
데이터 과학을 위한 9가지 매우 유용한 Python 라이브러리

- PHPz앞으로
- 2023-04-17 09:25:081157검색
이 기사에서는 panda, scikit-learn 및 matplotlib와 같은 보다 일반적인 라이브러리 외에 데이터 과학 작업을 위한 일부 Python 라이브러리를 살펴보겠습니다. panda 및 scikit-learn과 같은 라이브러리는 기계 학습 작업에 일반적으로 사용되지만 이 분야의 다른 Python 제품을 이해하는 것은 항상 유익합니다.
1. Wget
인터넷에서 데이터를 추출하는 것은 데이터 과학자의 중요한 작업 중 하나입니다. Wget은 인터넷에서 비대화형 파일을 다운로드하는 데 사용할 수 있는 무료 유틸리티입니다. HTTP, HTTPS 및 FTP 프로토콜은 물론 HTTP 프록시를 통한 파일 검색도 지원합니다. 비대화형이므로 사용자가 로그인하지 않아도 백그라운드에서 작동할 수 있습니다. 따라서 다음에 웹사이트나 페이지의 모든 이미지를 다운로드하고 싶을 때 wget이 도움을 드릴 수 있습니다.
설치:
$ pip install wget
예:
import wget url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3' filename = wget.download(url) 100% [................................................] 3841532 / 3841532 filename 'razorback.mp3'
2. Pendulum
Python에서 날짜와 시간을 처리할 때 좌절감을 느끼는 분들을 위해 Pendulum이 적합합니다. 날짜/시간 작업을 단순화하는 Python 패키지입니다. 이는 Python의 기본 클래스를 간단히 대체합니다. 더 깊은 학습을 위해서는 문서를 참조하세요.
설치:
$ pip install pendulum
예:
import pendulum dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto') dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver') print(dt_vancouver.diff(dt_toronto).in_hours()) 3
3. imbalanced-learn
대부분의 분류 알고리즘은 각 클래스의 샘플 수가 기본적으로 동일할 때, 즉 데이터 균형이 같아야 할 때 가장 잘 작동함을 알 수 있습니다. 유지 . 그러나 실제 사례의 대부분은 불균형한 데이터 세트로, 이는 머신러닝 알고리즘의 학습 단계와 후속 예측에 큰 영향을 미칩니다. 다행히 이 라이브러리는 이 문제를 해결하도록 설계되었습니다. 이는 scikit-learn과 호환되며 scikit-lear-contrib 프로젝트의 일부입니다. 다음에 불균형 데이터 세트가 발견되면 이 방법을 사용해 보세요.
설치:
$ pip install -U imbalanced-learn # 或者 $ conda install -c conda-forge imbalanced-learn
예:
사용법과 예는 설명서를 참조하세요.
4. FlashText
NLP 작업에서 텍스트 데이터를 정리하려면 문장의 키워드를 바꾸거나 문장에서 키워드를 추출해야 하는 경우가 많습니다. 일반적으로 이는 정규식을 사용하여 수행할 수 있지만 검색되는 용어의 수가 수천 개에 달하면 번거로울 수 있습니다. Python의 FlashText 모듈은 FlashText 알고리즘을 기반으로 하며 이러한 상황에 적합한 대안을 제공합니다. FlashText의 가장 큰 장점은 검색어 수에 관계없이 런타임이 동일하다는 것입니다. 여기에서 자세한 내용을 알아볼 수 있습니다.
설치:
$ pip install flashtext
예:
키워드 추출
from flashtext import KeywordProcessor
keyword_processor = KeywordProcessor()
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
['New York', 'Bay Area']키워드 교체
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
'I love New York and NCR region.'
Fuzzywuzzy5. fuzzywuzzy
이 라이브러리 이름이 이상하게 들리지만 문자열 일치에 관해서는 fuzzywuzzy가 매우 유용한 라이브러리입니다. 문자열 일치 정도, 토큰 일치 정도 계산 등의 작업을 쉽게 구현할 수 있으며, 서로 다른 데이터베이스에 저장된 레코드도 쉽게 일치시킬 수 있습니다.
설치:
$ pip install fuzzywuzzy
예:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# 简单匹配度
fuzz.ratio("this is a test", "this is a test!")
97
# 模糊匹配度
fuzz.partial_ratio("this is a test", "this is a test!")
100GitHub 저장소에서 더 흥미로운 예를 찾을 수 있습니다.
6. PyFlux
시계열 분석은 기계 학습 분야에서 가장 일반적인 문제 중 하나입니다. PyFlux는 시계열 문제를 해결하기 위해 구축된 Python의 오픈 소스 라이브러리입니다. 라이브러리에는 ARIMA, GARCH 및 VAR 모델을 포함하되 이에 국한되지 않는 최신 시계열 모델의 훌륭한 컬렉션이 있습니다. 간단히 말해서, PyFlux는 시계열 모델링에 대한 확률론적 접근 방식을 제공합니다. 시도해 볼 가치가 있습니다.
Installation
pip install pyflux
Examples
자세한 사용법과 예시는 공식 문서를 참고하세요.
7. Ipyvolume
결과 표시도 데이터 과학에서 중요한 측면입니다. 결과를 시각화할 수 있다는 것은 큰 장점이 될 것입니다. IPyvolume은 Jupyter 노트북에서 3D 볼륨과 그래픽(예: 3D 산점도 등)을 시각화할 수 있고 약간의 구성만 필요로 하는 Python 라이브러리입니다. 하지만 아직은 1.0 이전 버전 단계입니다. 설명하기에 더 적절한 비유는 다음과 같습니다. IPyvolume의 volshow는 matplotlib의 imshow가 2차원 배열에 유용한 것처럼 3차원 배열에 유용합니다. 여기에서 더 많은 정보를 확인할 수 있습니다. R PIPre
$ pip install ipyvolumeE를 사용하여 Conda/Anaconda
rreee
를 사용합니다. 예 애니메이션 바디 드로잉 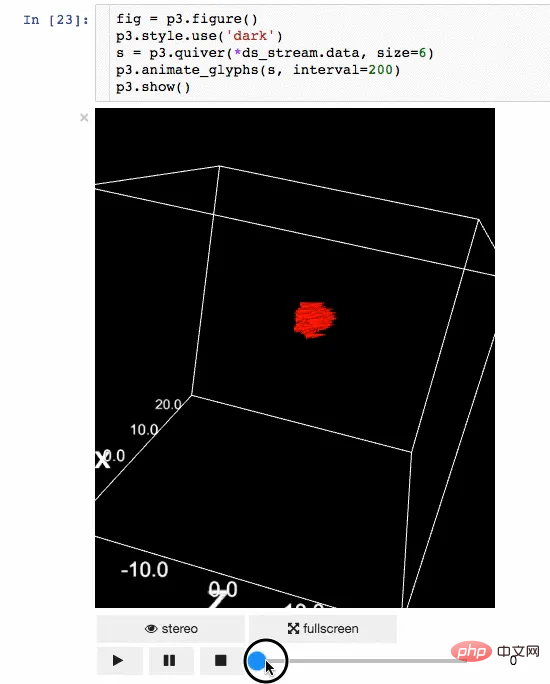
8. Dash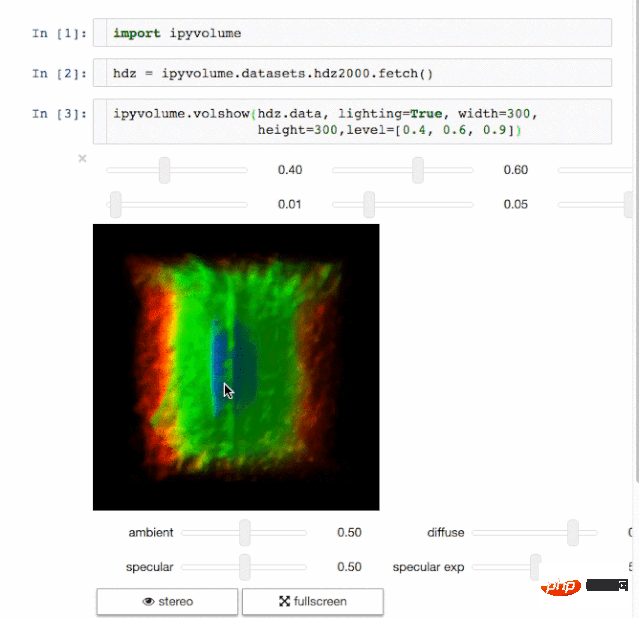
$ conda install -c conda-forge ipyvolume예 아래 예는 드롭다운 기능을 갖춘 대화형 차트를 보여줍니다. 사용자가 드롭다운 메뉴에서 값을 선택하면 애플리케이션 코드가 Google Finance의 데이터를 Panda DataFrame으로 동적으로 내보냅니다.
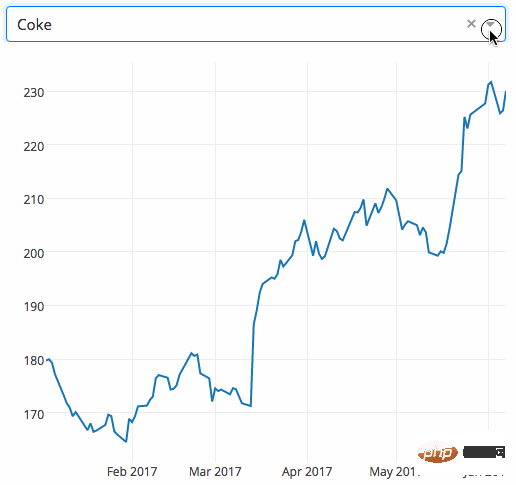
九、Gym
OpenAI 的 Gym 是一款用于增强学习算法的开发和比较工具包。它兼容任何数值计算库,如 TensorFlow 或 Theano。Gym 库是测试问题集合的必备工具,这个集合也称为环境 —— 你可以用它来开发你的强化学习算法。这些环境有一个共享接口,允许你进行通用算法的编写。
安装
pip install gym
例子这个例子会运行CartPole-v0环境中的一个实例,它的时间步数为 1000,每一步都会渲染整个场景。
总结
以上这些有用的数据科学 Python 库都是我精心挑选出来的,不是常见的如 numpy 和 pandas 等库。如果你知道其它库,可以添加到列表中来,请在下面的评论中提一下。另外别忘了先尝试运行一下它们。
위 내용은 데이터 과학을 위한 9가지 매우 유용한 Python 라이브러리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!