
Python을 사용하여 PDF 파일을 일괄 처리하고 사용자 정의 키워드 발생 횟수를 계산하는 방법은 무엇입니까?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-20 16:10:181978검색
函数模块介绍
具体的代码可见全部代码部分,这部分只介绍思路和相应的函数模块
对文件进行批量重命名
因为文件名是中文,且无关于最后的结果,所以批量命名为数字
注意如果不是第一次运行,即已经命名完成,就在主函数内把这个函数注释掉就好了
def rename():
path='dealPdf'
filelist=os.listdir(path)
for i,files in enumerate(filelist):
Olddir=os.path.join(path,files)
if os.path.isdir(Olddir):
continue
Newdir=os.path.join(path,str(i+1)+'.pdf')
os.rename(Olddir,Newdir)将PDF转化为txt
PDF是无法直接进行文本分析的,所以需要将文字转成txt文件(PDF中图内的文字无法提取)
#将pdf文件转化成txt文件
def pdf_to_txt(dealPdf,index):
# 不显示warning
logging.propagate = False
logging.getLogger().setLevel(logging.ERROR)
pdf_filename = dealPdf
device = PDFPageAggregator(PDFResourceManager(), laparams=LAParams())
interpreter = PDFPageInterpreter(PDFResourceManager(), device)
parser = PDFParser(open(pdf_filename, 'rb'))
doc = PDFDocument(parser)
txt_filename='dealTxt\\'+str(index)+'.txt'
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
with open(txt_filename, 'w', encoding="utf-8") as fw:
#print("num page:{}".format(len(list(doc.get_pages()))))
for i,page in enumerate(PDFPage.create_pages(doc)):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性,
for x in layout:
if isinstance(x, LTTextBoxHorizontal):
results = x.get_text()
fw.write(results)删除txt中的换行符
因为PDF导出的txt会用换行符换行,为了避免词语因此拆开,所以删除所有的换行符
#对txt文件的换行符进行删除
def delete_huanhangfu(dealTxt,index):
outPutString=''
outPutTxt='outPutTxt\\'+str(index)+'.txt'
with open(dealTxt,'r',encoding="utf-8") as f:
lines=f.readlines()
for i in range(len(lines)):
if lines[i].endswith('\n'):
lines[i]=lines[i][:-1] #将字符串末尾的\n去掉
for j in range(len(lines)):
outPutString+=lines[j]
with open(outPutTxt,'w',encoding="utf-8") as fw:
fw.write(outPutString)添加自定义词语
此处可以根据自己的需要自定义,传入的wordsByMyself是全局变量
分词与词频统计
调用jieba进行分词,读取通用词表去掉停用词(此步其实可以省略,对最终结果影响不大),将词语和出现次数合成为键值对,输出关键词出现次数
#分词并进行词频统计
def cut_and_count(outPutTxt):
with open(outPutTxt,encoding='utf-8') as f:
#step1:读取文档并调用jieba分词
text=f.read()
words=jieba.lcut(text)
#step2:读取停用词表,去停用词
stopwords = {}.fromkeys([ line.rstrip() for line in open('stopwords.txt',encoding='utf-8') ])
finalwords = []
for word in words:
if word not in stopwords:
if (word != "。" and word != ",") :
finalwords.append(word)
#step3:统计特定关键词的出现次数
valuelist=[0]*len(wordsByMyself)
counts=dict(zip(wordsByMyself,valuelist))
for word in finalwords:
if len(word) == 1:#单个词不计算在内
continue
else:
counts[word]=counts.get(word,0)+1#遍历所有词语,每出现一次其对应值加1
for i in range(len(wordsByMyself)):
if wordsByMyself[i] in counts:
print(wordsByMyself[i]+':'+str(counts[wordsByMyself[i]]))
else:
print(wordsByMyself[i]+':0')主函数
通过for循环进行批量操作
if __name__ == "__main__":
#rename()
for i in range(1,fileNum+1):
pdf_to_txt('dealPdf\\'+str(i)+'.pdf',i)#将pdf文件转化成txt文件,传入文件路径
delete_huanhangfu('dealTxt\\'+str(i)+'.txt',i)#对txt文件的换行符进行删除,防止词语因换行被拆分
word_by_myself()#添加自定义词语
print(f'----------result {i}----------')
cut_and_count('outPutTxt\\'+str(i)+'.txt')#分词并进行词频统计,传入文件路径本地文件结构
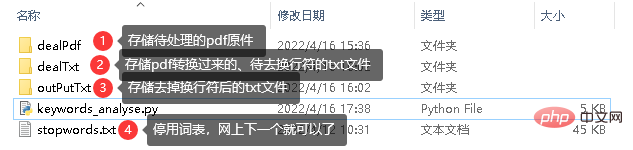
全部代码
import jieba
import jieba.analyse
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfpage import PDFPage,PDFTextExtractionNotAllowed
import logging
import os
wordsByMyself=['社会责任','义务','上市','公司'] #自定义词语,全局变量
fileNum=16#存储总共待处理的文件数量
#重命名所有文件夹下的文件,适应处理需要
def rename():
path='dealPdf'
filelist=os.listdir(path)
for i,files in enumerate(filelist):
Olddir=os.path.join(path,files)
if os.path.isdir(Olddir):
continue
Newdir=os.path.join(path,str(i+1)+'.pdf')
os.rename(Olddir,Newdir)
#将pdf文件转化成txt文件
def pdf_to_txt(dealPdf,index):
# 不显示warning
logging.propagate = False
logging.getLogger().setLevel(logging.ERROR)
pdf_filename = dealPdf
device = PDFPageAggregator(PDFResourceManager(), laparams=LAParams())
interpreter = PDFPageInterpreter(PDFResourceManager(), device)
parser = PDFParser(open(pdf_filename, 'rb'))
doc = PDFDocument(parser)
txt_filename='dealTxt\\'+str(index)+'.txt'
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
with open(txt_filename, 'w', encoding="utf-8") as fw:
#print("num page:{}".format(len(list(doc.get_pages()))))
for i,page in enumerate(PDFPage.create_pages(doc)):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性,
for x in layout:
if isinstance(x, LTTextBoxHorizontal):
results = x.get_text()
fw.write(results)
#对txt文件的换行符进行删除
def delete_huanhangfu(dealTxt,index):
outPutString=''
outPutTxt='outPutTxt\\'+str(index)+'.txt'
with open(dealTxt,'r',encoding="utf-8") as f:
lines=f.readlines()
for i in range(len(lines)):
if lines[i].endswith('\n'):
lines[i]=lines[i][:-1] #将字符串末尾的\n去掉
for j in range(len(lines)):
outPutString+=lines[j]
with open(outPutTxt,'w',encoding="utf-8") as fw:
fw.write(outPutString)
#添加自定义词语
def word_by_myself():
for i in range(len(wordsByMyself)):
jieba.add_word(wordsByMyself[i])
#分词并进行词频统计
def cut_and_count(outPutTxt):
with open(outPutTxt,encoding='utf-8') as f:
#step1:读取文档并调用jieba分词
text=f.read()
words=jieba.lcut(text)
#step2:读取停用词表,去停用词
stopwords = {}.fromkeys([ line.rstrip() for line in open('stopwords.txt',encoding='utf-8') ])
finalwords = []
for word in words:
if word not in stopwords:
if (word != "。" and word != ",") :
finalwords.append(word)
#step3:统计特定关键词的出现次数
valuelist=[0]*len(wordsByMyself)
counts=dict(zip(wordsByMyself,valuelist))
for word in finalwords:
if len(word) == 1:#单个词不计算在内
continue
else:
counts[word]=counts.get(word,0)+1#遍历所有词语,每出现一次其对应值加1
for i in range(len(wordsByMyself)):
if wordsByMyself[i] in counts:
print(wordsByMyself[i]+':'+str(counts[wordsByMyself[i]]))
else:
print(wordsByMyself[i]+':0')
#主函数
if __name__ == "__main__":
rename()
for i in range(1,fileNum+1):
pdf_to_txt('dealPdf\\'+str(i)+'.pdf',i)#将pdf文件转化成txt文件,传入文件路径
delete_huanhangfu('dealTxt\\'+str(i)+'.txt',i)#对txt文件的换行符进行删除,防止词语因换行被拆分
word_by_myself()#添加自定义词语
print(f'----------result {i}----------')
cut_and_count('outPutTxt\\'+str(i)+'.txt')#分词并进行词频统计,传入文件路径结果预览
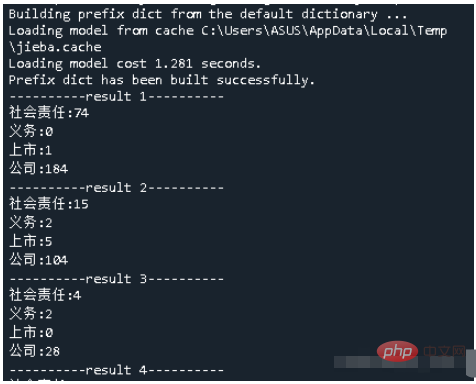
위 내용은 Python을 사용하여 PDF 파일을 일괄 처리하고 사용자 정의 키워드 발생 횟수를 계산하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
성명:
이 기사는 yisu.com에서 복제됩니다. 침해가 있는 경우 admin@php.cn으로 문의하시기 바랍니다. 삭제