
2세대 GAN 네트워크의 등장? DALL·E Mini의 그래픽은 외국인들이 열광할 정도로 끔찍합니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-15 23:52:01784검색
요즘 Google, OpenAI 등 주요 기업에서 제작하는 텍스트 기반 그래프 모델은 흥미로운 뉴스 기자들의 생명선이자 밈 애호가들에게는 오랜 가뭄의 꿀물입니다. 단어를 입력하면, 피곤하거나 귀찮은 일 없이 사람들의 관심을 끌 수 있는 아름답고 재미있는 다양한 그림을 생성할 수 있습니다. 따라서 DALL·E 시리즈와 Imagens는 식량과 의복, 장기 가뭄이라는 본질적인 속성을 가지고 있습니다. 이는 제한된 범위에서만 사용할 수 있으며 언제든지 무제한으로 배포할 수 있는 혜택이 아닙니다. 2022년 6월 중순, Hugging Face Company는 사용하기 쉽고 간단한 버전의 DALL·E 인터페이스인 DALL·E Mini를 전체 네트워크의 모든 사용자에게 무료로 공개했습니다. 예상대로 또 다른 물결을 일으켰습니다. 다양한 소셜 미디어 웹사이트의 창조 트렌드에 대한 빅 뉴스.

DALL·E Mini 제작 트렌드: 재미있고 무섭습니다
이제 다양한 소셜 미디어의 사람들이 다음과 같이 말했습니다. DALL·E Mini를 플레이하는 것은 한동안 재미있고, 계속 플레이해도 재미있습니다. 전혀 멈추지 마세요. "스케이트보드 위의 똥"처럼, 마찰과 마찰은 악마의 속도처럼요.
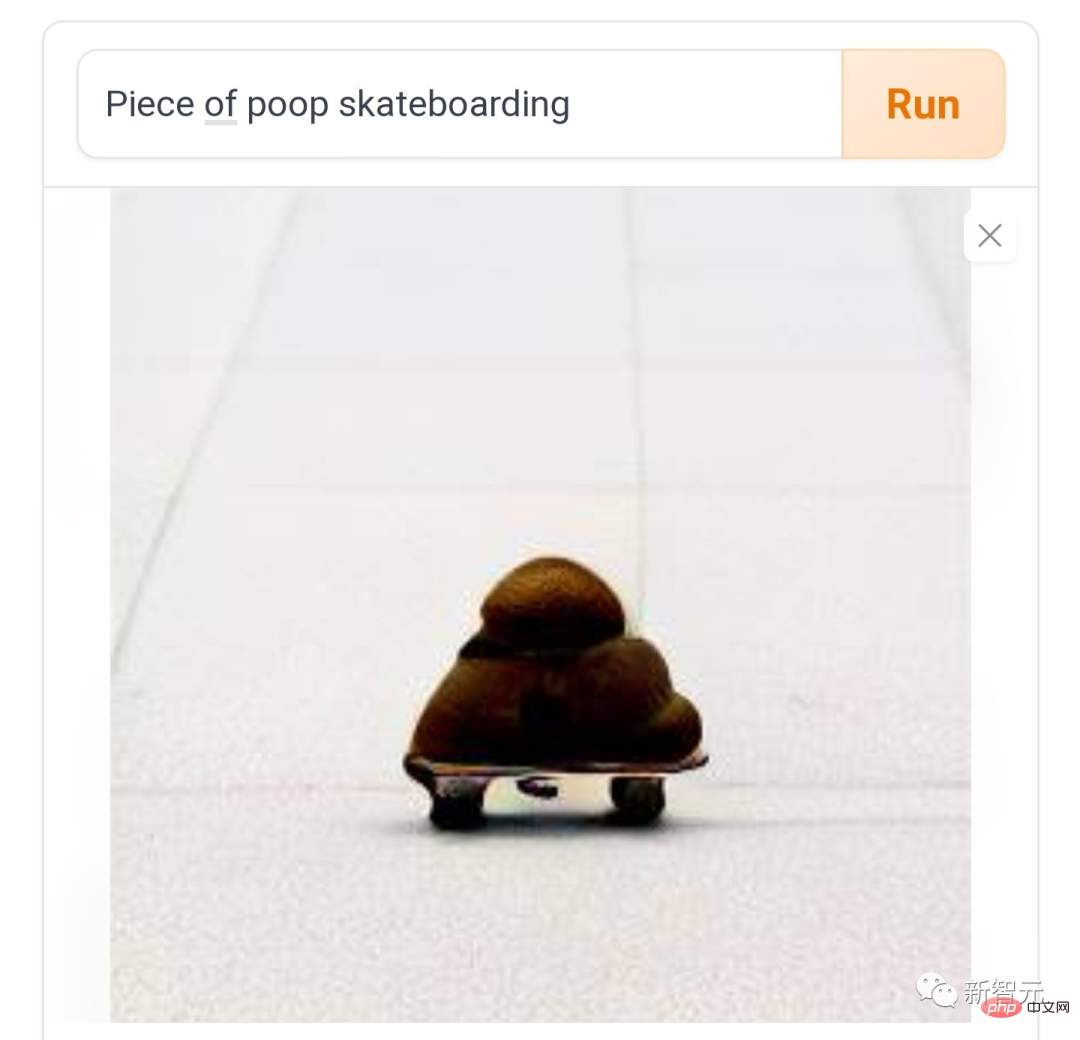
어떤 사람들은 종의 경계를 허무는 "코기 얼룩말"과 같은 "정상적인 창조물"을 만드는 것을 좋아합니다.
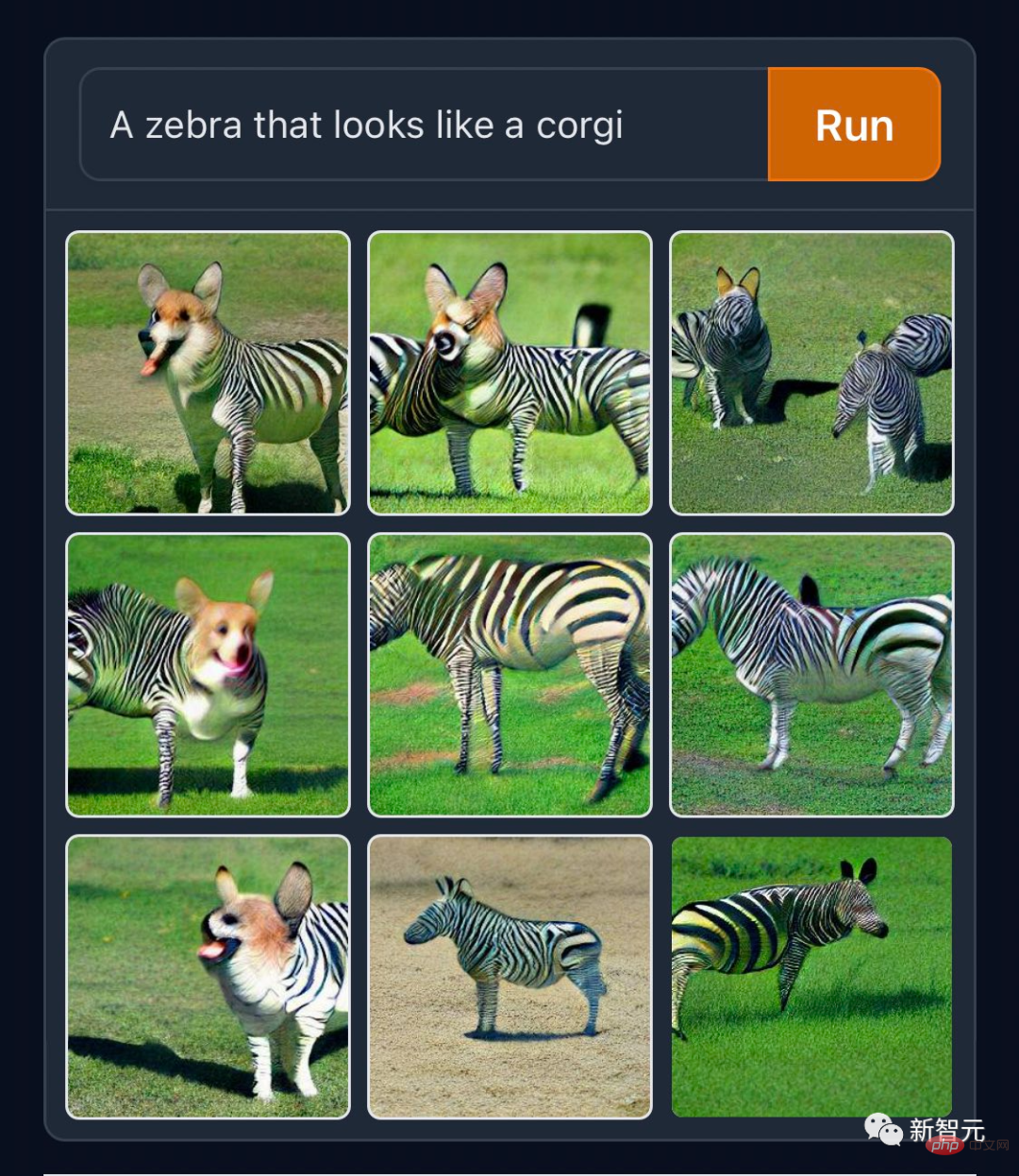
고대 공무원들이 이런 재료를 가지고 있었다면 아프리카 기린을 신화 속의 짐승 기린으로 만들기 위해 그토록 열심히 일하지 않아도 되었을 것입니다. GitHub의 코더들은 자신의 직업에 충실하며 공식 트위터에 "컴퓨터를 이용한 다람쥐 프로그래밍"이라는 생성된 작업을 게시했습니다.

"고질라의 법정 스케치"는 영어권 신문에서 일반에 공개되지 않는 판례 보고서의 스케치 스타일과 정말 흡사하다고 말씀드리고 싶습니다.

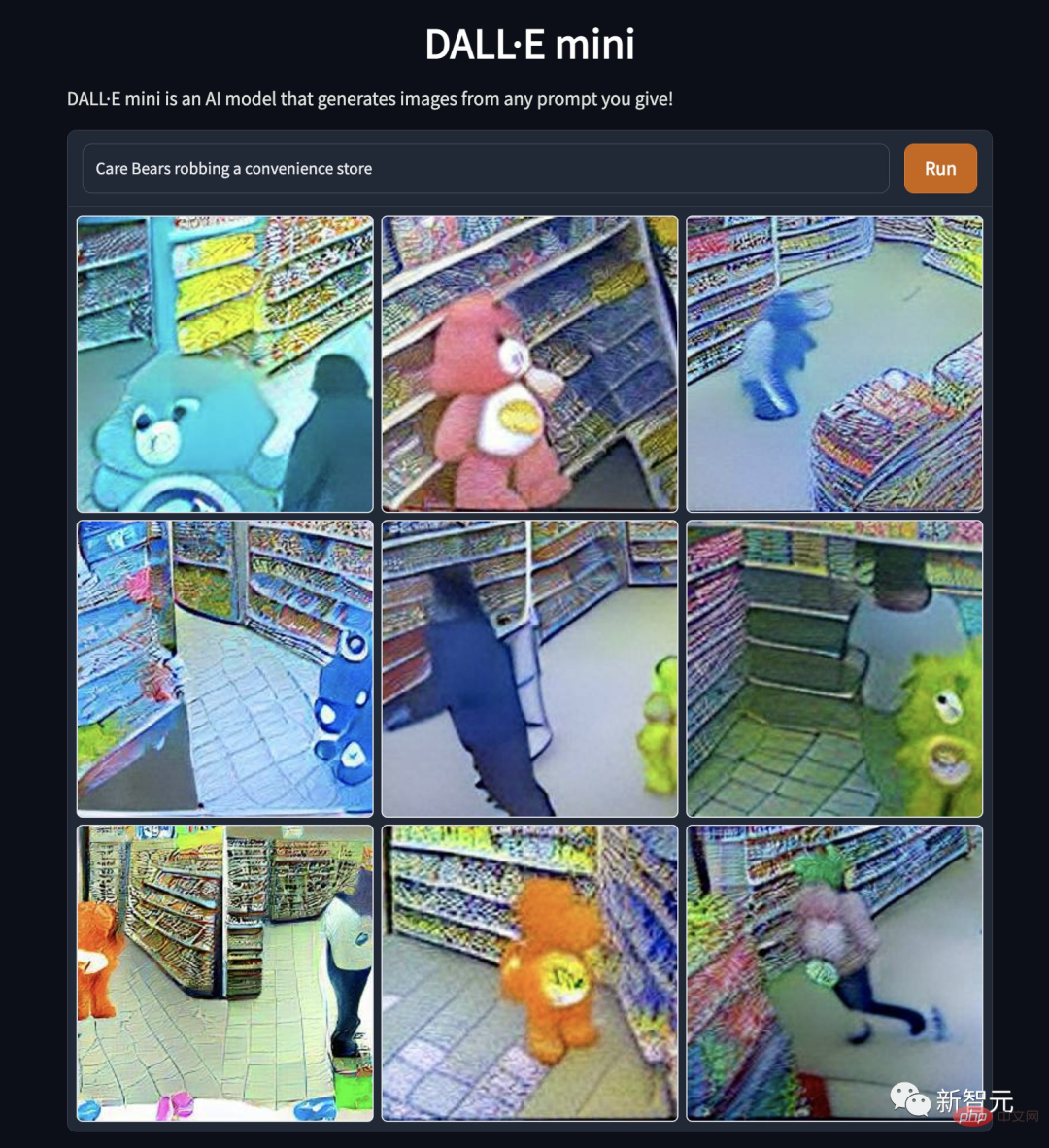
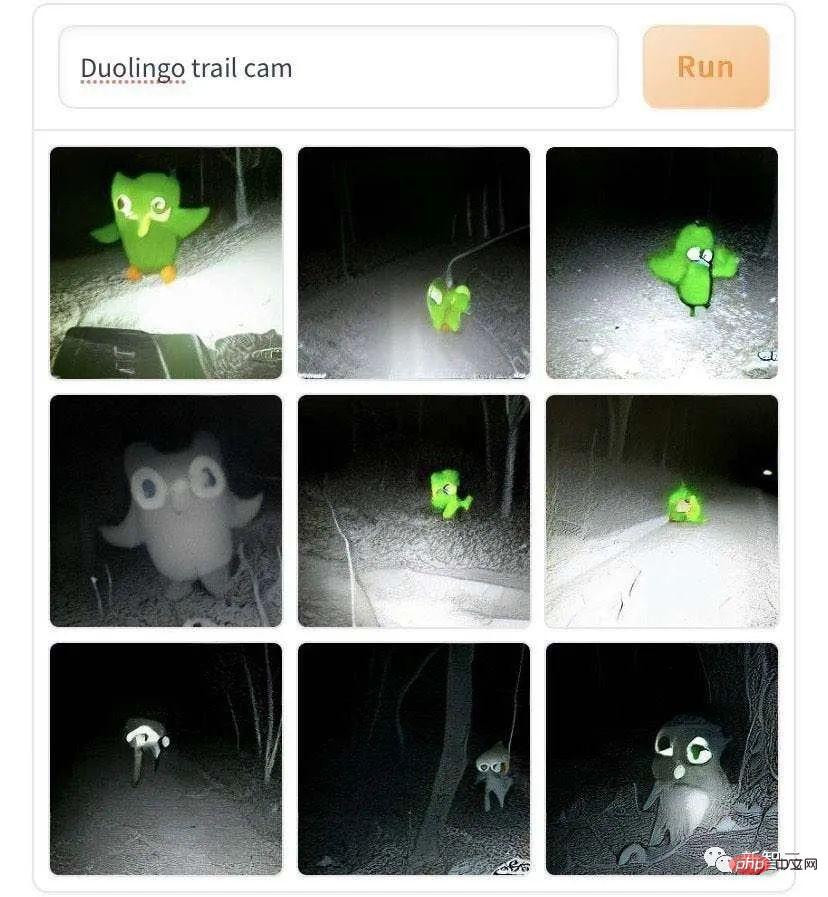
"케어베어가 편의점을 털다". 만화 아이돌이 왜 이렇게 추락한 걸까? 곰의 본성이 왜곡된 것인지, 도덕성이 상실된 것인지… 와일드 트레일 "이미지에도 뛰어난 성과가 있습니다. "야생의 길을 걷는 작은 공룡, 카메라에 포착됐다"
"야생의 길을 걷고 있는 듀오링고 앵무새 트레이드마크, 카메라에 포착" 입니다.

DALL·E Mini는 신화 속 짐승의 걷는 사진을 제작했는데 뒷모습이 너무 외롭고 쓸쓸해요. 하지만 이는 AI가 시뮬레이션한 저조도 사진 효과일 수 있습니다. 편집부 사람들도 모두 "풀과 진흙 말을 타고 길을 걷는다"고 흉내를 내었고 톤이 훨씬 더 밝아졌습니다.
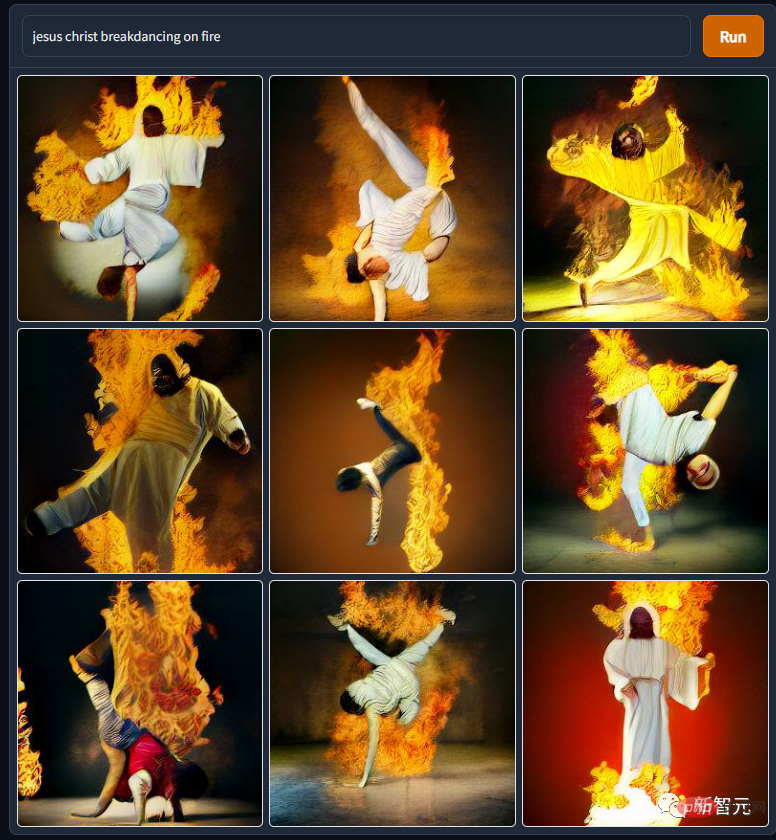
DALL·E Mini가 만들어내는 신과 인간의 이미지는 신화 속 짐승의 이미지보다 나쁘지 않습니다. 예를 들어, 이 "예수님의 불 같은 브레이크 댄스" 사진에서 그분의 몸이 이렇게 유연한지 정말 몰랐습니다. 여러 피트니스 웹사이트에 "주님과 함께 하는 스트레칭" 광고가 나오는 데에는 이유가 있는 것 같습니다.
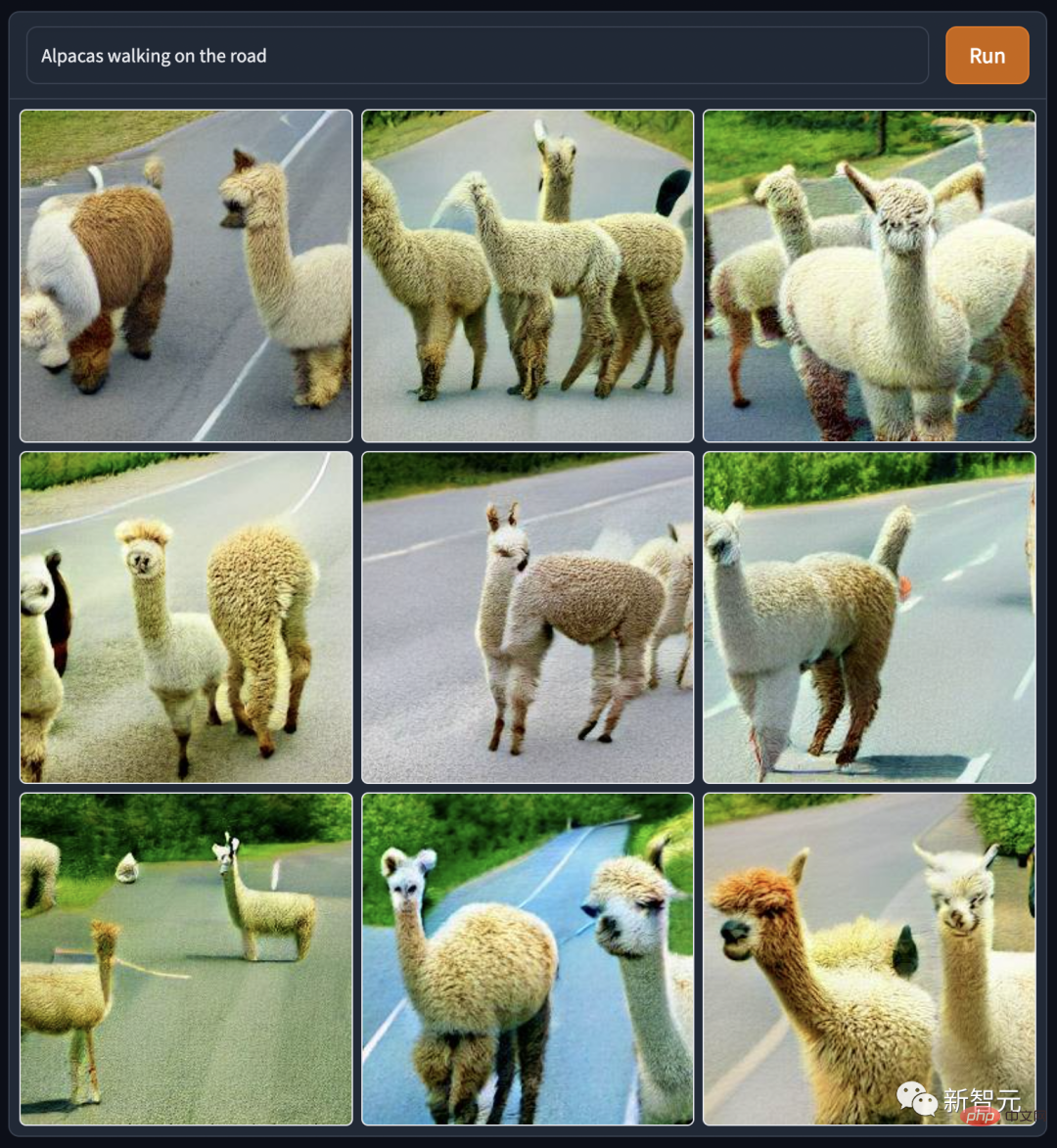
그리고 이 "스테인드 글라스 위의 래퍼 구예"는 정말 교회 성상 창문 스타일과 인상파 그림이 맞나요?
DALL·E Mini를 사용하여 영화 및 TV 산업에서 캐릭터를 스푸핑하는 것이 이제 트렌드가 되었습니다. 다음은 스타워즈 세계관의 "R2D2's Baptism"입니다. 아마도 스타워즈 세계의 물리 및 화학 법칙은 현실 세계의 법칙과 다를 것입니다. 로봇은 물에 노출된 후에도 전기가 새지 않으며 녹슬지도 않습니다.

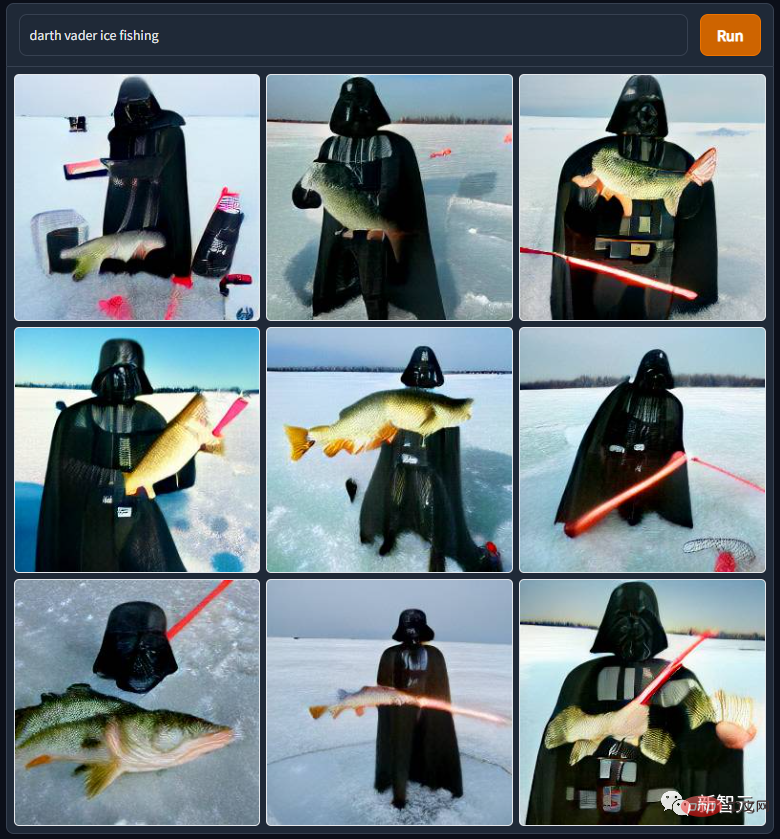
"다스 베이더 얼음낚시"도 스타워즈 세계관에 나오는데, 다스 베이더 씨는 정말 비참해요. 주인에게 해킹당해 화산의 용암 속에서 목욕을 하게 된 그는 장애인이 된 뒤 인공호흡기를 이용해 포스를 터득한 뒤 땅바닥으로 내려앉았다. 에스키모인들과 사업을 경쟁하기 위해...
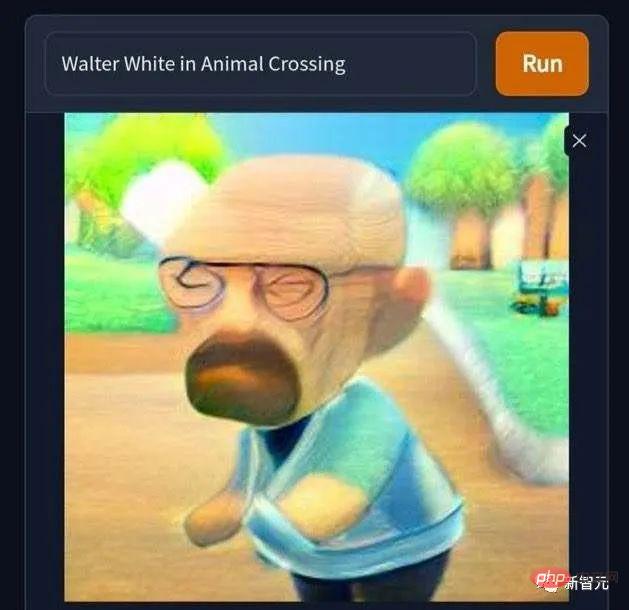
"월터 화이트가 우연히 동물의 숲의 세계에 들어갔다"는 사진도 있습니다. 대머리에 외롭고 절박한 마약 왕이 갑자기 귀여워집니다. . Nintendo가 2000년대에 실제로 동물의 숲을 출시하지 않은 것은 유감입니다. 그렇지 않았다면 동물의 숲에서 가상 거래를 통해 돈을 버는 것이 푸른 얼음 모양의 실제 상품을 만들기 위해 열심히 일하는 것보다 훨씬 덜 번거롭고 문제가 없다는 것을 알았을 것입니다. 내 가족을 지원합니다. "음란물 거부~마약 거부~음란물, 도박, 약물 거부~"를 불러봅시다.
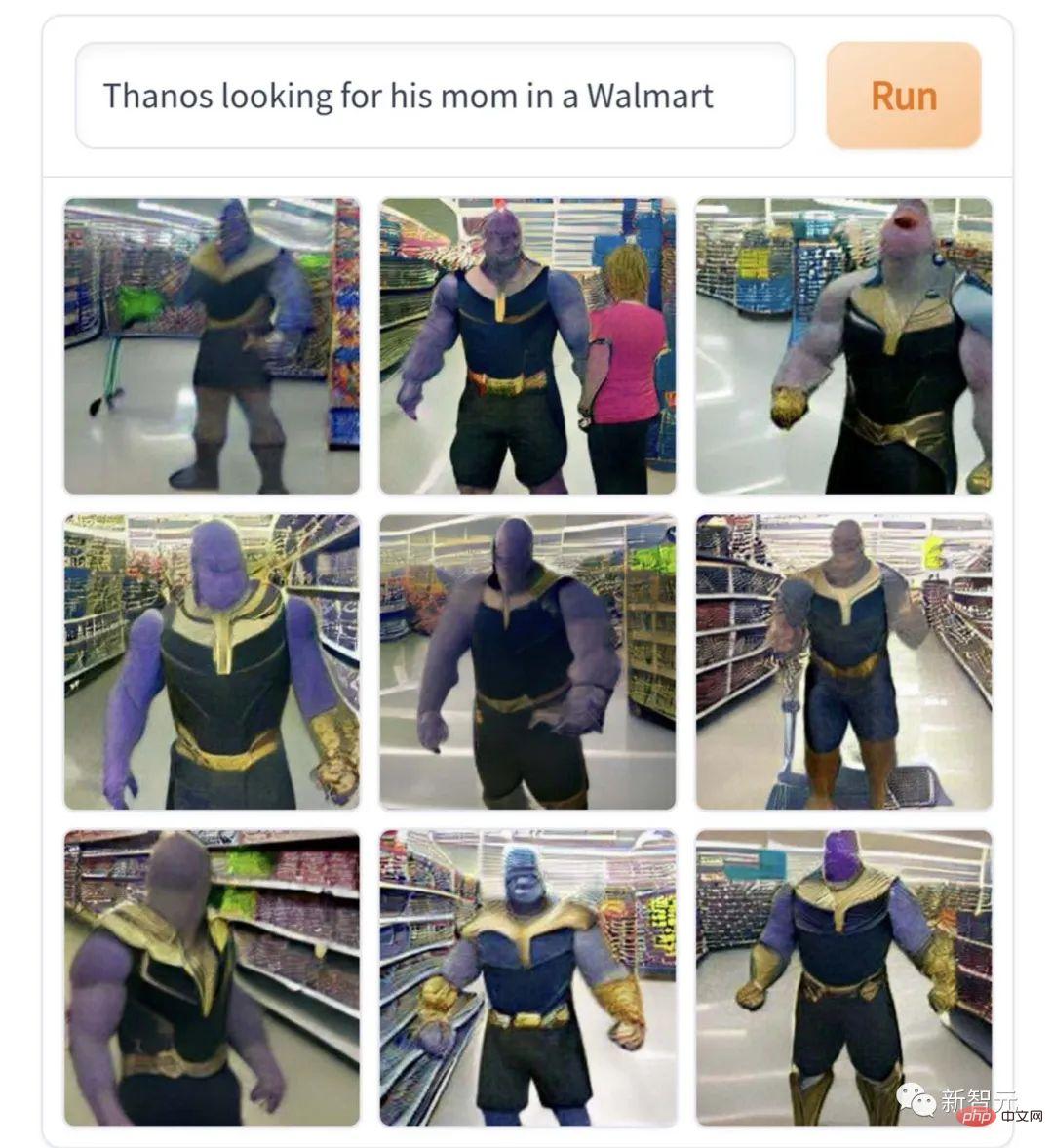
이 "슈퍼마켓에서 엄마를 찾는 타노스"는 캐릭터의 핵심에 딱 들어맞고 드라마에 대한 매우 전문적인 해석입니다. 불행하면 대량학살을 저지르게 되고, 동의하지 않으면 우주를 파괴하게 된다. 엄마를 찾지 못해 통곡하는 거대 아기의 캐릭터다.
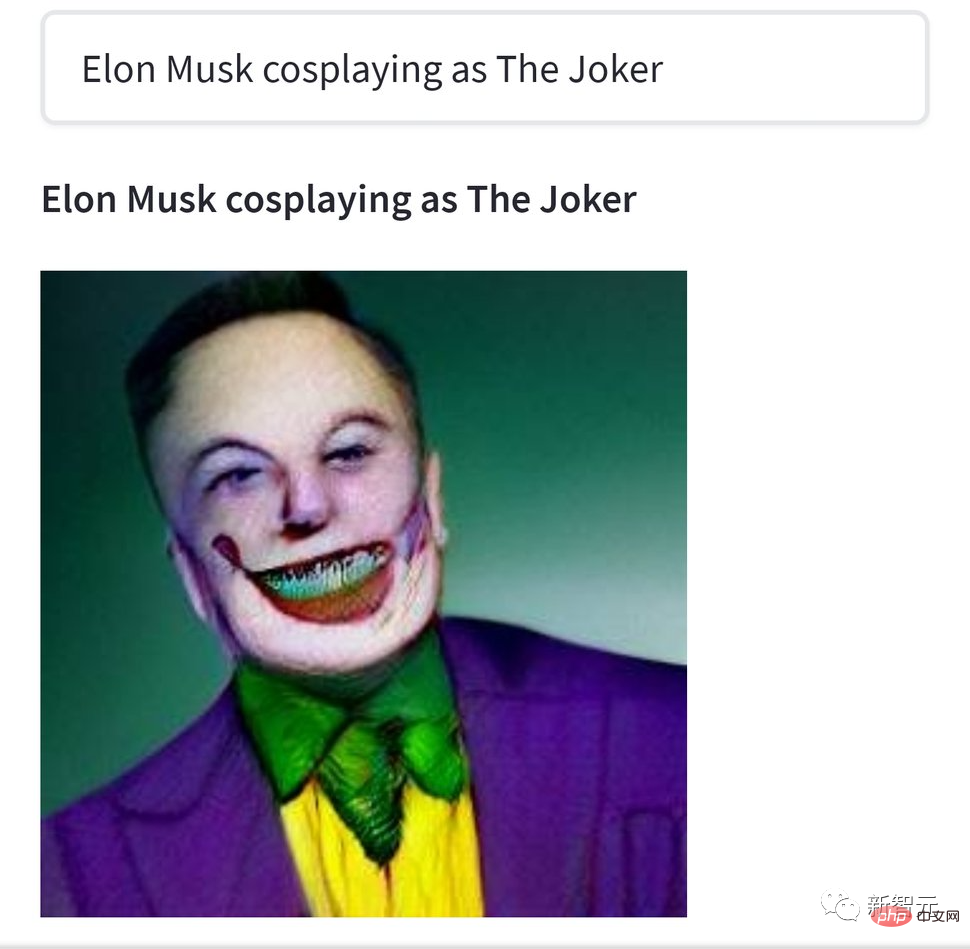
그런데 이 창작물들은 다 맛이 진한 크툴루 매니아들의 작품에 비하면 그냥 묽은 편이에요. 예를 들어, 이 그림 "Elon Musk는 깨진 광대를 연기합니다"는 조금 무섭습니다.
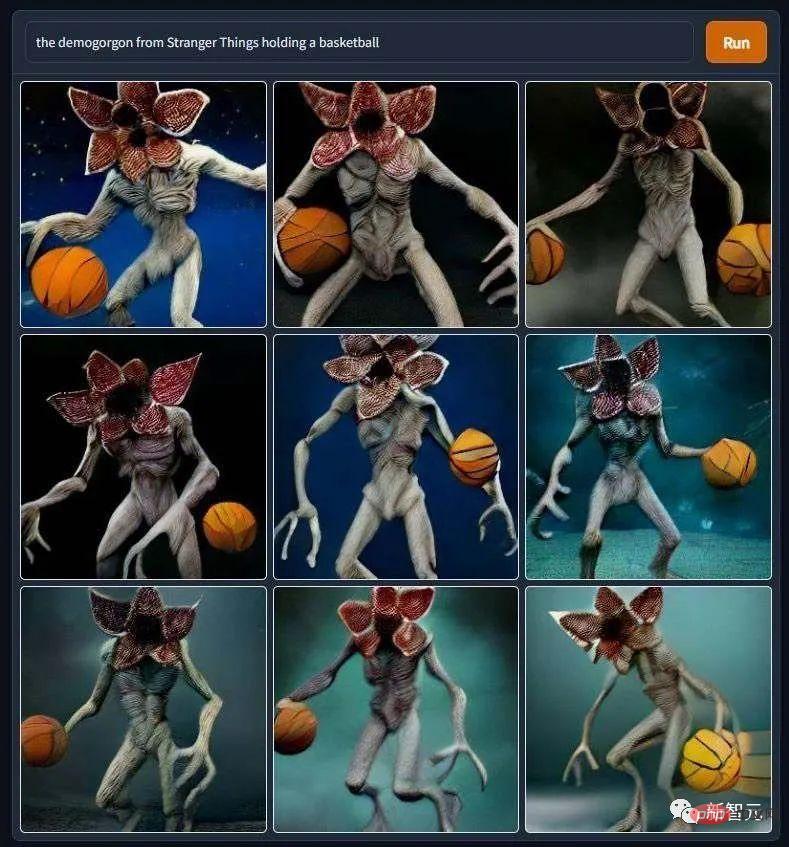
"The Devil Plays Basketball". 편집자는 이 사진을 본 후 정말 "Stranger Things"를 계속 따라갈 수 없었습니다. ∎ 다양한 시리즈의 공포 영화의 주인공도 작품에 나타납니다. "Masked Jason Devil Eats Burrito"와 같은 것과 같은 것입니다. "느릅나무 거리의 악몽 킬러가 파스타를 먹는다"... 패턴이 너무 무섭기 때문에 편집자는 DVD 시대의 공포영화를 보고 패닉에 빠질 정도로 겁에 질렸던 녹색 시절을 연상시킨다.
 "황금 아치에 죽음이 찾아온다"라는 그림도 있습니다. 이 글을 읽고 나면 앞으로 직장과 학교에 지각할 수 있습니까?
"황금 아치에 죽음이 찾아온다"라는 그림도 있습니다. 이 글을 읽고 나면 앞으로 직장과 학교에 지각할 수 있습니까?
 데모에는 코드가 60줄밖에 없습니다!
데모에는 코드가 60줄밖에 없습니다!
물론 DALL·E 시리즈의 역동성을 주의 깊게 따라가는 독자라면 DALL·E Mini와 이전 DALL·E 대형 모델에서 생성된 사진에 분명한 차이가 있다는 것을 알게 될 것입니다. DALL·E Mini, 얼굴이 원래 DALL·E에서 생성된 것보다 흐릿합니다. DALL·E Mini 프로젝트의 메인 개발자인 보리스 데이마(Boris Dayma)는 개발 노트에서 다음과 같이 설명했습니다. “이것은 사양을 줄인 사람 친화적인 버전입니다. 데모에는 코드가 60줄밖에 되지 않으며 기능이 약한 것은 정상입니다. .
 다음은 보리스 데이마(Boris Dayma)가 노트에 남긴 프로젝트에 대한 설명입니다. 먼저 프로젝트의 구체적인 구현을 살펴보겠습니다.
다음은 보리스 데이마(Boris Dayma)가 노트에 남긴 프로젝트에 대한 설명입니다. 먼저 프로젝트의 구체적인 구현을 살펴보겠습니다.
텍스트를 기반으로 해당 그림이 생성됩니다.
간단한 문장에 이어 우주로 번쩍이는 아보카도 안락의자~ 모델은 세 가지 데이터 세트를 사용합니다.
1. 3백만 개의 이미지와 캡션 쌍을 포함하는 "개념적 캡션 데이터 세트"
2. "의 Open AI 하위 집합" YFCC100M"에는 약 1,500만 개의 이미지가 포함되어 있습니다. 그러나 저장 공간 문제로 인해 저자는 200만 개의 이미지를 추가로 다운샘플링했습니다. 제목과 텍스트 설명을 동시에 태그로 사용하고 해당 HTML 태그, 줄 바꿈 및 추가 공백을 삭제하세요.
3. 1,200만 개의 이미지와 제목 쌍이 포함된 "개념적 12M".
교육 단계에서:
1. 먼저 이미지를 토큰 시퀀스로 변환하기 위해 이미지를 VQGAN 인코더로 인코딩합니다.
2. BART 인코더
3 BART 인코더의 출력과 VQGAN 인코더로 인코딩된 시퀀스 토큰은 BART 디코더로 함께 전송되며 그 목적은 다음 토큰 시퀀스를 예측하는 것입니다.
4. 손실 함수는 모델이 예측한 이미지 코딩 결과와 VQGAN 실제 이미지 코딩 간의 손실 값을 계산하는 데 사용되는 교차 엔트로피 손실입니다.
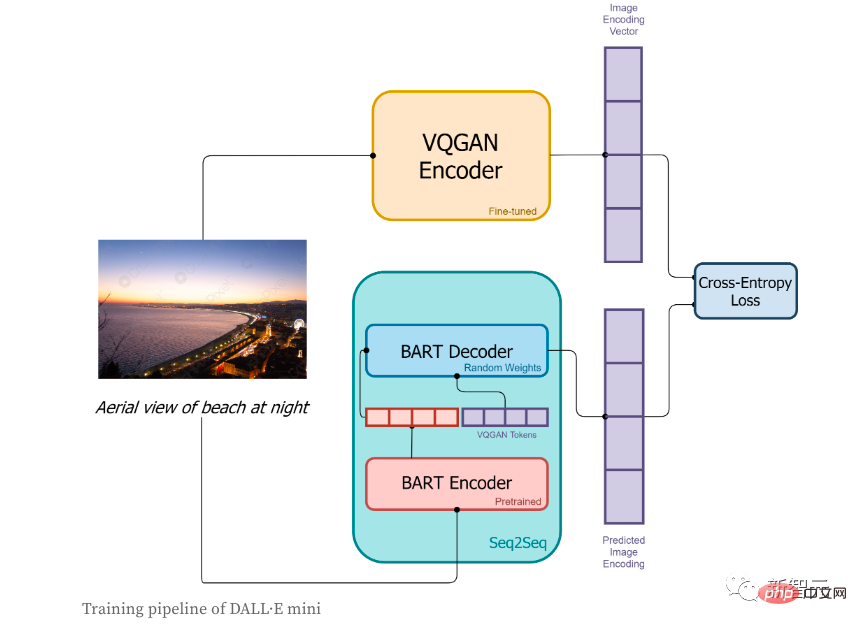
저자는 짧은 레이블만 사용하고 해당 이미지를 생성하려고 했습니다. 구체적인 프로세스는 다음과 같습니다.
1. 레이블은 BART 인코더를 통해 인코딩됩니다. 하나 시작 특수 시퀀스 플래그인 시작 플래그가 BART 디코더로 전송됩니다.
3. 다음 토큰의 BART 디코더가 예측한 분포를 기반으로 이미지 토큰이 순서대로 샘플링됩니다. 이미지 토큰 시퀀스는 디코딩을 위해 VQGAN 디코더로 전송됩니다.
다음으로 VQGAN 이미지 인코더와 디코더의 작동 방식을 살펴보겠습니다. Transformer 모델은 탄생 이후 NLP 분야뿐만 아니라 CV 분야의 컨볼루셔널 CNN 네트워크도 지배하고 있어 모든 사람에게 친숙할 것입니다. VQGAN을 사용하는 작성자의 목적은 이미지를 Transformer 모델에서 직접 사용할 수 있는 개별 토큰 시퀀스로 인코딩하는 것입니다. 픽셀 값 시퀀스의 사용으로 인해 이산 값의 임베딩 공간이 너무 커져서 궁극적으로 모델을 훈련하고 self-attention 레이어의 메모리 요구 사항을 충족하는 것이 극도로 어려워집니다.
VQGAN은 GAN의 인지 손실과 판별 손실을 결합하여 픽셀의 "코드북"을 학습합니다. 인코더는 "코드북"에 해당하는 인덱스 값을 출력합니다. 이미지는 토큰 시퀀스로 인코딩되므로 모든 Transformer 모델에서 사용할 수 있습니다. 이 모델에서 작성자는 압축 계수 f=16(4개 블록의 너비와 높이를 각각 2로 나눔)을 사용하여 크기 16,384의 어휘에서 이미지를 "16x16=256" 개별 토큰으로 인코딩합니다. 디코딩된 이미지는 256x256(각 측면이 16x16)입니다. VQGAN에 대한 보다 자세한 이해는 "고해상도 이미지 합성을 위한 Taming Transformers"를 참고하시기 바랍니다. 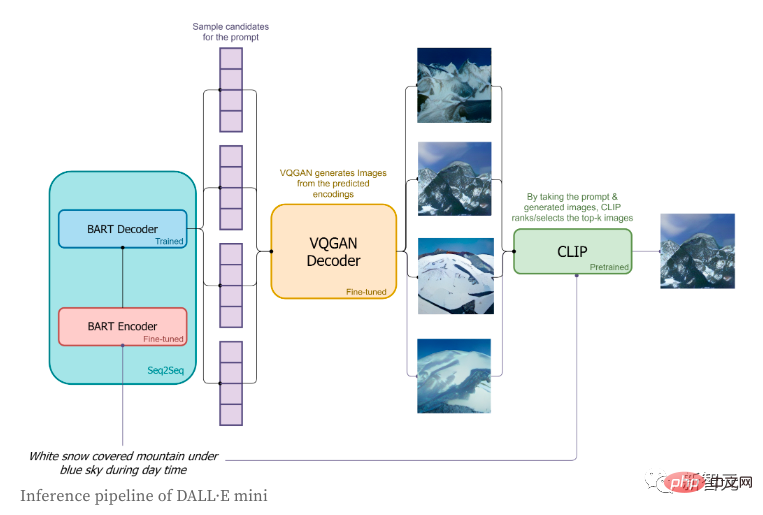
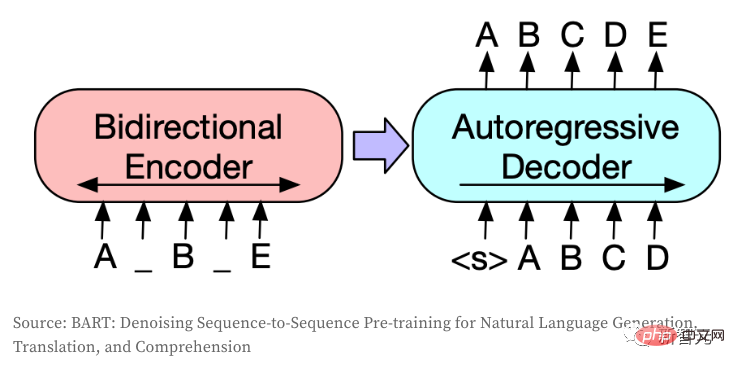
Seq2Seq 모델은 하나의 토큰 시퀀스를 다른 토큰 시퀀스로 변환하며 일반적으로 번역, 요약 또는 대화 모델링과 같은 작업을 위해 NLP에서 사용됩니다. 이미지가 개별 토큰으로 인코딩되는 경우 동일한 아이디어가 CV 필드로 전송될 수도 있습니다. 이 모델은 BART를 사용하며 작성자는 원래 아키텍처를 미세 조정했습니다.
1. 인코더와 디코더를 위한 독립적인 임베딩 레이어를 만들었습니다(동일한 유형의 입력과 출력이 있는 경우 일반적으로 두 레이어를 공유할 수 있음) ;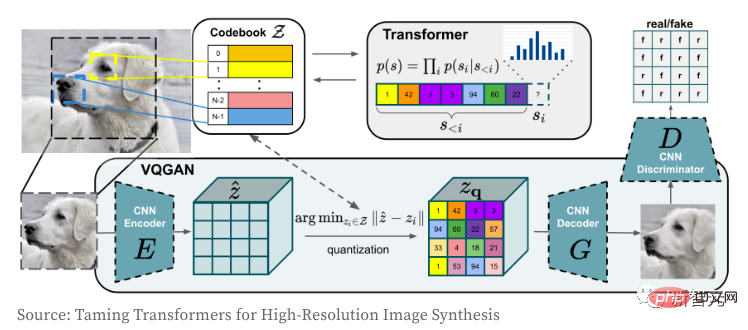
) 시퀀스의 시작과 끝을 표시합니다.
1. DALL·E는 GPT-3의 120억 매개변수 버전을 사용합니다. 이에 비해 저자의 모델은 27배 더 크고 약 4억 개의 매개변수를 가지고 있습니다.
2. 저자는 사전 훈련된 모델(VQGAN, BART 인코더 및 CLIP)을 광범위하게 사용하는 반면 OpenAI는 모든 모델을 처음부터 훈련해야 합니다. 모델 아키텍처는 사용 가능한 사전 학습된 모델과 해당 모델의 효율성을 고려합니다.
3. DALL·E는 더 작은 어휘(8,192 VS 16,384)에서 더 많은 수의 토큰(1,024 VS 256)을 사용하여 이미지를 인코딩합니다.
4. DALL·E는 VQVAE를 사용하고, 저자는 VQGAN을 사용합니다. DALL·E는 작성자가 Seq2Seq 인코더와 디코더를 분리할 때 텍스트와 이미지를 단일 데이터 스트림으로 읽습니다. 이를 통해 텍스트와 이미지에 대해 별도의 어휘를 사용할 수도 있습니다.
5. DALL·E는 자동회귀 모델을 통해 텍스트를 읽는 반면, 저자는 양방향 인코더를 사용합니다.
6. DALL·E는 2억 5천만 쌍의 이미지와 텍스트를 훈련한 반면, 저자는 1,500만 쌍만 사용했습니다. 의.
7. DALL·E는 더 적은 수의 토큰(최대 256 VS 1024)과 더 작은 어휘(16384 VS 50264)를 사용하여 텍스트를 인코딩합니다. VQGAN의 훈련에서 저자는 먼저 ImageNet의 사전 훈련된 체크포인트에서 시작했으며 압축 계수는 f=16이고 어휘 크기는 16,384입니다. 광범위한 이미지를 인코딩하는 데는 매우 효율적이지만 사전 훈련된 체크포인트는 사람과 얼굴을 인코딩하는 데는 좋지 않습니다(둘 다 ImageNet에서는 일반적이지 않기 때문). 따라서 저자는 2 x RTX A6000 클라우드 인스턴스에서 테스트하기로 결정했습니다. 20시간의 미세 조정. 분명히 인간 얼굴에 생성된 이미지의 품질은 크게 향상되지 않았으며 "모델 붕괴"일 수 있습니다. 모델이 훈련되면 다음 단계에서 사용할 수 있도록 Pytorch 모델을 JAX로 변환합니다.
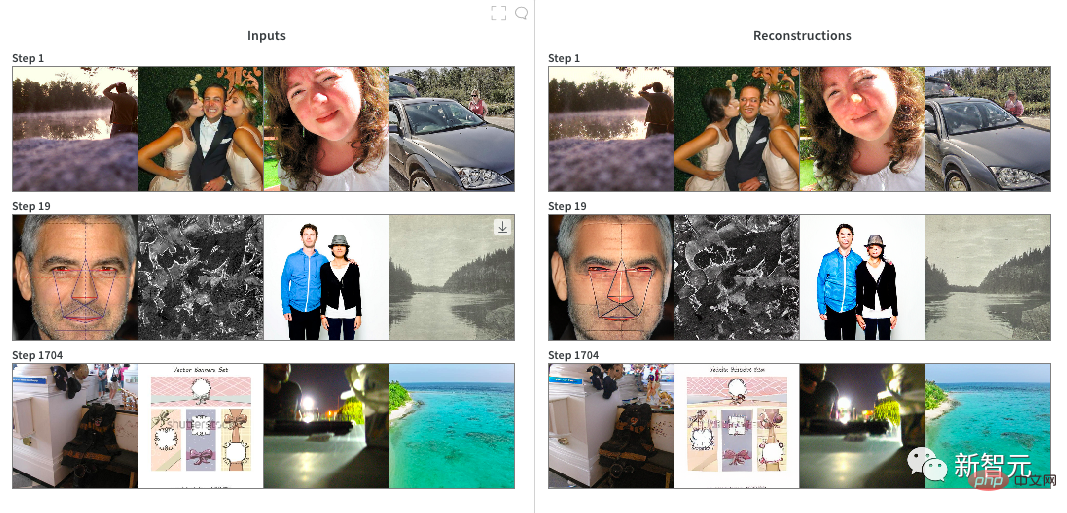
DALL·E Mini 교육: 이 모델은 JAX 프로그래밍을 사용하고 TPU의 장점을 최대한 활용합니다. 작성자는 더 빠른 데이터 로딩을 위해 이미지 인코더를 사용하여 모든 이미지를 사전 인코딩합니다. 훈련 중에 저자는 거의 실현 가능한 몇 가지 매개변수를 빠르게 결정했습니다.
1. 각 단계에서 각 TPU의 배치 크기 크기는 56이며, 이는 각 TPU에 사용할 수 있는 최대 메모리입니다.
2. 56 × 8 TPU 칩 × 8 단계 = 업데이트당 3,584개 이미지
3. 최적화 프로그램 Adafactor의 메모리 효율성을 통해 더 높은 배치 크기
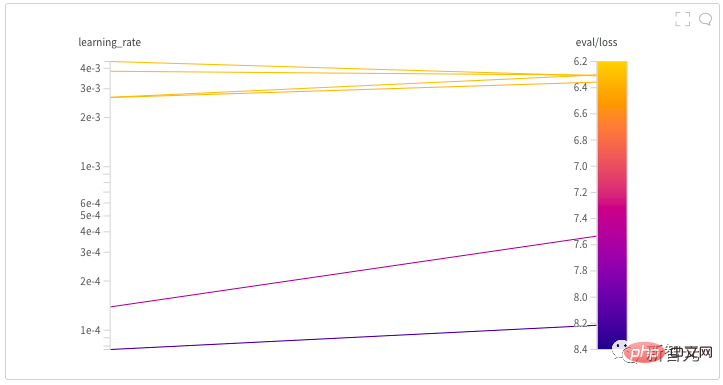
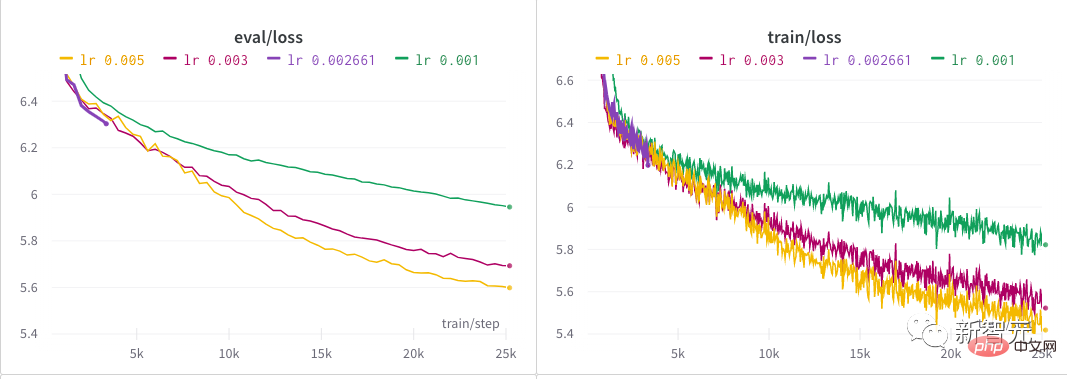
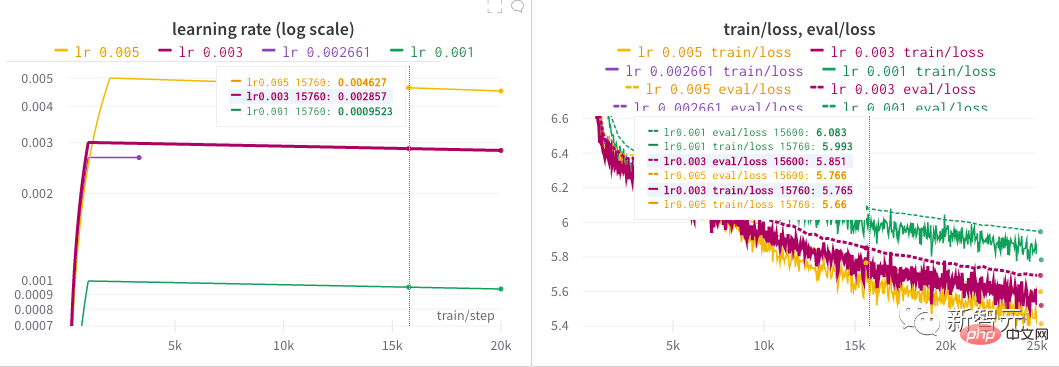
4 및 학습 속도를 사용할 수 있습니다. 선형적으로 붕괴됩니다. 저자는 하이퍼파라미터 검색을 시작하여 모델에 대한 좋은 학습률을 찾는 데 거의 반나절을 보냈습니다. 모든 NB 모델 뒤에는 아마도 하이퍼파라미터를 찾는 힘든 과정이 있을 것입니다! 저자의 초기 탐색 후, 최종적으로 0.005에 도달할 때까지 오랜 기간 동안 여러 가지 다른 학습률을 시도했습니다.
위 내용은 2세대 GAN 네트워크의 등장? DALL·E Mini의 그래픽은 외국인들이 열광할 정도로 끔찍합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!