



문자열의 하위 문자열
우리 모두는 문자열이 Java에서 변경 불가능하다는 것을 알고 있습니다. 내용을 변경하면 새 문자열이 생성됩니다. 문자열에 있는 데이터의 일부를 사용하려면 부분 문자열 방법을 사용할 수 있습니다.
다음은 Java11의 String 소스코드입니다.
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
public static String newString(byte[] val, int index, int len) {
if (String.COMPACT_STRINGS) {
byte[] buf = compress(val, index, len);
if (buf != null) {
return new String(buf, LATIN1);
}
}
int last = index + len;
return new String(Arrays.copyOfRange(val, index << 1, last << 1), UTF16);
}위 코드에서 볼 수 있듯이 부분 문자열이 필요할 때 부분 문자열은 생성자의 Arrays.copyOfRange 함수를 통해 생성되는 새로운 문자열을 생성합니다.
이 함수는 Java7 이후에는 문제가 없지만 Java6에서는 메모리 누수의 위험이 있습니다. 이 사례를 연구하면 대형 객체를 재사용할 때 발생할 수 있는 문제를 확인할 수 있습니다. 다음은 Java6에서의 코드입니다.
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ?
this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}하위 문자열을 생성할 때 필요한 객체만 복사하는 것이 아니라 전체 값을 참조하는 것을 볼 수 있습니다. 원래 문자열이 상대적으로 크면 더 이상 사용되지 않더라도 메모리가 해제되지 않습니다.
예를 들어, 기사의 내용 크기가 수 메가바이트일 수 있으며 요약 정보만 필요하고 전체 대형 개체를 유지해야 합니다.
오랫동안 일한 면접관 중 일부는 하위 문자열이 JDK6에 여전히 있다는 인상을 받았지만 실제로 Java는 이미 이 버그를 수정했습니다. 면접 중 이런 질문이 발생하는 경우, 안전을 위해 개선 과정에 대한 질문에 답변해 주시면 됩니다.
이것이 우리에게 의미하는 바는: 상대적으로 큰 개체를 만들고 이 개체를 기반으로 다른 정보를 생성하는 경우 이때 이 큰 개체와의 참조 관계를 제거해야 한다는 것을 기억해야 합니다.
대형 컬렉션 객체의 확장
객체 확장은 StringBuilder, StringBuffer, HashMap, ArrayList 등과 같은 Java에서 일반적인 현상입니다. 요약하면 List, Set, Queue, Map 등을 포함한 Java 컬렉션의 데이터는 제어할 수 없습니다. 용량이 부족하면 확장 작업을 수행하려면 데이터를 재구성해야 하므로 스레드로부터 안전하지 않습니다.
먼저 StringBuilder의 확장 코드를 살펴보겠습니다.
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}용량이 충분하지 않으면 메모리가 두 배로 늘어나고 소스 데이터는 Arrays.copyOf를 사용하여 복사됩니다.
다음은 HashMap의 확장 코드입니다. 확장 후 크기도 두 배로 늘어납니다. 확장 작업은 훨씬 더 복잡하며 로드 요소의 영향 외에도 원본 데이터를 다시 해시해야 합니다. 기본 Arrays.copy 메서드를 사용할 수 없으므로 속도가 매우 느립니다.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}리스트의 코드를 직접 볼 수도 있습니다. 확장 전략은 원래 길이의 1.5배입니다.
컬렉션은 코드에서 매우 자주 사용되므로 데이터 항목의 구체적인 상한선을 알고 있는 경우 합리적인 초기화 크기를 설정하는 것이 좋습니다. 예를 들어 HashMap에는 1024개의 요소와 7개의 확장이 필요하며 이는 애플리케이션 성능에 영향을 미칩니다. 이 질문은 인터뷰에서 자주 나오므로 이러한 확장 작업이 성능에 미치는 영향을 이해해야 합니다.
그러나 로드 팩터(0.75)가 있는 HashMap과 같은 컬렉션의 경우 초기 크기 = 필요한 수/로드 팩터 + 1입니다. 기본 구조에 대해 명확하지 않은 경우 다음을 유지하는 것이 좋습니다. 기본.
다음으로는 데이터의 구조적 차원과 시간 차원부터 시작하여 애플리케이션 레벨의 최적화에 대해 설명하겠습니다.
적절한 개체 세분성 유지
실제 사례를 공유하겠습니다. 우리는 사용자의 기본 데이터를 자주 사용해야 하는 매우 높은 동시성을 갖춘 비즈니스 시스템을 가지고 있습니다.
아래 그림과 같이 사용자의 기본정보가 다른 서비스에 저장되어 있기 때문에 해당 사용자의 기본정보를 사용할 때마다 네트워크 상호작용이 필요합니다. 더욱 수용할 수 없는 점은 사용자의 성별 속성만 필요한 경우에도 모든 사용자 정보를 쿼리하고 가져와야 한다는 것입니다.
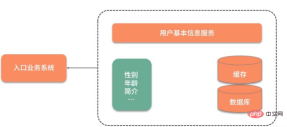
데이터 쿼리 속도를 높이기 위해 처음에는 데이터를 캐시하여 Redis에 넣었습니다. 쿼리 성능은 크게 향상되었지만 여전히 매번 쿼리해야 하는 중복 데이터가 많았습니다.
원래 Redis 키는 다음과 같이 설계되었습니다.
type: string
key: user_${userid}
value: json이 설계에는 두 가지 문제가 있습니다.
특정 필드의 값을 쿼리하려면 모든 json 데이터를 쿼리하고 직접 구문 분석해야 합니다.
업데이트하세요. 그 중 필드 값을 사용하려면 전체 json 문자열을 업데이트해야 하므로 비용이 많이 듭니다.
이런 종류의 대규모 json 정보의 경우 분산된 방식으로 최적화하여 모든 업데이트와 쿼리에 집중된 대상이 있을 수 있습니다.
다음으로, json 구조 대신 해시 구조를 사용하여 Redis에서 데이터를 다음과 같이 설계했습니다.
type: hash
key: user_${userid}
value: {sex:f, id:1223, age:23}이러한 방식으로 hget 명령 또는 hmget 명령을 사용하여 원하는 데이터를 가져오고 정보 흐름 속도를 높일 수 있습니다. .
비트맵은 객체를 더 작게 만듭니다
위 작업 외에도 더 최적화할 수 있나요? 예를 들어, 사용자의 성별 데이터는 일부 선물을 배포하고, 이성 친구를 추천하고, 정기적으로 사용자에게 청소 작업을 수행하는 등의 작업을 수행하거나 사용자 상태 정보(예: 사용 여부)를 저장하는 데 자주 사용됩니다. 온라인 상태인지, 체크인했는지 여부, 최근에 정보가 전송되었는지 여부 등 활성 사용자 수를 계산합니다. 그러면 yes와 no라는 두 값의 연산을 Bitmap 구조를 이용하여 압축할 수 있다.
这里还有个高频面试问题,那就是 Java 的 Boolean 占用的是多少位?
在 Java 虚拟机规范里,描述是:将 Boolean 类型映射成的是 1 和 0 两个数字,它占用的空间是和 int 相同的 32 位。即使有的虚拟机实现把 Boolean 映射到了 byte 类型上,它所占用的空间,对于大量的、有规律的 Boolean 值来说,也是太大了。
如代码所示,通过判断 int 中的每一位,它可以保存 32 个 Boolean 值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap 就是使用 Bit 进行记录的数据结构,里面存放的数据不是 0 就是 1。还记得我们在之前 《分布式缓存系统必须要解决的四大问题》中提到的缓存穿透吗?就可以使用 Bitmap 避免,Java 中的相关结构类,就是 java.util.BitSet,BitSet 底层是使用 long 数组实现的,所以它的最小容量是 64。
10 亿的 Boolean 值,只需要 128MB 的内存,下面既是一个占用了 256MB 的用户性别的判断逻辑,可以涵盖长度为 10 亿的 ID。
static BitSet missSet = new BitSet(010_000_000_000);
static BitSet sexSet = new BitSet(010_000_000_000);
String getSex(int userId) {
boolean notMiss = missSet.get(userId);
if (!notMiss) {
//lazy fetch
String lazySex = dao.getSex(userId);
missSet.set(userId, true);
sexSet.set(userId, "female".equals(lazySex));
}
return sexSet.get(userId) ? "female" : "male";
}这些数据,放在堆内内存中,还是过大了。幸运的是,Redis 也支持 Bitmap 结构,如果内存有压力,我们可以把这个结构放到 Redis 中,判断逻辑也是类似的。
再插一道面试算法题:给出一个 1GB 内存的机器,提供 60亿 int 数据,如何快速判断有哪些数据是重复的?
大家可以类比思考一下。Bitmap 是一个比较底层的结构,在它之上还有一个叫作布隆过滤器的结构(Bloom Filter),布隆过滤器可以判断一个值不存在,或者可能存在。
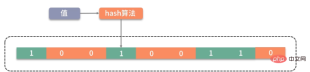
如图,它相比较 Bitmap,它多了一层 hash 算法。既然是 hash 算法,就会有冲突,所以有可能有多个值落在同一个 bit 上。它不像 HashMap一样,使用链表或者红黑树来处理冲突,而是直接将这个hash槽重复使用。从这个特性我们能够看出,布隆过滤器能够明确表示一个值不在集合中,但无法判断一个值确切的在集合中。
Guava 中有一个 BloomFilter 的类,可以方便地实现相关功能。
上面这种优化方式,本质上也是把大对象变成小对象的方式,在软件设计中有很多类似的思路。比如像一篇新发布的文章,频繁用到的是摘要数据,就不需要把整个文章内容都查询出来;用户的 feed 信息,也只需要保证可见信息的速度,而把完整信息存放在速度较慢的大型存储里。
数据的冷热分离
数据除了横向的结构纬度,还有一个纵向的时间维度,对时间维度的优化,最有效的方式就是冷热分离。
所谓热数据,就是靠近用户的,被频繁使用的数据;而冷数据是那些访问频率非常低,年代非常久远的数据。
同一句复杂的 SQL,运行在几千万的数据表上,和运行在几百万的数据表上,前者的效果肯定是很差的。所以,虽然你的系统刚开始上线时速度很快,但随着时间的推移,数据量的增加,就会渐渐变得很慢。
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。

由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
数据双写
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
写入 MQ 分发
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
使用 Binlog 同步
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
思维发散
对于结果集的操作,我们可以再发散一下思维。可以将一个简单冗余的结果集,改造成复杂高效的数据结构。这个复杂的数据结构可以代理我们的请求,有效地转移耗时操作。
예를 들어 우리가 일반적으로 사용하는 데이터베이스 인덱스는 일종의 데이터 재구성 및 가속입니다. B+ 트리는 데이터베이스와 디스크 사이의 상호 작용 횟수를 효과적으로 줄일 수 있습니다. B+ 트리와 유사한 데이터 구조를 통해 가장 일반적으로 사용되는 데이터를 색인화하여 제한된 저장 공간에 저장합니다.
RPC에서 흔히 사용되는 직렬화도 있습니다. 일부 서비스는 XML 기반 프로토콜인 SOAP 프로토콜 WebService를 사용합니다. 대용량 콘텐츠의 전송은 느리고 비효율적입니다. 오늘날 대부분의 웹 서비스는 상호 작용을 위해 json 데이터를 사용하며 json은 SOAP보다 더 효율적입니다.
또한 Google의 protobuf는 누구나 들어봤을 것입니다. 바이너리 프로토콜이고 데이터를 압축하기 때문에 성능이 매우 뛰어납니다. protobuf가 데이터를 압축한 후 크기는 json의 1/10, xml의 1/20에 불과하지만 성능은 5~100배 향상됩니다.
protobuf의 디자인은 tag|leng|value의 세 가지 섹션을 통해 매우 컴팩트하게 데이터를 처리하고 구문 분석 및 전송 속도가 매우 빠르므로 배울 가치가 있습니다.
위 내용은 Java에서 대형 객체를 처리하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 고급 Java 프로젝트 관리, 구축 자동화 및 종속성 해상도에 Maven 또는 Gradle을 어떻게 사용합니까?Mar 17, 2025 pm 05:46 PM
고급 Java 프로젝트 관리, 구축 자동화 및 종속성 해상도에 Maven 또는 Gradle을 어떻게 사용합니까?Mar 17, 2025 pm 05:46 PM이 기사에서는 Java 프로젝트 관리, 구축 자동화 및 종속성 해상도에 Maven 및 Gradle을 사용하여 접근 방식과 최적화 전략을 비교합니다.
 적절한 버전 및 종속성 관리로 Custom Java 라이브러리 (JAR Files)를 작성하고 사용하려면 어떻게해야합니까?Mar 17, 2025 pm 05:45 PM
적절한 버전 및 종속성 관리로 Custom Java 라이브러리 (JAR Files)를 작성하고 사용하려면 어떻게해야합니까?Mar 17, 2025 pm 05:45 PM이 기사에서는 Maven 및 Gradle과 같은 도구를 사용하여 적절한 버전 및 종속성 관리로 사용자 정의 Java 라이브러리 (JAR Files)를 작성하고 사용하는 것에 대해 설명합니다.
 카페인 또는 구아바 캐시와 같은 라이브러리를 사용하여 자바 애플리케이션에서 다단계 캐싱을 구현하려면 어떻게해야합니까?Mar 17, 2025 pm 05:44 PM
카페인 또는 구아바 캐시와 같은 라이브러리를 사용하여 자바 애플리케이션에서 다단계 캐싱을 구현하려면 어떻게해야합니까?Mar 17, 2025 pm 05:44 PM이 기사는 카페인 및 구아바 캐시를 사용하여 자바에서 다단계 캐싱을 구현하여 응용 프로그램 성능을 향상시키는 것에 대해 설명합니다. 구성 및 퇴거 정책 관리 Best Pra와 함께 설정, 통합 및 성능 이점을 다룹니다.
 캐싱 및 게으른 하중과 같은 고급 기능을 사용하여 객체 관계 매핑에 JPA (Java Persistence API)를 어떻게 사용하려면 어떻게해야합니까?Mar 17, 2025 pm 05:43 PM
캐싱 및 게으른 하중과 같은 고급 기능을 사용하여 객체 관계 매핑에 JPA (Java Persistence API)를 어떻게 사용하려면 어떻게해야합니까?Mar 17, 2025 pm 05:43 PM이 기사는 캐싱 및 게으른 하중과 같은 고급 기능을 사용하여 객체 관계 매핑에 JPA를 사용하는 것에 대해 설명합니다. 잠재적 인 함정을 강조하면서 성능을 최적화하기위한 설정, 엔티티 매핑 및 모범 사례를 다룹니다. [159 문자]
 Java의 클래스로드 메커니즘은 다른 클래스 로더 및 대표 모델을 포함하여 어떻게 작동합니까?Mar 17, 2025 pm 05:35 PM
Java의 클래스로드 메커니즘은 다른 클래스 로더 및 대표 모델을 포함하여 어떻게 작동합니까?Mar 17, 2025 pm 05:35 PMJava의 클래스 로딩에는 부트 스트랩, 확장 및 응용 프로그램 클래스 로더가있는 계층 적 시스템을 사용하여 클래스로드, 링크 및 초기화 클래스가 포함됩니다. 학부모 위임 모델은 핵심 클래스가 먼저로드되어 사용자 정의 클래스 LOA에 영향을 미치도록합니다.
 분산 컴퓨팅에 Java의 RMI (원격 메소드 호출)를 어떻게 사용할 수 있습니까?Mar 11, 2025 pm 05:53 PM
분산 컴퓨팅에 Java의 RMI (원격 메소드 호출)를 어떻게 사용할 수 있습니까?Mar 11, 2025 pm 05:53 PM이 기사에서는 분산 응용 프로그램을 구축하기위한 Java의 원격 메소드 호출 (RMI)에 대해 설명합니다. 인터페이스 정의, 구현, 레지스트리 설정 및 클라이언트 측 호출을 자세히 설명하여 네트워크 문제 및 보안과 같은 문제를 해결합니다.
 네트워크 통신에 Java의 Sockets API를 어떻게 사용합니까?Mar 11, 2025 pm 05:53 PM
네트워크 통신에 Java의 Sockets API를 어떻게 사용합니까?Mar 11, 2025 pm 05:53 PM이 기사는 네트워크 통신을위한 Java의 소켓 API, 클라이언트 서버 설정, 데이터 처리 및 리소스 관리, 오류 처리 및 보안과 같은 중요한 고려 사항에 대해 자세히 설명합니다. 또한 성능 최적화 기술, i
 Java에서 사용자 정의 네트워킹 프로토콜을 어떻게 만들 수 있습니까?Mar 11, 2025 pm 05:52 PM
Java에서 사용자 정의 네트워킹 프로토콜을 어떻게 만들 수 있습니까?Mar 11, 2025 pm 05:52 PM이 기사에서는 맞춤형 Java 네트워킹 프로토콜을 작성합니다. 프로토콜 정의 (데이터 구조, 프레임, 오류 처리, 버전화), 구현 (소켓 사용), 데이터 직렬화 및 모범 사례 (효율성, 보안, Mainta를 포함합니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

드림위버 CS6
시각적 웹 개발 도구

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.
뜨거운 주제
 1374
1374 524019
524019