
AI 역사상 최고 점수! 구글의 대규모 모델은 미국 의사면허 시험 문제에서 새로운 기록을 세웠고, 과학적 지식 수준은 인간 의사와 맞먹는다.

- PHPz앞으로
- 2023-04-18 16:49:031284검색
역사상 가장 높은 AI 점수, Google의 새로운 모델이 미국 의료 면허 시험 검증을 통과했습니다!
그리고 과학적 지식, 이해, 검색 및 추론 능력과 같은 작업에서는 인간 의사의 수준과 직접적으로 경쟁합니다. 일부 임상 질문 및 답변 성능에서는 원래 SOTA 모델을 17% 이상 능가했습니다.


이 개발이 나오자마자 학계에서는 즉시 열띤 토론이 벌어졌습니다. 업계의 많은 사람들은 한숨을 쉬었습니다. 드디어 왔습니다.
Med-PaLM과 인간 의사의 비교를 본 많은 네티즌들은 벌써부터 AI 의사의 위촉을 기대하고 있다고 표현했습니다.

어떤 사람들은 이 타이밍의 정확성을 비웃기도 했는데, 이는 모두가 ChatGPT로 인해 Google이 "죽을 것"이라고 생각하는 것과 일치했습니다.

어떤 연구인지 살펴볼까요?
역사상 가장 높은 AI 점수
의료의 전문적 특성으로 인해 오늘날 이 분야의 AI 모델은 언어를 상당 부분 활용하지 못합니다. 이러한 모델은 유용하지만 단일 작업 시스템(예: 분류, 회귀, 세분화 등)에 중점을 두고 표현력 및 상호 작용 기능이 부족하다는 문제가 있습니다.
대형 모델의 혁신은 AI+ 의료에 새로운 가능성을 가져왔지만, 이 분야의 특수성으로 인해 허위 의료 정보 제공 등 잠재적인 피해를 여전히 고려해야 합니다.
이러한 배경을 바탕으로 Google Research 및 DeepMind 팀은 의료 Q&A를 연구 대상으로 삼아 다음과 같은 기여를 했습니다.
- 의료 Q&A 벤치마크 MultiMedQA를 제안했으며, 여기에는 건강 검진, 의학 연구 및 소비자 의료 질문이 포함됩니다. MultiMedQA의 PaLM 및 미세 조정된 변형 Flan-PaLM
- Flan-PaLM을 약물과 추가로 통합하여 Med-PaLM을 만들기 위한 지침 프롬프트 x 조정을 제안합니다.
 AI가 고품질의 답변을 제공하려면 의학적 배경을 이해하고 적절한 의학적 지식을 회상하며 전문 정보에 대한 추론이 필요하기 때문에 "의학적 질문에 답변하는" 작업이 매우 어렵다고 생각합니다.
AI가 고품질의 답변을 제공하려면 의학적 배경을 이해하고 적절한 의학적 지식을 회상하며 전문 정보에 대한 추론이 필요하기 때문에 "의학적 질문에 답변하는" 작업이 매우 어렵다고 생각합니다.
기존 평가 벤치마크는 분류 정확도나 자연어 생성 지표 평가에 국한되는 경우가 많아 실제 임상 적용에 대한 자세한 분석을 제공할 수 없습니다.
먼저 팀은 7개의 의학 질문 답변 데이터 세트로 구성된 벤치마크를 제안했습니다.
MedQA(USMLE, 미국 의료 면허 시험 문제)를 포함하는 6개의 기존 데이터 세트가 포함되어 있으며, 검색된 건강 질문으로 구성된 새로운 데이터 세트인 HealthSearchQA도 소개합니다.
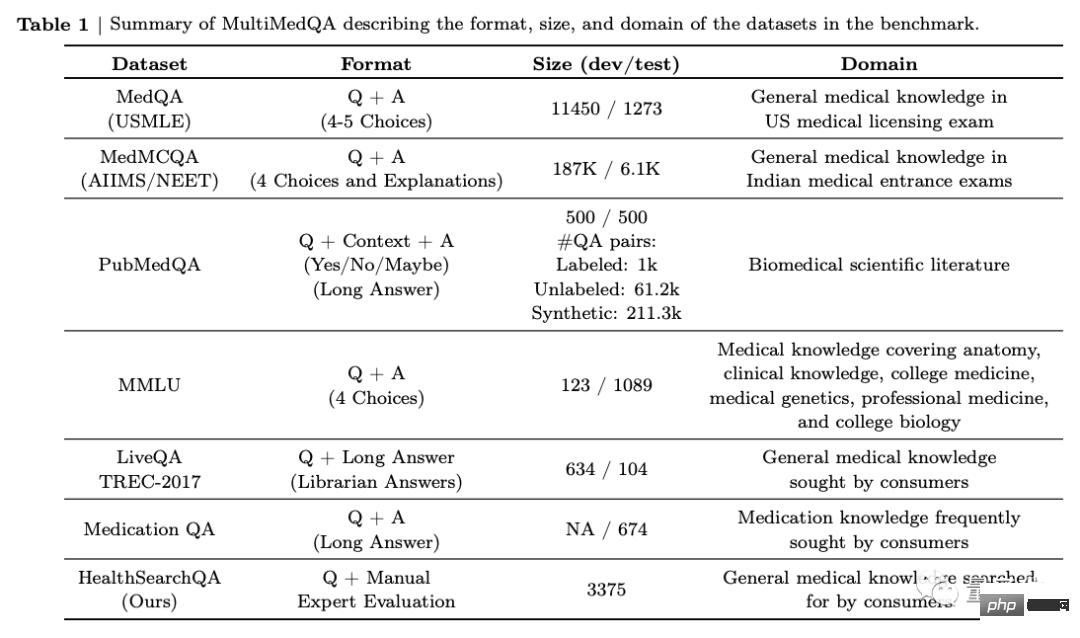 여기에는 건강 검진, 의학 연구, 소비자 의약품 문제가 포함됩니다.
여기에는 건강 검진, 의학 연구, 소비자 의약품 문제가 포함됩니다.
그런 다음 팀은 MultiMedQA를 사용하여 PaLM(5,400억 매개변수)과 미세 조정된 지침을 갖춘 변형 Flan-PaLM을 평가했습니다. 예를 들어 작업 수, 모델 크기 및 사고 체인 데이터 사용 전략을 확장합니다.
FLAN은 Google Research가 작년에 제안한 미세 조정 언어 네트워크로, 일반적인 NLP 작업에 더 적합하도록 모델을 미세 조정하고 명령어 조정을 사용하여 모델을 학습합니다.
Flan-PaLM은 MedQA, MedMCQA, PubMedQA 및 MMLU와 같은 여러 벤치마크에서 최적의 성능을 달성한 것으로 나타났습니다. 특히 MedQA(USMLE) 데이터 세트는 이전 SOTA 모델보다 17% 이상 우수한 성능을 보였습니다.
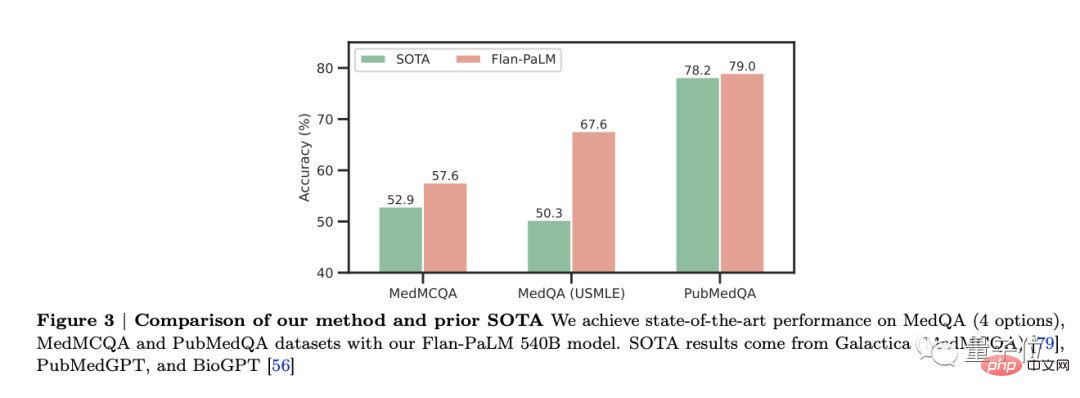 이 연구에서는 80억 개의 매개변수, 620억 개의 매개변수, 5,400억 개의 매개변수 등 다양한 크기의 세 가지 PaLM 및 Flan-PaLM 모델 변형이 고려되었습니다.
이 연구에서는 80억 개의 매개변수, 620억 개의 매개변수, 5,400억 개의 매개변수 등 다양한 크기의 세 가지 PaLM 및 Flan-PaLM 모델 변형이 고려되었습니다.
그러나 Flan-PaLM은 여전히 특정 한계를 갖고 있으며 소비자 의료 문제를 처리하는 데 제대로 기능하지 않습니다.
이 문제를 해결하고 Flan-PaLM을 의료 분야에 더 적합하게 만들기 위해 지침 프롬프트를 조정하여 Med-PaLM 모델이 탄생했습니다.
 Δ예: 신생아 황달이 사라지는 데 얼마나 걸리나요?
Δ예: 신생아 황달이 사라지는 데 얼마나 걸리나요?
팀은 먼저 MultiMedQA 무료 답변 데이터 세트(HealthSearchQA, MedicationQA, LiveQA)에서 몇 가지 예를 무작위로 선택했습니다.
그런 다음 5명의 임상의 팀이 모범적인 답변을 제공하도록 하세요. 이들 임상의는 미국과 영국에 있으며 일차 진료, 수술, 내과, 소아과에 대한 전문 지식을 갖추고 있습니다. 마지막으로 지침 프롬프트 튜닝 교육을 위해 HealthSearchQA, MedicationQA 및 LiveQA에 40개의 예제가 남았습니다.
 다양한 업무는 인간의 의사 수준에 가깝습니다
다양한 업무는 인간의 의사 수준에 가깝습니다
Med-PaLM의 최종 효과를 검증하기 위해 연구진은 위에서 언급한 MultiMedQA에서 소비자 의료 질문 140개를 추출했습니다.
그 중 100개는 HealthSearchQA 데이터 세트에서, 20개는 LiveQA 데이터 세트에서, 20개는 MedicationQA 데이터 세트에서 가져왔습니다.
여기에는 Med-PaLM을 생성하기 위한 지침 프롬프트를 조정하는 데 원래 사용된 문제가 포함되지 않는다는 점을 언급할 가치가 있습니다.
그들은 Flan-PaLM과 Med-PaLM에게 각각 140개의 질문에 대한 답변을 생성하도록 요청하고 이에 대한 답변을 위해 전문 임상의 그룹을 초대했습니다.
아래 사진을 예시로 들어보세요. "심한 귀 통증이 무엇을 뜻하나요?"라고 물으면 Med-PaLM에서는 환자가 감염될 수 있는 질병을 나열할 뿐만 아니라, 다음과 같은 경우에는 진료를 받는 것이 좋습니다. 다음과 같은 증상이 있습니다.
귀 통증은 중이염(중이염), 외이염(귀 감염) 및 귀지 매복을 포함한 여러 가지 기본 질환의 징후일 수 있습니다. 또한 뇌종양이나 뇌졸중과 같은 더 심각한 상태의 징후일 수도 있습니다.
며칠 이상 지속되는 심한 귀 통증이 있거나 현기증, 발열, 안면 허약, 마비 등 귀 통증에 수반되는 다른 증상이 있는 경우 의사의 진료를 받아야 합니다. 의사는 통증의 원인을 파악하고 적절한 치료를 제공할 수 있습니다.
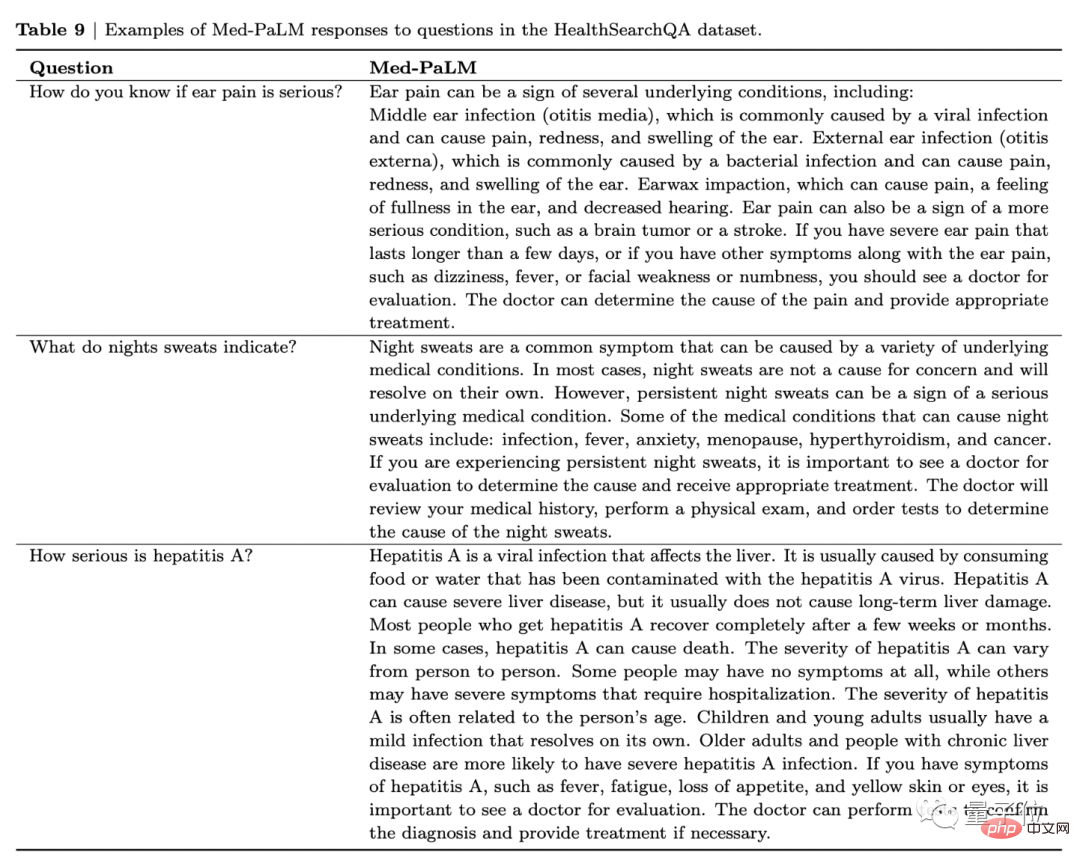
이런 방식으로 연구자들은 평가를 위해 미국, 영국, 인도의 9명의 임상의에게 이 세 가지 답변 세트를 익명으로 제공했습니다.
과학 상식으로 볼 때 Med-PaLM과 인간 의사 모두 92% 이상의 정확도를 보이는 반면 Flan-PaLM은 61.9%의 정확도를 보이는 것으로 나타났습니다.

일반적으로 Med-PaLM은 이해, 검색, 추론 능력 측면에서 거의 인간 의사 수준에 도달했으며 둘 사이의 차이는 거의 동일하지만 Flan-PaLM도 맨 아래에서 수행되었습니다.

답변의 완전성 측면에서 Flan-PaLM의 답변은 47.2%의 중요한 정보가 누락된 것으로 간주되지만 Med-PaLM의 답변은 15.1%의 답변만이 누락된 것으로 간주되어 크게 향상되었습니다. 인간 의사와의 거리를 단축합니다.

그러나 답변이 길어지면 잘못된 내용이 포함될 위험이 높아지는 Med-PaLM의 답변이 18.7%에 달해 3개 답변 중 가장 높습니다.

답변의 잠재적인 피해를 고려하면 Flan-PaLM의 답변 중 29.7%가 잠재적으로 유해한 것으로 간주되었으며 Med-PaLM의 답변은 5.9%로 떨어졌고 인간 의사의 답변은 5.7%로 가장 낮았습니다.

또한, Med-PaLM의 답변 중 0.8%만이 인간에 비해 편향된 것으로 나타났습니다. 의사의 경우 1.4%, Flan-PaLM의 경우 7.9%였습니다.

마지막으로 연구원들은 5명의 비전문 사용자를 초대하여 이 세 가지 답변 세트의 실용성을 평가했습니다. Flan-PaLM의 답변 중 60.6%만이 유용한 것으로 간주되었으며, Med-PaLM의 경우 그 수치가 80.3%로 증가했으며, 인간 의사의 경우 가장 높은 91.1%가 도움이 되었습니다.

위의 모든 평가를 종합해보면, 명령 프롬프트 조정이 성능 향상에 상당한 영향을 미치는 것을 알 수 있습니다. 140개의 소비자 의료 문제에서 Med-PaLM의 성능은 거의 인간 의사 수준을 따라잡았습니다.
팀
이 논문의 연구팀은 Google과 DeepMind에서 왔습니다.

구글헬스는 지난해 대규모 정리해고와 조직개편에 이어 의료계에서도 대대적인 출범을 했다고 할 수 있다.
구글 AI 수장인 제프 딘까지 강력 추천을 하러 나왔어요!

업계 관계자 분들도 읽고 칭찬해 주셨는데요.
임상 지식은 명확한 정답이 없는 경우가 많고, 환자와의 대화도 필요한 복잡한 분야입니다.
이번 Google DeepMind의 새 모델은 LLM을 완벽하게 적용한 것입니다.

얼마 전 다른 팀이 USMLE를 통과했다는 사실을 언급할 가치가 있습니다.
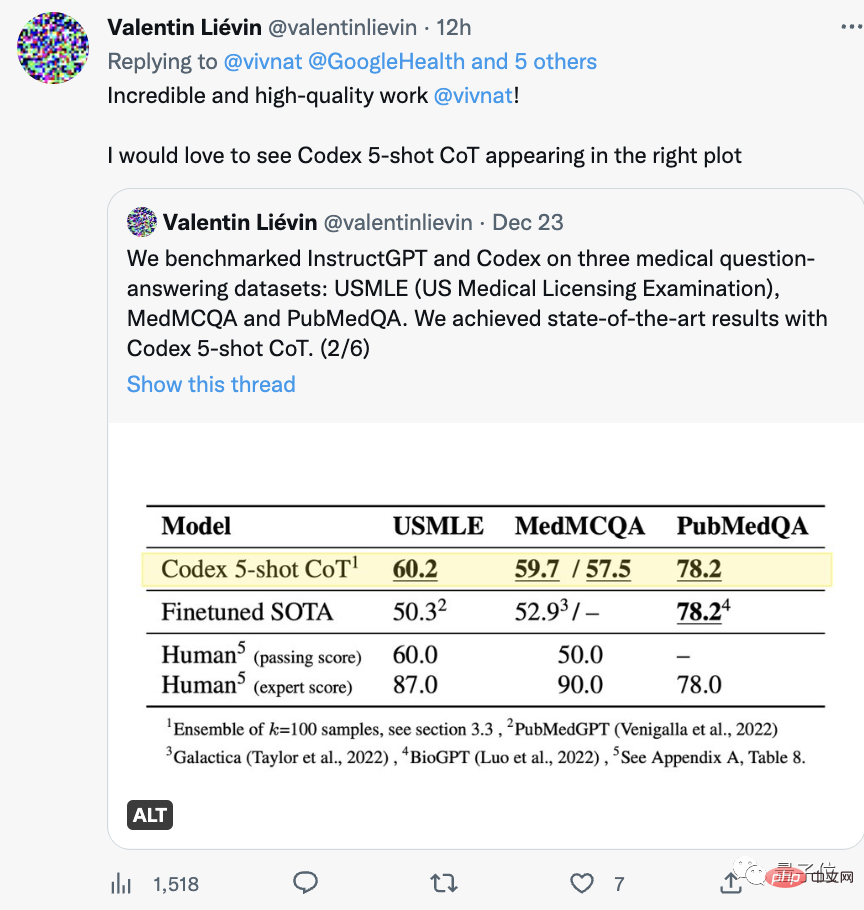
올해는 PubMed GPT, DRAGON, Meta’s Galactica 등 대형 모델의 대거 등장이 이어지며 전문 시험에서 연이어 신기록을 세웠습니다.

의료 AI는 작년에 나쁜 소식이었다는 것을 상상하기 어려울 정도로 번영하고 있습니다. 당시 구글의 의료 AI 관련 혁신 사업은 아직 시작되지도 않았다.
지난해 6월 미국 언론 BI를 통해 위기에 처해 대규모 정리해고와 개편을 겪어야 했다는 사실이 폭로됐다. 2018년 11월 Google Health 부서가 처음 설립되었을 때 매우 번영했습니다.
구글뿐만이 아닙니다. 다른 유명 기술 기업의 의료 AI 사업도 구조 조정과 인수를 경험했습니다.
Google DeepMind에서 공개한 대형 의료 모델을 읽으신 후, 의료 AI 발전에 대해 낙관하시나요?
논문 주소: https://arxiv.org/abs/2212.13138
참조 링크: https://twitter.com/vivnat/status/1607609299894947841
위 내용은 AI 역사상 최고 점수! 구글의 대규모 모델은 미국 의사면허 시험 문제에서 새로운 기록을 세웠고, 과학적 지식 수준은 인간 의사와 맞먹는다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!