



최근에는 다양한 주제 분야의 연구가 발전하면서 과학 문헌과 데이터가 폭발적으로 증가하여 학계 연구자들이 많은 양의 정보에서 유용한 통찰력을 발견하는 것이 점점 더 어려워지고 있습니다. 일반적으로 사람들은 과학적 지식을 얻기 위해 검색엔진을 사용하지만, 검색엔진은 과학지식을 자율적으로 정리할 수 없습니다.
이제 Meta AI 연구팀이 과학적 지식을 저장, 결합, 추론할 수 있는 새로운 대규모 언어 모델인 Galactica를 제안했습니다.

- 논문 주소: https://galactica.org/static/paper.pdf
- 시험판 주소: https://galactica.org/
Galaxica 모델 얼마나 강력한가요? 자체적으로 리뷰 논문을 요약하고 요약할 수 있습니다.

또한 항목에 대한 백과사전 쿼리를 생성할 수도 있습니다.

제기된 질문에 대한 지식이 풍부한 답변 제공:

이 작업은 인류학자에게는 여전히 어려운 일이지만 Galactica는 이 작업을 잘 완료했습니다. Turing Award 수상자 Yann LeCun도 자신의 칭찬을 트윗했습니다.

Galactica 모델의 구체적인 세부 사항을 살펴보겠습니다.
모델 개요
Galactica 모델은 4,800만 개 이상의 논문, 교과서 및 유인물, 수백만 개의 화합물 및 단백질 지식, 과학 자료를 포함하여 논문, 참고 자료, 지식 기반 및 기타 다양한 소스로 구성된 대규모 과학 자료에서 훈련되었습니다. 웹사이트, 백과사전 등 선별되지 않은 웹 크롤러 기반 텍스트에 의존하는 기존 언어 모델과 달리 Galactica 교육에 사용되는 코퍼스는 고품질이며 고도로 선별되어 있습니다. 이 연구는 과적합 없이 여러 시대에 대해 모델을 훈련했으며, 여기서 반복 토큰을 사용하여 업스트림 및 다운스트림 작업의 성능이 향상되었습니다.
Galactica는 다양한 과학 작업에서 기존 모델보다 성능이 뛰어납니다. LaTeX 방정식과 같은 기술 지식 탐색 작업에서 Galactica와 GPT-3의 성능은 68.2% VS 49.0%입니다. Galactica는 또한 추론 능력이 뛰어나 수학적 MMLU 벤치마크에서 Chinchilla를 크게 능가합니다.
Galactica는 공통 코퍼스에 대한 교육을 받지 않았음에도 불구하고 BIG 벤치에서 BLOOM 및 OPT-175B보다 성능이 뛰어납니다. 또한 PubMedQA 및 MedMCQA 개발과 같은 다운스트림 작업에서 77.6%와 52.9%의 새로운 최고 성능을 달성했습니다.
간단히 말하면, 연구는 내부 작동을 모방하기 위해 특별한 토큰에 단계별 추론을 캡슐화합니다. 이를 통해 연구원들은 아래 Galactica의 시험 인터페이스에 표시된 것처럼 자연어를 사용하여 모델과 상호 작용할 수 있습니다.

Galactica는 텍스트 생성 외에도 화학 공식 및 단백질 서열과 관련된 다중 모드 작업도 수행할 수 있다는 점을 언급할 가치가 있습니다. 이는 약물 발견 분야에 기여할 것입니다.
구현 세부 정보
이 기사의 자료에는 논문, 참고 자료, 백과사전 및 기타 과학 자료에서 가져온 1,060억 개의 토큰이 포함되어 있습니다. 본 연구에는 자연어 자원(논문, 참고서)과 자연의 서열(단백질 서열, 화학적 형태)이 모두 포함되어 있다고 할 수 있습니다. 코퍼스의 세부 사항은 표 1과 2에 나와 있습니다.

이제 말뭉치가 생겼으니 다음 단계는 데이터를 조작하는 방법입니다. 일반적으로 토큰화의 설계는 매우 중요합니다. 예를 들어, 단백질 서열이 아미노산 잔기 측면에서 작성된 경우 문자 기반 토큰화가 적합합니다. 토큰화를 달성하기 위해 본 연구에서는 다양한 방식으로 특화된 토큰화를 수행했습니다. 구체적인 표현에는 다음이 포함되지만 이에 국한되지는 않습니다.
- 참조: 특수 참조 토큰 [START_REF] 및 [END_REF]를 사용하여 참조를 래핑합니다.
- 단계별 추론: 작업 메모리 토큰을 사용하여 캡슐화합니다. 단계별 추론 및 시뮬레이션 내부 작업 메모리 컨텍스트
- 숫자: 숫자를 별도의 토큰으로 나눕니다. 예를 들어 737612.62 → 7,3,7,6,1,2,.,6,2;
- SMILES 수식: 시퀀스를 [START_SMILES] 및 [END_SMILES]로 래핑하고 문자 기반 토큰화를 적용합니다. 마찬가지로 이 연구에서는 [START_I_SMILES] 및 [END_I_SMILES]를 사용하여 이성체 SMILES를 나타냅니다. 예: C(C(=O)O)N→C, (,C,(,=,O,),O,),N
- DNA 시퀀스: 각 뉴클레오티드에 문자 기반 토큰화 적용 염기는 토큰으로 간주되며 시작 토큰은 [START_DNA] 및 [END_DNA]입니다. 예를 들어 CGGTACCCTC→C, G, G, T, A, C, C, C, T, C입니다.
아래 그림 4는 논문에 대한 참조 처리의 예를 보여줍니다. 참조를 처리할 때 전역 식별자와 특수 토큰 [START_REF] 및 [END_REF]를 사용하여 참조 위치를 나타냅니다.

데이터 세트가 처리된 후 다음 단계는 이를 구현하는 방법입니다. Galactica는 Transformer 아키텍처를 기반으로 다음과 같이 수정했습니다.
- GeLU 활성화: 다양한 크기의 모델에 GeLU 활성화를 사용합니다.
- 컨텍스트 창: 다양한 크기의 모델에는 2048 길이의 컨텍스트 창을 사용합니다.
- 편향 없음: PaLM을 따르며 밀도가 높은 커널 또는 레이어 사양에 편향이 사용되지 않습니다.
- 위치 임베딩 학습: 모델에 대한 위치 임베딩 학습
- 용어집: BPE를 사용하여 용어집 작성 50,000개의 토큰이 포함되어 있습니다.
표 5에는 다양한 크기와 훈련 하이퍼파라미터의 모델이 나열되어 있습니다.

실험
중복 토큰은 무해한 것으로 간주됩니다.
그림 6에서 볼 수 있듯이 4번의 훈련 이후 검증 손실은 계속해서 감소합니다. 120B 매개변수를 가진 모델은 다섯 번째 에포크가 시작될 때만 과적합되기 시작합니다. 기존 연구에 따르면 중복 토큰이 성능에 해로울 수 있다는 사실이 밝혀졌기 때문에 이는 예상치 못한 일입니다. 또한 연구에서는 30B 및 120B 모델이 검증 손실이 정체(또는 증가)된 후 감소하는 획기적인 이중 감소 효과를 나타냄을 발견했습니다. 이 효과는 각 시대마다 더욱 강해지며, 특히 훈련이 끝난 120B 모델의 경우 더욱 두드러집니다.
그림 8 결과는 실험에서 과적합의 징후가 없음을 보여 주며, 이는 반복된 토큰이 다운스트림 및 업스트림 작업의 성능을 향상시킬 수 있음을 보여줍니다. heculse 기타 결과 ing 타이핑 공식은 너무 느립니다. 이제 프롬프트로 라텍스를 생성 할 수 있습니다. 화학 반응, Galactica 생성물의 경우 모델은 반응물만을 기준으로 추론할 수 있으며 결과는 다음과 같습니다.

일부 다른 결과는 표 7에 보고됩니다.
갤럭티카의 추론 능력. 본 연구는 MMLU 수학 벤치마크에서 먼저 평가되었으며 평가 결과는 표 8에 보고되어 있습니다. Galactica는 더 큰 기본 모델에 비해 강력한 성능을 발휘하며 토큰을 사용하면 더 작은 30B Galactica 모델에서도 Chinchilla의 성능이 향상되는 것으로 보입니다.
이 연구에서는 Galactica의 추론 기능을 더 자세히 탐색하기 위해 MATH 데이터 세트도 평가했습니다.

실험 결과에서 결론을 내릴 수 있습니다. Galactica는 사고 연결 및 유도 측면에서 기본 PaLM보다 훨씬 뛰어납니다. 모델. 이는 Galactica가 수학적 작업을 처리하는 데 더 나은 선택임을 시사합니다. 다운스트림 작업에 대한
평가 결과는 표 10에 나와 있습니다. Galactica는 다른 언어 모델보다 성능이 훨씬 뛰어나며 대부분의 작업에서 더 큰 모델보다 성능이 뛰어납니다(Gopher 280B). 성능 차이는 Chinchilla의 차이보다 크며, 특히 고등학교 과목과 덜 수학적, 기억 집약적인 작업 등 하위 작업에서 더 강한 것으로 보입니다. 대조적으로 Galactica는 수학과 대학원 수준의 작업에서 더 나은 성과를 거두는 경향이 있습니다.

이 연구는 또한 입력 맥락에 따라 인용을 예측하는 Chinchilla의 능력을 평가했습니다. 이는 Chinchilla의 과학 문헌 정리 능력에 대한 중요한 테스트입니다. 결과는 다음과 같습니다.
더 많은 실험적인 내용은 원문을 참고해주세요.
위 내용은 대형 모델은 공식과 참고자료를 포함하여 자체적으로 논문을 '작성'할 수 있습니다. 이제 평가판이 온라인에 제공됩니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 AI 에이전트를 사용하여 개인화 된 뉴스 다이제스트를 만듭니다Apr 12, 2025 am 11:18 AM
AI 에이전트를 사용하여 개인화 된 뉴스 다이제스트를 만듭니다Apr 12, 2025 am 11:18 AM소개 대형 언어 모델 (LLM)의 기능은 빠르게 발전하고 있습니다. 그들은 우리가 다양한 LLM 응용 프로그램을 구축 할 수있게합니다. 작업 자동화에서 워크 플로 최적화에 이르기까지 다양합니다. 흥미로운 응용 프로그램 중 하나입니다
 미국 AI 정책은'안전'에서'보안'에 이르기까지 급격히 피벗됩니다.Apr 12, 2025 am 11:15 AM
미국 AI 정책은'안전'에서'보안'에 이르기까지 급격히 피벗됩니다.Apr 12, 2025 am 11:15 AM도널드 트럼프 대통령은 조 비덴 전 대통령의 AI 행정 명령을 철회했다.
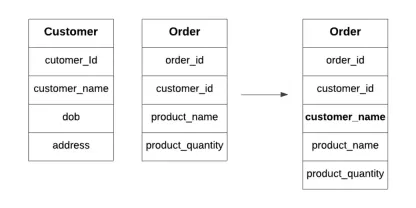 데이터베이스의 비정규 화는 무엇입니까?Apr 12, 2025 am 11:10 AM
데이터베이스의 비정규 화는 무엇입니까?Apr 12, 2025 am 11:10 AM소개 매 초마다 바쁜 카페를 운영한다고 상상해보십시오. 별도의 인벤토리 및 주문 목록을 지속적으로 확인하는 대신 모든 주요 세부 사항을 읽기 쉬운 보드에 통합합니다. 이것은 denormaliza와 유사합니다
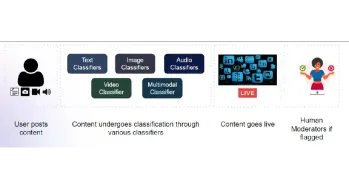 콘텐츠 중재를위한 멀티 모달 모델 구축Apr 12, 2025 am 10:51 AM
콘텐츠 중재를위한 멀티 모달 모델 구축Apr 12, 2025 am 10:51 AM소개 공격적인 게시물이 나타날 때 좋아하는 소셜 미디어 플랫폼을 스크롤한다고 상상해보십시오. 보고서 버튼을 누르기 전에 사라졌습니다. 그게 내용 Moderati입니다
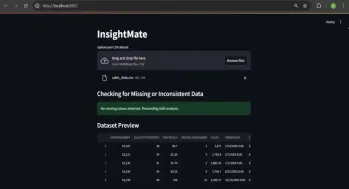 InsightMate를 사용하여 데이터 통찰력을 자동화하십시오Apr 12, 2025 am 10:44 AM
InsightMate를 사용하여 데이터 통찰력을 자동화하십시오Apr 12, 2025 am 10:44 AM소개 오늘날의 데이터가 많은 세상에서 거대한 데이터 세트를 처리하는 것은 매우 압도적 일 수 있습니다. 그곳에서 Insightmate가 들어오는 곳입니다. 데이터 탐색을 산들 바람으로 만들도록 설계되었습니다. 데이터 세트를 업로드하면 Instan이 나타납니다
 벡터 스트리밍 : 녹이있는 메모리 효율적인 인덱싱Apr 12, 2025 am 10:42 AM
벡터 스트리밍 : 녹이있는 메모리 효율적인 인덱싱Apr 12, 2025 am 10:42 AM소개 대규모 문서 임베딩을 최적화하도록 설계된 기능인 Embedanything의 벡터 스트리밍이 소개됩니다. Rust 's Concurrency를 사용하여 비동기 청크 및 임베딩을 활성화하면 메모리 사용이 줄어들고
 REPLIT 에이전트 란 무엇입니까? | 입문 안내서 -Anuceics VidhyaApr 12, 2025 am 10:40 AM
REPLIT 에이전트 란 무엇입니까? | 입문 안내서 -Anuceics VidhyaApr 12, 2025 am 10:40 AM소개 대화와 똑같은 앱을 개발한다고 상상해보십시오. 설정할 복잡한 개발 환경이없고 구성 파일을 살펴볼 필요가 없습니다.
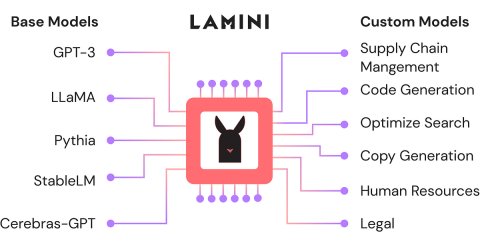 Lamini- 분석 Vidhya를 사용한 미세 조정 오픈 소스 LLMApr 12, 2025 am 10:20 AM
Lamini- 분석 Vidhya를 사용한 미세 조정 오픈 소스 LLMApr 12, 2025 am 10:20 AM최근에 대규모 언어 모델과 AI가 증가함에 따라 우리는 자연어 처리에서 수많은 발전을 보았습니다. 텍스트, 코드 및 이미지/비디오 생성과 같은 도메인의 모델은 인간과 같은 추론과 P를 보관했습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 Linux 새 버전
SublimeText3 Linux 최신 버전

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

ZendStudio 13.5.1 맥
강력한 PHP 통합 개발 환경

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

