
희소 특성과 밀집 특성

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-21 11:19:081839검색
기계 학습에서 특징은 측정 가능하고 정량화 가능한 속성 또는 사물, 사람 또는 현상의 특성을 의미합니다. 특성은 크게 희소 특성과 밀집 특성의 두 가지 범주로 나눌 수 있습니다.
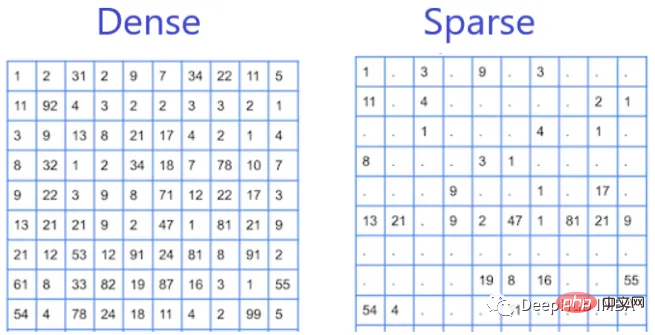
희소 특징
희소 특징은 데이터 세트에서 불연속적으로 나타나고 대부분의 값이 0인 특징입니다. 희소 특성의 예로는 텍스트 문서에 특정 단어가 있는지 또는 트랜잭션 데이터세트에 특정 항목이 있는지 등이 있습니다. 이는 데이터 세트에 0이 아닌 값이 거의 없고 대부분의 값이 0이기 때문에 희소 특성이라고 합니다.
희소 기능은 데이터가 종종 희소 행렬로 표현되는 자연어 처리(NLP) 및 추천 시스템에서 일반적입니다. 희소 특성을 사용하는 작업은 0 또는 0에 가까운 값이 많아 계산 비용이 많이 들고 훈련 프로세스가 느려지는 경우가 많기 때문에 더 어려울 수 있습니다. 희소 특성은 특성 공간이 크고 대부분의 특성이 관련이 없거나 중복될 때 효과적입니다. 이러한 경우 희소 기능은 데이터의 차원을 줄이는 데 도움이 되므로 더 빠르고 효율적인 훈련 및 추론이 가능합니다.
밀집된 특징
밀집된 특징은 데이터 세트에서 자주 또는 정기적으로 나타나는 특징이며, 대부분의 값은 0이 아닙니다. 밀집된 특성의 예로는 인구통계 데이터 세트에 있는 개인의 연령, 성별, 소득이 있습니다. 데이터 세트에 0이 아닌 값이 많이 있기 때문에 밀집 특성이라고 합니다.
밀집된 특징은 데이터가 밀집된 벡터로 표현되는 이미지 및 음성 인식에서 일반적입니다. 밀집된 특성은 일반적으로 0이 아닌 값의 밀도가 높기 때문에 처리하기가 더 쉽고 대부분의 기계 학습 알고리즘은 밀집된 특성 벡터를 처리하도록 설계되었습니다. 조밀한 기능은 기능 공간이 상대적으로 작고 각 기능이 현재 작업에 중요한 경우 더 적합할 수 있습니다.
Difference
희소 특성과 밀집 특성의 차이점은 데이터 세트에서 해당 값의 분포에 있습니다. 희소 특성에는 0이 아닌 값이 거의 없지만 밀도가 높은 특성에는 0이 아닌 값이 많이 있습니다. 분포의 이러한 차이는 기계 학습 알고리즘에 영향을 미칩니다. 왜냐하면 알고리즘은 밀도 특성에 비해 희소 특성에서 다르게 수행될 수 있기 때문입니다.
알고리즘 선택
이제 주어진 데이터 세트의 특징 유형을 알았으니, 데이터 세트에 희소 특징이 포함되어 있거나 데이터 세트에 조밀한 특징이 포함되어 있는 경우 어떤 알고리즘을 사용해야 합니까?
일부 알고리즘은 희소 데이터에 더 적합하고 다른 알고리즘은 밀도가 높은 데이터에 더 적합합니다.
- 희소 데이터의 경우 널리 사용되는 알고리즘에는 로지스틱 회귀, SVM(지원 벡터 머신) 및 의사결정 트리가 포함됩니다.
- 밀도가 높은 데이터의 경우 널리 사용되는 알고리즘에는 피드포워드 네트워크 및 컨볼루션 신경망과 같은 신경망이 포함됩니다.
그러나 알고리즘 선택은 데이터의 희소성이나 밀도뿐만 아니라 데이터 세트의 크기, 기능 유형, 문제의 복잡성 등과 같은 다른 요소에도 따라 달라집니다. 다양한 알고리즘을 시도하고 주어진 문제에 대한 성능을 비교합니다.
위 내용은 희소 특성과 밀집 특성의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!