설명합니다. 더 공식적으로:
"변수 V에 연관된 값 (v1, v2, ...)이 있기 때문에 분수 p가 반환됩니다. V에 값 (v′1, v′2, ...)이 있는 경우 ), 다른 모든 변수를 일정하게 유지하면 점수 p'가 반환됩니다."
다음은 보다 구체적인 예입니다.
"연소득이 £30,000인 경우 대출이 거부됩니다. £45,000이면 대출을 받게 됩니다." 그러나 최근 Browne과 Swift[1](이하 B&W라고 함)의 논문에서는 반사실적 예가 약간 더 의미가 있음을 보여주었습니다. 예는 작고 관찰할 수 없는 섭동을 수행하여 생성됩니다. 입력에 대해 네트워크가 높은 신뢰도를 갖고 잘못 분류하게 만듭니다.
또한, 반사실적 예는 올바른 예측을 얻기 위해 일부 기능이 무엇인지 "설명"하지만 "블랙 박스를 열지 마십시오". 즉, 알고리즘 작동 방식을 설명하지 않습니다. 이 기사는 계속해서 반사실적 예가 해석 가능성에 대한 해결책을 제공하지 않으며 "의미 없이는 설명이 없다"고 주장합니다.
사실 이 기사는 더 강력한 제안을 제시합니다.
1) 네트워크의 숨겨진 레이어에 존재한다고 가정되는 의미를 추출하는 방법을 찾거나
2) 이를 인정합니다. 우리는 실패합니다.
그리고 Walid S. Saba 자신도 (1)에 대해 비관적입니다. 즉, 그는 우리의 실패를 유감스럽게 인정합니다.
2 만족스러운 설명에 대한 희망이 실현될 수 없는 이유가 바로 30여 년 전 Fodor와 Pylyshyn[2]이 설명한 이유 때문이라고 저자는 믿습니다.Walid S. Saba는 다음과 같이 주장했습니다. 문제가 어디에 있는지 설명하기 전에 순수 확장 모델(예: 신경망)은 파생 가능한 구문과 기호 구조를 인식하지 못하기 때문에 체계성과 구성성을 모델링할 수 없다는 점에 유의해야 합니다. 해당 의미론.
따라서 신경망의 표현은 실제로 해석 가능한 모든 것에 해당하는 "기호"가 아니라 개념적으로 위에 설명된 내용을 자체적으로 암시하지 않는 분산, 상관 및 연속 값입니다.
간단히 말하면, 신경망의 하위 기호 표현 자체는 인간이 개념적으로 이해할 수 있는 어떤 것도 참조하지 않습니다(숨겨진 단위 자체는 형이상학적 중요성을 지닌 객체를 나타낼 수 없습니다). 오히려 이는 일반적으로 일부 두드러진 특징(예: 고양이 수염)을 함께 나타내는 숨겨진 단위 세트입니다.
그러나 이것이 바로 신경망이 해석 가능성을 달성할 수 없는 이유입니다. 즉, 여러 숨겨진 기능의 조합을 결정할 수 없기 때문입니다. 일단 조합이 완료되면(일부 선형 조합 기능에 의해) 개별 단위가 손실됩니다(아래에 표시됩니다) ).
3 모듈[2].
기호 시스템에는 구성 요소의 의미를 기반으로 복합어의 의미를 계산하는 잘 정의된 구성 의미 함수가 있습니다. 하지만 이 조합은 가역적입니다.
즉, 출력을 생성한 (입력) 구성 요소에 항상 접근할 수 있으며, 정확하게 기호 시스템에서는 "구문 구조"에 접근할 수 있기 때문입니다. 이 구조에는 맵이 포함되어 있습니다. 부품을 조립하는 방법에 대해 설명합니다. NN에서는 이 중 어느 것도 사실이 아닙니다. 벡터(텐서)가 NN에 결합되면 분해를 결정할 수 없습니다(벡터(스칼라 포함)가 분해될 수 있는 방식은 무한합니다!)
이것이 문제의 핵심인 이유를 설명하기 위해 다음을 고려해 보겠습니다. 해석 가능성을 달성하기 위해 DNN에서 의미론을 추출하기 위한 흑백 제안. B&W의 제안은 다음 지침을 따르는 것입니다.
일반적으로 휠캡을 활성화하는 숨겨진 뉴런 41435의 활성화 값이 0.32이기 때문에 입력 이미지에 "Architecture"라는 레이블이 지정됩니다. 숨겨진 뉴런 41435의 활성화 값이 0.87이면 입력 이미지에 "car"라는 레이블이 지정됩니다.
이것이 해석 가능성으로 이어지지 않는 이유를 이해하려면 뉴런 41435에 0.87의 활성화를 요구하는 것만으로는 충분하지 않습니다. 단순화를 위해 뉴런 41435에는 x1과 x2라는 두 개의 입력만 있다고 가정합니다. 현재 우리가 가지고 있는 것은 아래 그림 1에 나와 있습니다:
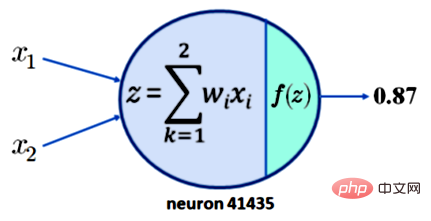
범례: 두 개의 입력을 가진 단일 뉴런의 출력은 0.87
이제 활성화 함수 f가 널리 사용되는 ReLU 함수라고 가정합니다. 그러면 z = 0.87의 출력이 생성될 수 있습니다. 이는 아래 표에 표시된 x1, x2, w1, w2 값에 대해 0.87의 출력이 얻어지는 것을 의미합니다.
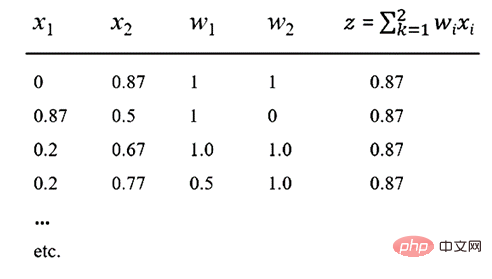
표 참고: 다양한 입력 방법으로 0.87
위 표를 보면 x1, x2, w1, w2의 수많은 선형 조합이 있음을 쉽게 알 수 있습니다. , 0.87의 출력을 생성합니다. 여기서 중요한 점은 NN의 구성성은 되돌릴 수 없으므로 어떤 뉴런이나 뉴런 모음에서도 의미 있는 의미를 포착할 수 없다는 것입니다.
B&W의 슬로건인 "의미 없음, 설명 없음"에 따라 NN에서는 어떠한 설명도 얻을 수 없음을 명시합니다. 즉, 구성성 없이는 의미론이 없고, 의미론 없이는 설명이 없으며, DNN은 구성성을 모델링할 수 없습니다. 이는 다음과 같이 공식화될 수 있습니다.
1. 의미 없이는 설명이 없습니다.[1] 2. 가역적 구성 없이는 의미가 없습니다.[2]
3 DNN의 구성은 되돌릴 수 없습니다.[2]
=> 설명할 수 없는 DNN(XAI 없이)
End.
그런데 DNN의 구성성이 되돌릴 수 없다는 사실은 특히 NLU(자연어 이해)와 같이 더 높은 수준의 추론이 필요한 분야에서 해석 가능한 예측을 생성할 수 없다는 것 외에도 결과를 초래합니다.
특히 이러한 시스템은 "John", "Neighbor Girl", "Always Dressed The boy" 때문에 (
이러한 시스템에는 "메모리"가 없고 그 구성을 되돌릴 수 없기 때문에 이론적으로 이 간단한 구조를 배우려면 셀 수 없이 많은 예가 필요합니다. [편집자 주: 이 점은 바로 구조적 언어학에 대한 촘스키의 의문이었고, 이로써 반세기 이상 언어학에 영향을 미친 변형적 생성 문법의 시작이었습니다. 】
마지막으로 저자는 30여년 전에 Fodor와 Pylyshyn[2]이 인지 아키텍처로서 NN에 대한 비판을 제기했음을 강조합니다. 그들은 NN이 모든 것에 대해 이야기하는 데 필요한 체계성, 생산성 및 구성성을 모델링할 수 없는 이유를 보여주었습니다. "의미론" - 이 설득력 있는 비판은 결코 완벽하게 답변된 적이 없습니다.
AI 설명 가능성 문제를 해결해야 할 필요성이 중요해짐에 따라 통계적 패턴 인식을 AI의 발전과 동일시하는 데 한계가 있기 때문에 고전 논문을 다시 방문해야 합니다.
위 내용은 신경망의 해석 가능성 문제: 30년 전의 NN에 대한 비판 재검토의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!