
행과 열을 삭제하는 Python drop()의 작업 방법은 무엇입니까?

- WBOY앞으로
- 2023-04-19 15:03:063222검색
drop() 함수는 기능 엔지니어링을 수행하고 데이터 세트를 분할할 때 유용할 수 있습니다. 데이터, 작업 열, 작업 행 등을 쉽게 제거할 수 있습니다.
drop()의 자세한 구문은 다음과 같습니다.
행 삭제는 인덱스, 삭제 열은 열:
DataFrame.drop(labels=None, axis=0, index=None, columns=None, inplace=False)
매개변수:
labels: 삭제할 행 또는 열의 레이블(단일일 수 있음) 라벨 또는 라벨 목록.
axis: 삭제할 행이나 열의 축, 0은 행, 1은 열을 의미합니다.
index: 삭제할 행의 인덱스로, 단일 인덱스이거나 인덱스 목록일 수 있습니다.
columns: 삭제할 열의 열 이름으로, 단일 열 이름이거나 열 이름 목록일 수 있습니다.
inplace: 원본 DataFrame에서 작업할지 여부입니다. 기본값은 False입니다. 즉, 원본 DataFrame에서 작업이 수행되지 않습니다.
열 삭제
사용 시나리오 1: 불필요한 기능을 삭제합니다.
예를 들어 일부 특성이 결과에 거의 영향을 미치지 않는 경우 종속변수와 관련이 없는 독립변수를 삭제하면 다중 공선성을 방지할 수 있으므로 상관관계가 강한 독립변수를 삭제해야 합니다.
df = data.drop(data[['RowNumber','CustomerId','Surname']],axis=1) df
코드 설명:
data는 데이터 세트입니다. 두 개의 대괄호는 삭제할 3개의 필드를 필터링하는 DataFrame 형식을 나타냅니다.
axis=1은 작업 열을 나타냅니다.
사용 시나리오 2: 종속 변수 삭제
# 自变量、因变量 x_data = df.drop(['Exited'],axis=1) y_data = df['Exited'] x_data
코드 설명: 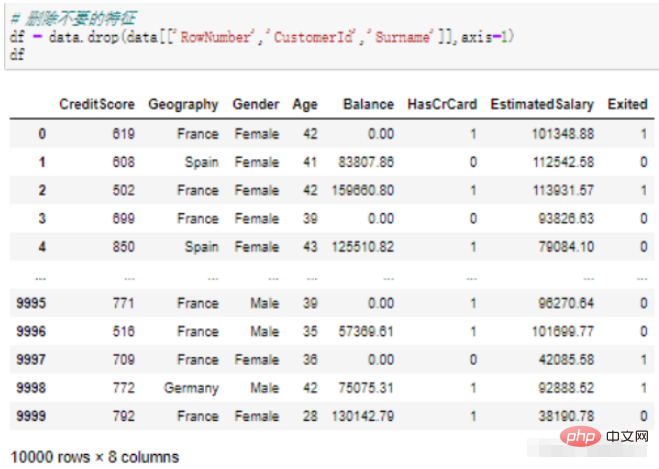
행 삭제
사용 시나리오 3: 데이터 세트를 분할할 때 훈련 세트가 생성되고 트레이닝 세트는 다음과 같이 나누어집니다. 세트에 포함된 샘플은 제거되고 나머지는 테스트 세트가 됩니다.
#划分训练集 train_data = data.sample(frac = 0.8, random_state = 0) #测试集 test_data = data.drop(train_data.index)
코드 설명: 
위 내용은 행과 열을 삭제하는 Python drop()의 작업 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!