
파이썬에서 이미지를 텍스트로 변환하는 방법

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-20 11:07:062207검색
python 이미지를 텍스트로
python+Tesseract-OCR을 사용하여 이미지를 텍스트로 변환하는 작은 도구를 만들고 GUI 디자인은 tkinter 라이브러리의 제어를 사용합니다
인터페이스와 효과는 아래 그림을 참조하세요.
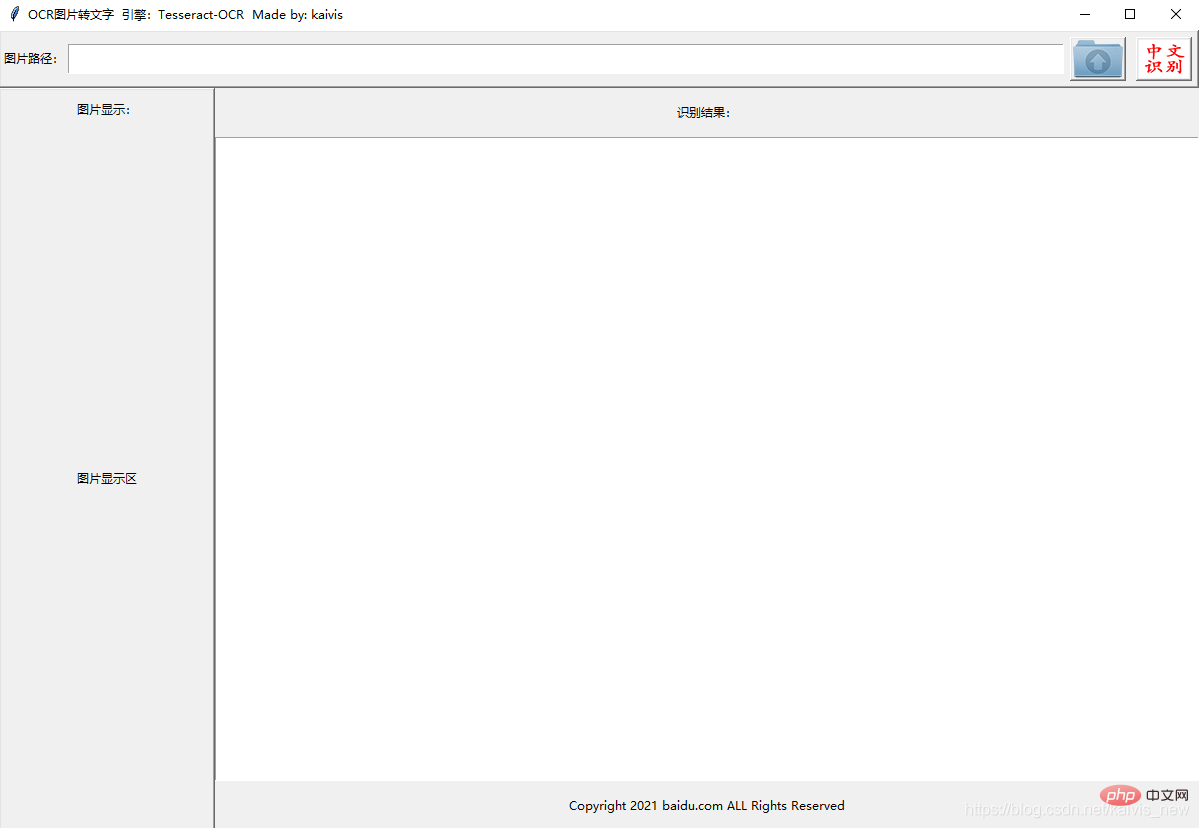
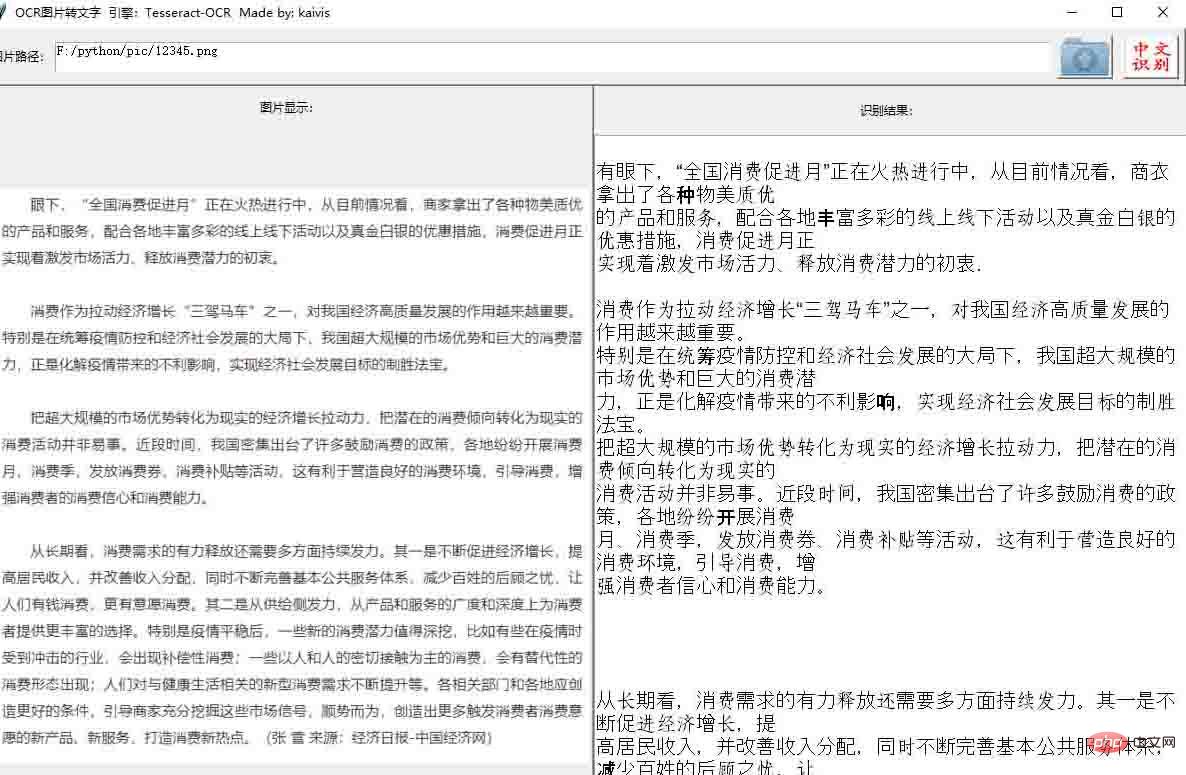
#进一步优化 1. 底部添加label 2.对识别后的文本处理,去空格
from PIL import Image as PImage
from PIL import ImageTk
import pytesseract
from tkinter import *
from tkinter import filedialog
from tkinter.scrolledtext import ScrolledText
import re
# 将图片内容翻译为文字,显示在文本框内
def trans():
contents.delete('1.0', END)
transTxt = pytesseract.image_to_string(PImage.open(filePath.get()),lang='chi_sim')
#对transTxt进行处理 去空格,换行符去重
transTxt = transTxt.strip('\n\r') #无参数可以删除开头结尾的空格\n\t\r
print(transTxt)
contents.insert( INSERT, transTxt.replace(' ','').replace('\n\n','\n').replace('\r',''))
#打开图片文件,显示路径,并将图片展现
def openfile():
filename.delete('1.0', END)
filePath.set(filedialog.askopenfilename())
filename.insert(1.0,filePath.get())
org_img = PImage.open(filePath.get())
#调整图片显示大小 600*800
w,h = org_img.size
if w>600:
h=int(h*600/w)
w=600
if h>800:
w=int(w*800/h)
h=800
img = ImageTk.PhotoImage(org_img.resize((w,h)))
showPic.config(image=img)
showPic.image = img #保持一个引用才能显示图片,tkinter的BUG
#设置主窗口
top = Tk()
top.title("OCR图片转文字 引擎:Tesseract-OCR Made by: kaivis")
#top.iconbitmap("./pic/y1.ico")
top.geometry("1200x800")
filePath=StringVar()
bt_img1 = ImageTk.PhotoImage( file= "./pic/Outbox1.png")
bt_img2 = ImageTk.PhotoImage( file= "./pic/bt_img2.png")
#第一个窗体
frame1 = Frame (top, relief=RAISED, borderwidth=2)
frame1.pack(side=TOP, fill=BOTH, ipady=5, expand=0)
Label(frame1,height=1,text="图片路径:").pack(side=LEFT)
filename = Text(frame1,height=2)
filename.pack(side=LEFT,padx=1, pady=0,expand=True, fill=X)
Button(frame1,text="打开文件", image=bt_img1, command=openfile).pack(side=LEFT,padx=5, pady=0)
Button(frame1,text="中文识别", image=bt_img2, command=trans).pack(side=LEFT,padx=5, pady=0)
#第二个窗体
frame2 = Frame (top, relief=RAISED, borderwidth=2)
frame2.pack (side=LEFT, fill=BOTH, expand=1)
Label(frame2,text='图片显示:',borderwidth=5).pack(side=TOP,padx=20,pady=5)
showPic = Label(frame2,text='图片显示区')
showPic.pack(side=BOTTOM,expand=1,fill=BOTH)
#第三个窗体
frame3 = Frame (top)
frame3.pack (side=RIGHT, fill=BOTH, expand=1)
#contents = ScrolledText(frame3)
Label(frame3,text='识别结果:',borderwidth=5).pack(side=TOP,padx=20,pady=10)
contents = Text(frame3,font=('Arial',15))
contents.pack(side=TOP,expand=1,fill=BOTH)
Label(frame3,text='Copyright 2021 baidu.com ALL Rights Reserved',borderwidth=5).pack(side=BOTTOM,padx=20,pady=10)
top.mainloop()문제:
인식률도 높지 않고, 컴팩트한 한자의 경우 높은 정확도를 달성하기가 더욱 어렵습니다.
인식된 텍스트가 완료되었습니다. 공백을 제거하면 텍스트를 더욱 최적화할 수 있습니다. 특히 처리해야 할 중복된 줄바꿈을 처리할 수 있습니다
python 스크린샷을 텍스트 기능으로
인터넷에서 정보를 검색할 때 우리는 종종 상황에 직면합니다 기사를 빠르게 복사할 수 있도록 텍스트로 작성하고 싶어서 스크린샷을 텍스트로 변환하는 기능을 구현하는 Python 프로그램을 작성하고 싶었습니다.

1. 아이디어
먼저 키보드를 녹음하는 기능이 있어야 합니다(프로그램에 스크린샷을 찍고 있음을 알려주세요). 스크린샷을 찍은 후 키보드 라이브러리에서 이미지를 받아야 합니다. ImageGrab 라이브러리는 이미지를 얻은 후 텍스트 인식을 수행해야 합니다. - Baidu AI 텍스트 인식 API
2. 구현
2.1 관련 라이브러리 가져오기
2.2 클래스 생성 및 스크린샷 저장 함수 작성
저는 win10과 함께 제공되는 스크린샷 소프트웨어를 사용하고 있기 때문에 스크린샷 단축키는 ‘win+shift+s’이며, 다른 스크린샷 소프트웨어에 따라 자유롭게 변경할 수 있습니다.

2.3 이미지를 텍스트로 변환하는 함수 작성
먼저 바이두 스마트 클라우드 공식 홈페이지에 가서 이미지 인식 API를 신청하세요.
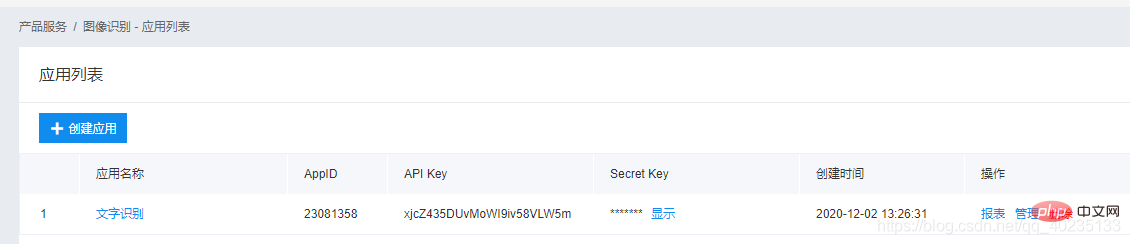
프로그램에 매개변수 쓰기:
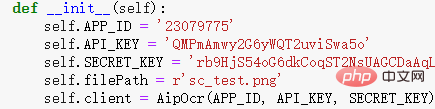
텍스트 변환 함수 쓰기:

2.5 실행 시 클래스 생성
및 두 함수 호출:
2.6 효과 
프로그램을 실행하고 Baidu 라이브러리의 기사에서 스크린샷을 찍습니다.
결과는 다음과 같습니다.
참고: 
2.6 실행 결과에서 볼 수 있습니다. 효과는 여전히 좋습니다. 현재 요구 사항을 완벽하게 해결했습니다.
위 내용은 파이썬에서 이미지를 텍스트로 변환하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!