
하버드 대학교가 망했다: DALL-E 2는 단지 '접착제 괴물'일 뿐이며 생성 정확도는 22%에 불과합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-15 17:40:031263검색
DALL-E 2가 처음 출시되었을 때 생성된 그림은 입력된 텍스트를 거의 완벽하게 재현할 수 있었습니다. 고해상도와 강력한 그림 상상력도 여러 네티즌들 사이에서 "너무 멋지다"라는 평가를 불러일으켰습니다.

그러나 최근 하버드 대학교의 새로운 연구 논문에 따르면 DALL-E 2가 생성한 이미지는 훌륭하지만 텍스트를 표현하는 것조차 없이 텍스트의 여러 개체를 서로 붙일 수 있다는 사실이 밝혀졌습니다.

문서 링크: https://arxiv.org/pdf/2208.00005.pdf
데이터 링크: https://osf.io/sm68h/
예를 들어 텍스트 프롬프트는 "A cup"으로 제공됩니다. on a 숟가락"을 보면 DALL-E 2에서 생성된 이미지 중 일부 이미지가 "on" 관계를 만족하지 않는 것을 볼 수 있습니다.
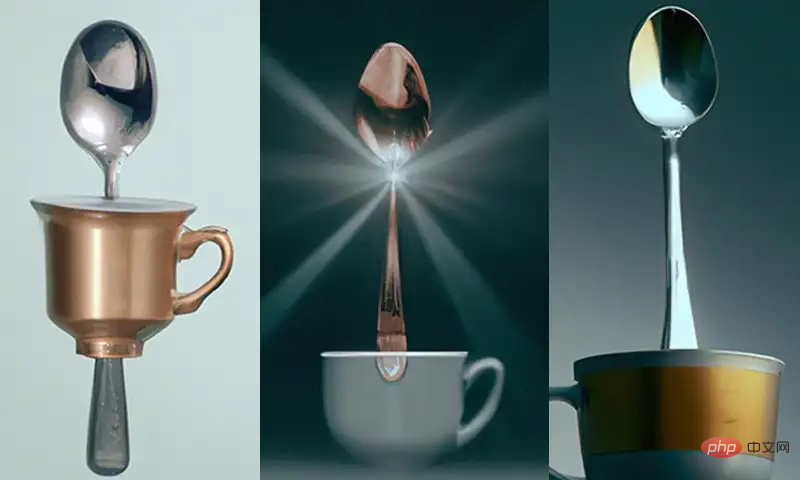
그러나 훈련 세트에서 DALL-E 2가 볼 수 있는 찻잔과 숟가락의 조합은 모두 "in"인 반면 "on"은 비교적 드물기 때문에 두 관계를 생성하는 정확도는 동일하지 않습니다. . 동일하지 않습니다.

그래서 DALL-E 2가 실제로 텍스트의 의미 관계를 이해할 수 있는지 알아보기 위해 연구진은 15가지 유형의 관계를 선택했으며, 그 중 in, on, under를 포함한 공간적 관계(물리적 관계) 8개를 선택했습니다. , 덮다, 가까이, 막다, 매달리고 묶다; 밀기, 당기기, 만지기, 때리기, 발로 차기, 돕기, 숨기기 등 7가지 행위 관계
텍스트에 설정된 엔터티는 12개로 제한되며 모두 선택됩니다. 각 데이터 세트의 단순하고 일반적인 항목, 즉 상자, 원통, 담요, 그릇, 찻잔, 칼; 남자, 여자, 어린이, 로봇, 원숭이 및 이구아나.

각 클래스 관계에 대해 무작위로 5개의 프롬프트를 만듭니다. 매번 교체할 엔터티 2개를 선택하고 마지막으로 75개의 텍스트 프롬프트를 생성합니다. DALL-E 2 렌더링 엔진에 제출한 후 생성된 처음 18개의 이미지가 선택되어 1350개의 이미지가 생성되었습니다.
이후 연구자들은 상식추론 테스트를 통해 주석자 180명 중 169명을 선정하여 주석 과정에 참여하게 했습니다.
실험 결과 DALL-E 2에서 생성된 이미지와 이미지를 생성하는 데 사용된 텍스트 프롬프트 간의 평균 일관성은 75개의 프롬프트 중 22.2%에 불과한 것으로 나타났습니다
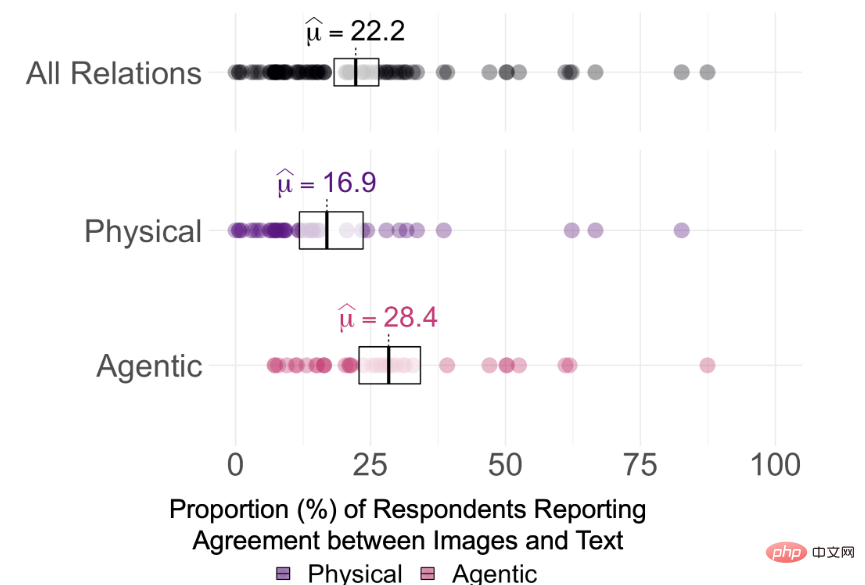
그러나 DALL-E 2가 무엇인지 말하기는 어렵습니다. 텍스트의 관계가 실제로 "이해"되었는지 여부는 주석자의 일관성 점수와 0%, 25% 및 50%의 합의 임계값을 기반으로 각 관계의 Holm 수정 단일 표본 유의성을 관찰하여 결정됩니다. 테스트에서는 15개 관계 모두에 대한 참가자 동의율이 α = 0.95(pHolm
따라서 다중 비교를 수정하지 않더라도 DALL-E 2에서 생성된 이미지는 텍스트에 있는 두 개체 간의 관계를 이해하지 못하는 것이 사실입니다.
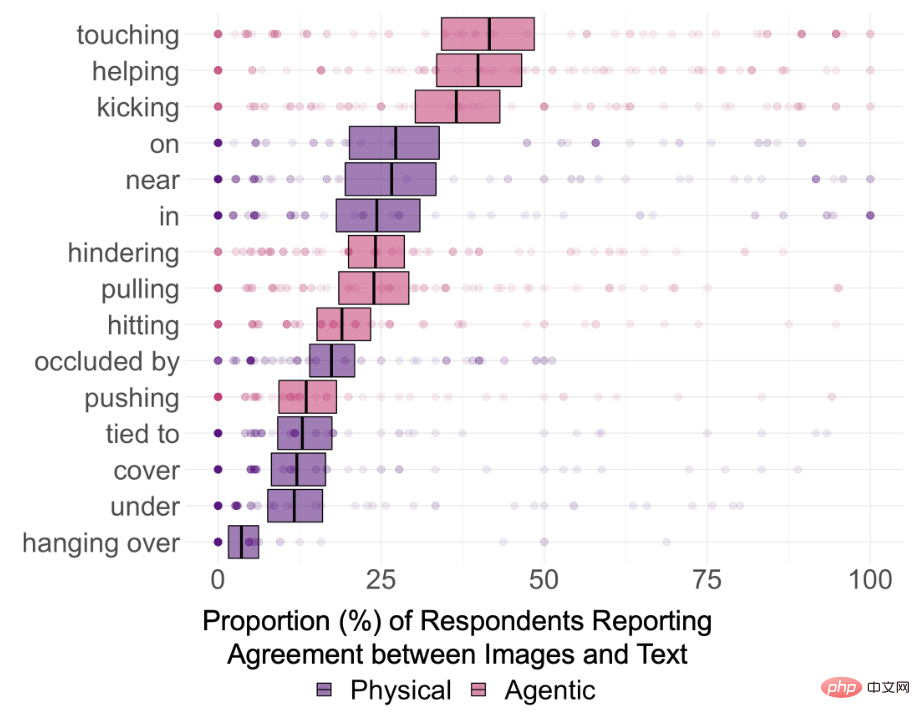
결과는 또한 관련되지 않은 두 개체를 연결하는 DALL-E의 능력이 상상만큼 강력하지 않을 수 있음을 보여줍니다. 예를 들어, "그릇을 만지는 아이"의 일관성은 87%에 달했습니다. 이미지, 어린이, 그릇이 꽤 자주 함께 등장합니다.

그러나 "감동적인 원숭이와 이구아나"로 생성된 이미지의 최종 일관성 비율은 11%에 불과하며 렌더링된 이미지에는 종 오류가 있을 수도 있습니다.

따라서 DALL-E 2의 일부 이미지 카테고리는 어린이, 음식 등 비교적 잘 발달되어 있지만 일부 데이터 카테고리는 여전히 지속적인 훈련이 필요합니다.
그러나 현재 DALL-E 2는 여전히 공식 웹사이트에서 주로 고화질과 사실적인 스타일을 보여주고 있습니다. "두 개체를 서로 붙이는 것"인지, 아니면 이미지를 생성하기 전에 텍스트 정보를 실제로 이해하고 있는지는 아직 확실하지 않습니다. .
연구원들은 관계형 이해가 인간 지능의 기본 구성 요소라고 밝혔으며, DALL-E 2의 기본 공간 관계(예: on, of) 성능이 좋지 않다는 것은 DALL-E 2가 아직 인간만큼 유연하고 견고하게 구성하고 구성할 수 없음을 나타냅니다. .세상을 이해하세요.
하지만 네티즌들은 물건을 서로 붙일 수 있는 '접착제'를 개발할 수 있다는 것이 이미 대단한 성과라고 말했습니다! DALL-E 2는 AGI가 아니며 앞으로도 개선의 여지가 많이 있습니다. 적어도 자동으로 이미지를 생성할 수 있는 가능성은 열려 있습니다!
DALL-E 2에 다른 문제가 있나요?
실제로 DALL-E 2가 출시되자마자 수많은 실무자들이 장단점에 대한 심도 있는 분석을 진행했습니다.

블로그 링크: https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot-do
GPT-3로 소설을 쓰는 것은 약간 단조롭습니다. DALL -E 2는 텍스트에 대한 일부 일러스트레이션과 긴 텍스트에 대한 만화 스트립을 생성할 수 있습니다.
예를 들어, DALL-E 2는 그림 스타일, 커피숍, 헤드폰 착용, 그리고 노트북 등등

그러나 텍스트의 기능 설명에 두 사람이 포함된 경우 DALL-E 2는 어떤 기능이 어떤 사람에게 속하는지 잊어버릴 수 있습니다. 예를 들어 입력 텍스트는 다음과 같습니다.
침대에서 쉬고 있는 어린 검은 머리 소년, 햇빛이 스며드는 창문 아래 침대 옆 의자에 앉아 있는 회색 머리의 나이든 여성, 햇빛이 스며드는 침대 옆 의자에 있는 픽사 스타일의 디지털 아트.
DALL-E 2가 창문, 의자, 침대를 올바르게 생성할 수 있음을 알 수 있지만 생성된 이미지는 연령, 성별, 머리 색깔 특징의 조합으로 인해 약간 혼동됩니다. 또 다른 예는 "캡틴 아메리카와 아이언맨을 나란히 서게 하는 것"입니다. 생성된 결과는 분명히 캡틴 아메리카와 아이언맨의 특징을 가지고 있지만 특정 요소는 다른 인물(예: 아이언맨)에게 배치되어 있음을 알 수 있습니다. 캡틴 아메리카의 방패를 가진 남자).
또 다른 예는 "캡틴 아메리카와 아이언맨을 나란히 서게 하는 것"입니다. 생성된 결과는 분명히 캡틴 아메리카와 아이언맨의 특징을 가지고 있지만 특정 요소는 다른 인물(예: 아이언맨)에게 배치되어 있음을 알 수 있습니다. 캡틴 아메리카의 방패를 가진 남자).
 예를 들어, 입력 텍스트는 다음과 같습니다.
예를 들어, 입력 텍스트는 다음과 같습니다.
로마 군인 복장을 한 두 마리의 개가 해적선에서 망원경을 통해 뉴욕 시를 바라보고 있습니다.
이번에 DALL-E 2는 작동을 멈췄습니다. 저자는 그것을 알아내는 데 30분 정도 걸렸습니다. 결국 그는 "뉴욕시와 해적선" 또는 "망원경을 든 개와" 중 하나를 선택해야 했습니다. 로마 군인 제복" .
Dall-E 2는 도시나 도서관의 책장과 같은 일반적인 배경을 사용하여 이미지를 생성할 수 있지만, 그것이 이미지의 주요 초점이 아닌 경우 더 미세한 디테일을 얻는 것이 매우 어려운 경우가 많습니다.
DALL-E 2는 다양한 멋진 의자와 같은 일반적인 개체를 생성할 수 있지만 "알토 자전거"를 생성하도록 요청하면 결과 그림은 자전거와 다소 유사하지만 정확하지는 않습니다.
그리고 구글 이미지 아래 오토바이시클 검색은 아래와 같습니다. DALL-E 2도 철자를 쓸 수는 없지만 정지 신호에 STOP을 쓰게 하는 등 완전히 우연히 단어의 철자를 정확하게 쓰는 경우도 있습니다.

DALL-E 2는 편집 기능도 제공합니다. 예를 들어 이미지를 생성한 후 커서를 사용하여 해당 영역을 강조 표시하고 수정 사항에 대한 전체 설명을 추가할 수 있습니다. 

위 내용은 하버드 대학교가 망했다: DALL-E 2는 단지 '접착제 괴물'일 뿐이며 생성 정확도는 22%에 불과합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!