
Java 분산 Kafka 메시지 큐 인스턴스 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-19 16:10:151293검색
소개
Apache Kafka는 분산 게시-구독 메시징 시스템입니다. kafka 공식 웹사이트에서 kafka를 정의하면 분산 게시-구독 메시징 시스템입니다. 원래 LinkedIn에서 개발되었으며 2010년 Apache Foundation에 기부되어 최고의 오픈 소스 프로젝트가 되었습니다. Kafka는 빠르고 확장 가능하며 본질적으로 분산, 분할 및 복제 가능한 커밋 로그 서비스입니다.
참고: Kafka는 JMS 사양()을 따르지 않으며 게시 및 구독 통신 방법만 제공합니다.
Kafka 핵심 관련 이름
Broker: Kafka 노드, Kafka 노드는 브로커, 여러 브로커가 Kafka 클러스터를 형성할 수 있음
Topic: 메시지 유형, 메시지가 저장되는 디렉터리가 주제입니다. , 페이지 조회 로그, 클릭 로그 등이 토픽 형태로 존재할 수 있습니다. Kafka 클러스터는 동시에 여러 토픽의 배포를 담당할 수 있습니다.
massage: Kafka의 가장 기본적인 전달 개체입니다.
파티션: 주제의 물리적 그룹화입니다. 주제는 여러 파티션으로 나눌 수 있으며 각 파티션은 순서가 지정된 대기열입니다. 파티셔닝은 Kafka에서 구현되며 브로커는 지역을 나타냅니다.
파티션은 물리적으로 여러 세그먼트로 구성되며 각 세그먼트는 메시지 정보를 저장합니다
Producer: 생산자, 메시지를 생성하고 이를 주제로 보냅니다
Consumer: 소비자, 주제를 구독하고 메시지를 소비합니다. 스레드로 소비
소비자 그룹: 소비자 그룹, 소비자 그룹에는 여러 소비자가 포함됨
오프셋: 오프셋, 메시지 파티션에서 메시지의 인덱스 위치로 이해됨
주제와 대기열의 차이점 :
Queue는 선입선출 원칙을 따르는 데이터 구조입니다
kafka 클러스터 설치
각 서버에 jdk1.8 환경 설치
Zookeeper 클러스터 환경 설치
kafka 설치 클러스터 환경
실행 환경 테스트
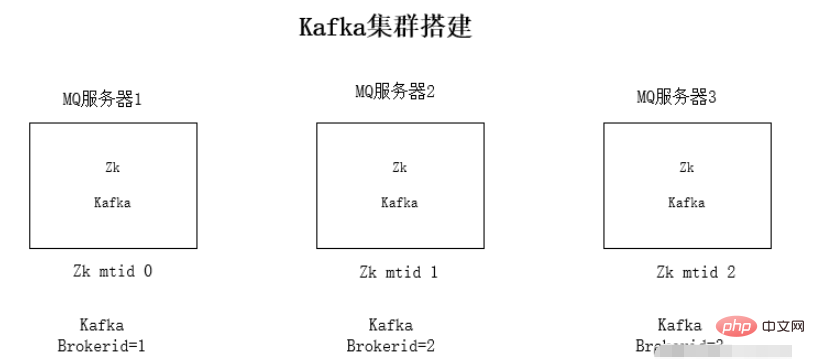
jdk 환경 및 Zookeeper 설치에 대해서는 여기서 자세히 설명하지 않습니다.
Kafka가 Zookeeper에 의존하는 이유: Kafka는 전체 클러스터를 쉽게 확장할 수 있도록 Zookeeper의 mq 정보를 저장하기 위해 서로를 감지하는 데 사용됩니다.
kafka 클러스터 설치 단계:
1. kafka의 압축 패키지를 다운로드합니다.
2. 설치 패키지의 압축을 풉니다.
tar -zxvf kafka_2.11-1.0.0.tgz
3. .properties
구성 파일 수정 내용:
zookeeper 연결 주소:
zookeeper.connect=192.168.1.19:2181zookeeper.connect=192.168.1.19:2181监听的ip,修改为本机的ip
listeners=PLAINTEXT://192.168.1.19:9092kafka的brokerid,每台broker的id都不一样
broker.id=0
4、依次启动kafka
./kafka-server-start.sh -daemon config/server.properties
kafka使用
kafka文件存储
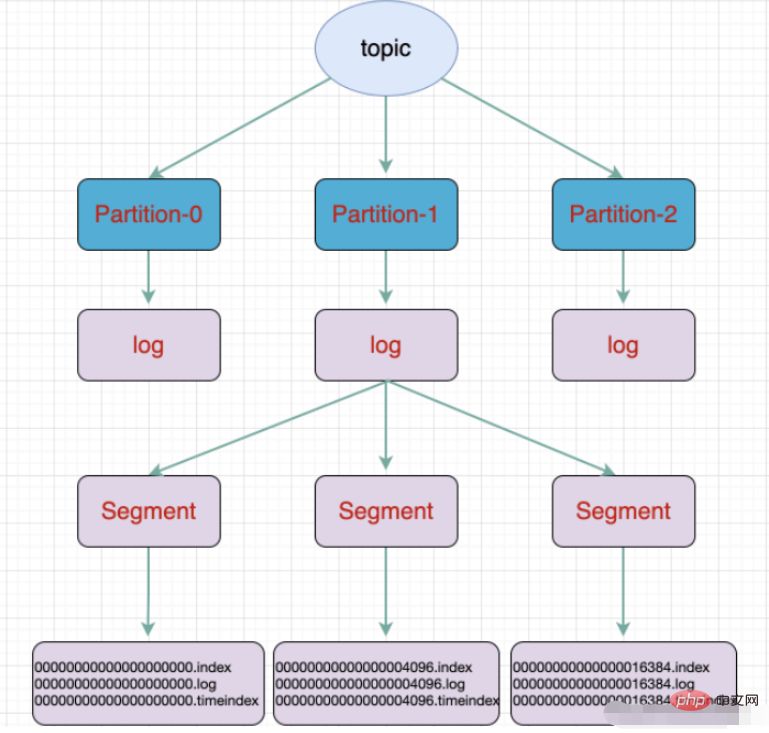
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是Producer生成的数据。Producer生成的数据会被不断追加到该log文件末端,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment,每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。
例如:执行命令新建一个主题,分三个区存放放在三个broker中:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico
 듣는 IP가 로컬 IP로 변경됩니다
듣는 IP가 로컬 IP로 변경됩니다listeners =PLAINTEXT://192.168.1.19:9092
broker.id=0- 4. 카프카를 순차적으로 시작합니다.
-
./kafka-server-start.sh -daemon config/server.propertieskafka는 - kafka 파일 저장소를 사용합니다. 주제는 논리적 개념이고 파티션은 물리적 개념을 기반으로 합니다. 위에서 각 파티션은 로그 파일에 해당하며, 로그 파일에는 생산자가 생성한 데이터가 저장됩니다. 생산자에 의해 생성된 데이터는 로그 파일의 끝에 지속적으로 추가됩니다. 로그 파일이 너무 커서 데이터 위치 지정의 비효율성을 방지하기 위해 Kafka는 각 파티션을 여러 세그먼트로 나누는 샤딩 및 인덱싱 메커니즘을 채택합니다. 각 세그먼트에는 ".index" 파일, ".log" 파일 및 .timeindex 파일이 포함됩니다. 이러한 파일은 폴더에 있으며 폴더의 명명 규칙은 주제 이름 + 파티션 번호입니다.
- 예: 명령을 실행하여 세 개의 영역으로 나누어지고 세 개의 브로커에 저장되는 새 주제를 생성합니다.
./kafka-topics.sh --create --zookeeper localhost:2181 --replication -factor 1 - -partitions 3 --topic kaico
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>🎜yml 구성🎜# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094🎜producer🎜 @RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}🎜소비자 🎜 으아악위 내용은 Java 분산 Kafka 메시지 큐 인스턴스 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!