
GPT3와 Google PaLM을 완전히 폭발시키세요! 향상된 모델 검색 Atlas는 지식 기반 소규모 샘플 작업을 새로 고칩니다. SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-15 15:04:031320검색
무의식적으로 큰 모델 + 작은 샘플이 작은 샘플 학습 분야의 주류 접근 방식이 되었습니다. 많은 작업 맥락에서 일반적인 아이디어는 먼저 작은 데이터 샘플에 레이블을 지정한 다음 작은 데이터 사용을 기반으로 큰 모델을 사전 훈련하는 것입니다. 훈련용 샘플. 우리가 살펴본 것처럼 대형 모델은 다양한 소표본 학습 작업에서 놀라운 결과를 얻었지만, 이는 또한 자연스럽게 소표본 학습에서 대형 모델의 내재된 단점 중 일부를 부각시킵니다.
소표본 학습에서는 모델이 소수의 표본을 기반으로 독립적인 추론을 완성할 수 있는 능력을 기대합니다. 즉, 이상적인 모델은 문제 해결을 통해 문제 해결 아이디어를 습득하여 그림을 그릴 수 있어야 합니다. 새로운 문제에 직면했을 때의 추론. 그러나 대형 모델 + 소형 샘플의 이상적이고 실용적인 학습 능력은 문제 해결 과정을 기억하기 위해 대형 모델 학습 중에 저장된 많은 양의 정보에 의존하는 것 같습니다. 다양한 데이터 세트에 대해서는 매우 용감합니다. 항상 실패할 것이다. 이런 식으로 공부하는 학생이 정말 잠재적인 학생인가?

오늘 Meta AI가 소개한 논문은 새로운 접근 방식을 취하여 검색 향상 방법을 소표본 학습 분야에 적용한 것입니다. 64개의 예를 사용하는 것뿐만 아니라 자연 질문 데이터 세트에서도 64개의 예를 사용합니다. ), 42%의 정확도를 달성했으며, 대형 모델 PaLM에 비해 매개변수 수를 50배(540B->11B) 줄였으며, 해석성, 제어성, 업데이트성 측면에서도 큰 이점을 갖지 못했습니다. 더 큰 모델에서 사용할 수 있습니다.
논문 제목:Few-shot Learning with Retrieval Augmented Language Models논문 링크:https://arxiv.org/pdf/2208.03299.pdf
검색 Enhan ced 추적성
논문 초반에 모든 사람에게 "소표본 학습 분야에서 정보를 저장하기 위해 엄청난 수의 매개변수를 사용해야 하는가?"라는 질문이 제기되었습니다. 잇달아 대형 모델 모델이 SOTA를 끊임없이 새로 고칠 수 있는 이유 중 하나는 모델의 거대한 매개변수가 문제에 필요한 정보를 저장하기 때문입니다. Transformer 탄생 이후 NLP 분야에서는 대형 모델이 주류 패러다임이 되어 왔다. 대형 모델의 점진적인 발전과 함께 '빅' 문제가 지속적으로 노출되고 있으며, '빅'의 필요성을 묻는 것은 꽤 의미 있는 일이다. 논문의 저자는 이 질문에서 시작하여 이 질문에 대해 부정적인 대답을 내렸고, 그 방법은 향상된 모델을 검색하는 것입니다.

추적 검색 향상 실제로 그 기술은 오픈 도메인 질문 응답, 기계 판독, 텍스트 생성과 같은 작업에 주로 사용되지만 검색 향상에 대한 아이디어는 RNN으로 거슬러 올라갑니다. NLP 시대. 데이터의 장기적인 의존성을 해결할 수 없는 RNN 모델의 단점으로 인해 연구자들은 솔루션을 광범위하게 탐색하게 되었습니다. 우리에게 매우 친숙한 Transformer는 모델의 기억 불능 문제를 효과적으로 해결하기 위해 Attention 메커니즘을 사용합니다. 이로써 대형 모델 사전 훈련 시대의 문이 열렸습니다.
당시에는 실제로 다른 방법이 있었는데, 바로 Cached LM이었습니다. RNN이 시험을 보자마자 기억하지 못할 수도 있으므로 RNN이 공개하도록 하는 것이 핵심이었습니다. -book 시험에는 Cache 메커니즘을 도입하여 훈련 중에 예측된 단어를 Cache에 저장하고 쿼리와 Cache 인덱스의 정보를 결합하여 예측 중에 작업을 완료할 수 있으므로 RNN 모델의 단점을 해결할 수 있습니다. 시간.
결과적으로 검색 강화 기술은 매개변수 메모리 정보에 의존하는 대형 모델과는 전혀 다른 길을 걷기 시작했습니다. 검색 향상을 기반으로 하는 모델을 사용하면 다양한 소스의 외부 지식을 도입할 수 있으며 이러한 검색 소스에는 훈련 코퍼스, 외부 데이터, 감독되지 않은 데이터 및 기타 옵션이 포함됩니다. 검색 향상 모델은 일반적으로 검색기와 생성기로 구성됩니다. 검색기는 질의에 따라 외부 검색 소스로부터 관련 지식을 획득하고, 생성기는 검색된 관련 지식과 질의를 결합하여 모델 예측을 수행합니다.
최종 분석에서 검색 강화 모델의 목표는 모델이 데이터를 기억하는 방법을 학습할 뿐만 아니라 스스로 데이터를 찾는 방법도 학습할 수 있기를 기대하는 것입니다. 이 기능은 많은 지식에서 큰 장점을 가지고 있습니다. 검색 강화 모델도 이러한 분야에서 큰 성공을 거두었지만 검색 강화가 소규모 학습에 적합한지는 알 수 없습니다. Meta AI의 이 논문으로 돌아가서 우리는 소규모 샘플 학습에서 검색 향상 적용을 성공적으로 테스트했으며 Atlas가 탄생했습니다.
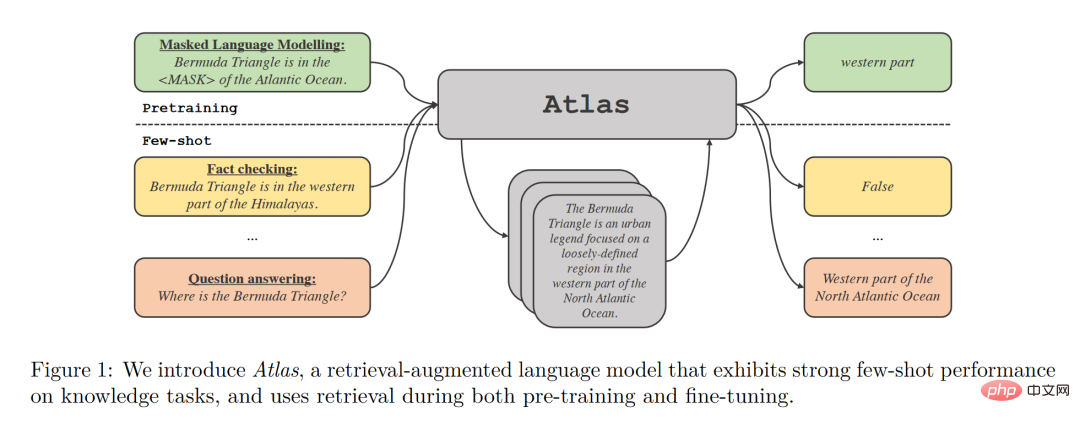
모델 구조
Atlas에는 검색기 모델과 언어 모델이라는 두 가지 하위 모델이 있습니다. 작업에 직면하면 Atlas는 검색기를 사용하여 입력 질문을 기반으로 대량의 코퍼스에서 가장 관련성이 높은 상위 k 문서를 생성한 다음 이러한 문서를 질문 쿼리와 함께 언어 모델에 넣어 필요한 출력을 생성합니다. .

Atlas 모델의 기본 훈련 전략은 동일한 손실 함수를 사용하여 리트리버와 언어 모델을 공동으로 훈련하는 것입니다. 검색기와 언어 모델은 모두 사전 훈련된 Transformer 네트워크를 기반으로 합니다. 그 중
- 검색기는 Contriever를 기반으로 설계되었으며 비지도 데이터를 통해 사전 훈련되었으며 2계층 인코더를 사용합니다. 쿼리와 문서는 독립적으로 인코딩됩니다. 프로세서에서는 해당 출력의 내적을 통해 쿼리와 문서 간의 유사성을 얻습니다. 이 설계를 통해 Atlas는 문서 주석 없이 검색기를 훈련하여 메모리 요구 사항을 크게 줄일 수 있습니다.
- 언어 모델은 T5를 기반으로 학습됩니다. 서로 다른 문서와 쿼리가 서로 연결되어 인코더에 의해 독립적으로 처리됩니다. 마지막으로 디코더는 검색된 모든 단락에 대해 Cross-Attention을 수행하여 최종 출력을 얻습니다. . 이러한 Fusion-in-Decoder 접근 방식은 Atlas가 문서 수의 확장에 효과적으로 적응하는 데 도움이 됩니다.
저자가 4가지 손실 함수와 리트리버와 언어 모델의 공동 훈련 없이 상황을 비교하고 테스트했다는 점은 주목할 만합니다. 그 결과는 다음과 같습니다.
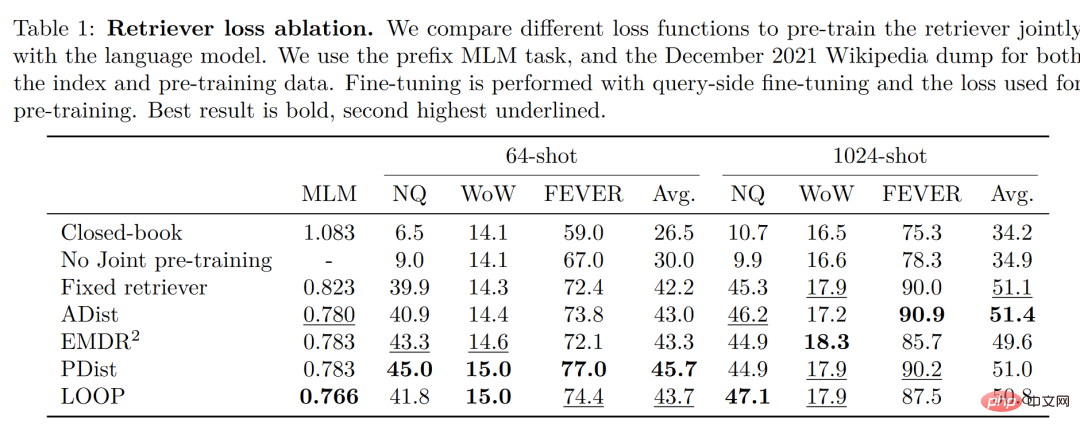
이러한 조건에서 공동 훈련 방법을 사용하여 얻은 정확도는 공동 훈련을 하지 않은 것보다 훨씬 더 높습니다. 따라서 저자는 이러한 리트리버와 언어 모델의 공동 훈련이 Atlas의 정확도 획득 능력의 핵심이라고 결론지었습니다. 작은 샘플 학습.
실험 결과
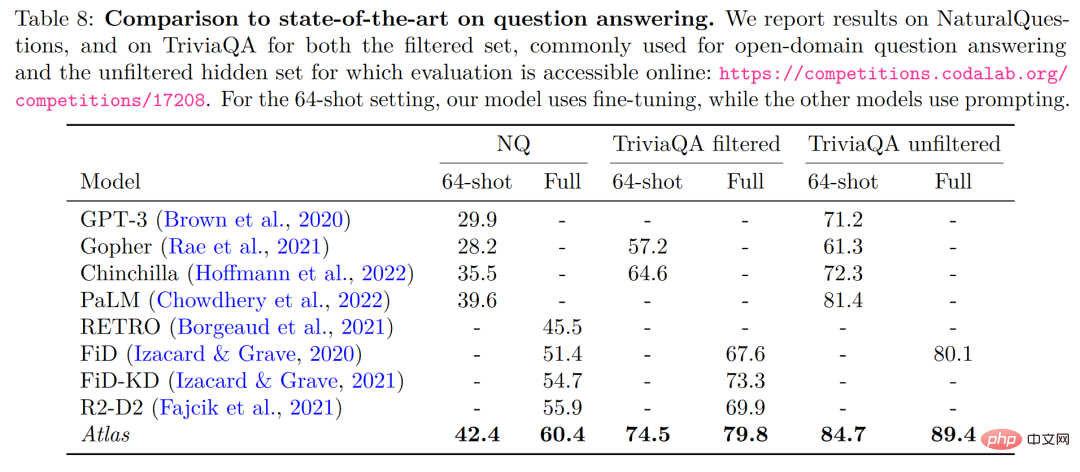
대규모 다중 작업 언어 이해 작업(MMLU)에서 Atlas는 다른 모델에 비해 11B 매개변수만으로 GPT-3보다 15배 더 많은 매개변수를 가지고 있으며 정확도도 좋습니다. 멀티 태스킹 트레이닝이 도입되면서 5샷 테스트의 정확도는 Atlas의 매개변수 수의 25배인 Gopher의 정확도와 거의 비슷해졌습니다.
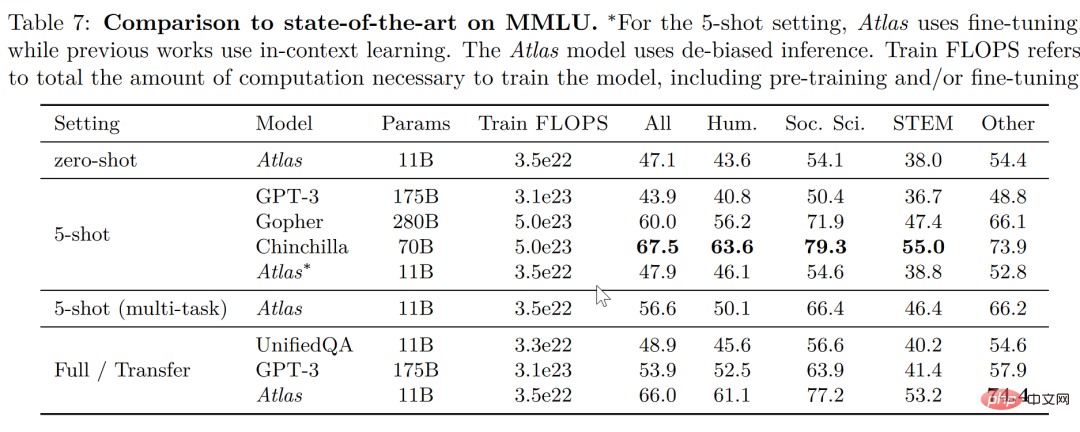
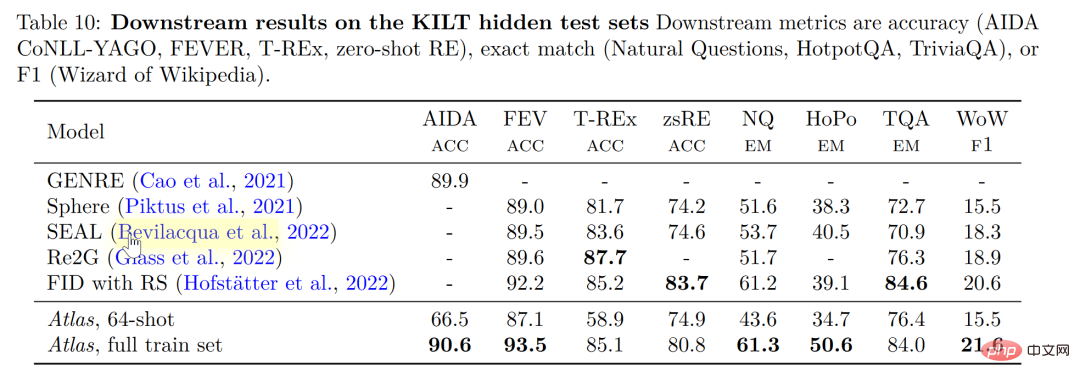
오픈 도메인 질문 답변-NaturalQuestions 및 TriviaQA의 두 가지 테스트 데이터에서 64개의 예제에 대한 Atlas 및 기타 모델의 성능과 전체 훈련 세트의 성능을 비교합니다. Atlas는 64샷으로 새로운 SOTA를 달성했으며, 64개 데이터만 사용하여 TrivuaQA에서 84.7%의 정확도를 달성했습니다.
사실 확인 작업(FEVER)에서도 Atlas는 15샷 작업에서 매개 변수 수가 수십 배인 Gopher 및 ProoFVer보다 작은 샘플에서 훨씬 더 나은 성능을 보였습니다. Gopher 5.1%를 초과했습니다.

지식 집약적인 자연어 처리 작업에 대한 자체 게시 벤치마크인 KILT에서 일부 작업에서 64개의 샘플을 사용하여 훈련된 Atlas의 정확도는 전체 샘플을 사용하는 다른 모델에서 얻은 정확도와 훨씬 가깝습니다. 모든 샘플로 Atlas를 교육한 후 Atlas는 5개 데이터 세트에서 SOTA를 새로 고쳤습니다.
해석 가능성, 제어 가능성, 업데이트 가능성
본 논문의 연구에 따르면 검색 향상 모델은 더 작고 더 나은 균형을 유지할 뿐만 아니라 해석 가능성 측면에서 다른 대형 모델에는 없는 기능도 가지고 있습니다. 대형 모델의 블랙박스 특성으로 인해 연구자가 대형 모델을 사용하여 모델의 작동 메커니즘을 분석하기가 어렵습니다. 그러나 검색 강화 모델은 검색된 문서를 직접 추출할 수 있으므로 검색을 통해 검색된 기사를 분석하여 Atlas 작업에 대한 더 나은 이해를 얻을 수 있습니다. 예를 들어 추상대수학 분야에서는 모델 코퍼스의 73%가 위키피디아에 의존한 반면, 윤리 관련 분야에서는 검색자가 추출한 문서 중 단 3%만이 위키피디아에서 나온 것으로 나타났습니다. 직관. 아래 그림의 왼쪽 통계차트에서 볼 수 있듯이, 모델에서는 CCNet 데이터를 선호하지만, 공식과 추론에 좀 더 중점을 두는 STEM 분야에서는 위키피디아 기사의 활용률이 크게 높아졌습니다.
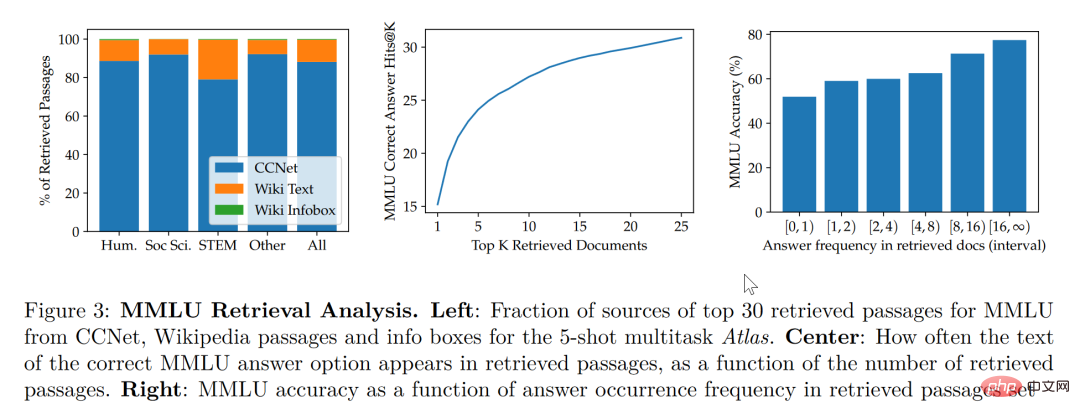
위 그림의 오른쪽 통계 차트에 따르면, 정답이 포함된 검색된 기사의 수가 증가할수록 모델의 정확도도 기사가 계속 증가하는 것을 발견했습니다. 답변이 포함되어 있지 않으면 정답률이 55%에 불과하며, 답변이 15회 이상 언급되었을 때 정답률은 77%에 달했습니다. 또한, 50개 검색 엔진을 통해 검색된 문서를 수동으로 조사한 결과, 그 중 44%가 유용한 배경 정보를 포함하고 있는 것으로 나타났습니다. 당연히 이슈에 대한 배경 정보가 포함된 이러한 자료는 연구자들에게 독서 도움을 확장할 수 있는 좋은 기회를 제공할 수 있습니다.
일반적으로 우리는 대형 모델이 훈련 데이터의 "유출" 위험이 있다고 생각하는 경향이 있습니다. 즉, 때로는 테스트 질문에 대한 대형 모델의 답변이 모델의 학습 능력이 아니라 모델의 학습 능력에 따라 결정되는 경우가 있습니다. 즉, 대형 모델이 학습한 대량의 말뭉치에서 시험 문제의 정답이 유출된 것입니다. 본 논문에서는 유출되었을 가능성이 있는 말뭉치 정보를 저자가 수동으로 제거한 후, 모델 정확도는 56.4%에서 55.8%로 0.6%만 감소했지만 검색 향상 방법이 모델 부정 행위의 위험을 효과적으로 피할 수 있음을 알 수 있습니다.
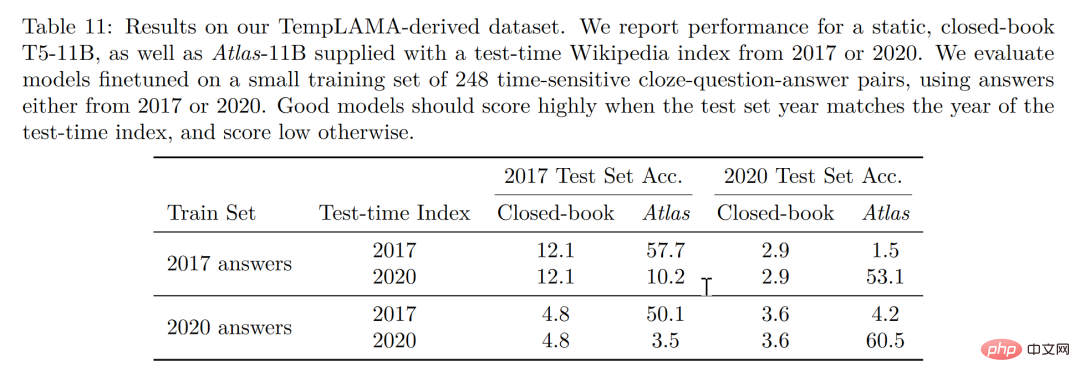
마지막으로 업데이트 가능성은 검색 향상 모델의 고유한 장점이기도 합니다. 검색 향상 모델은 재훈련 없이 수시로 업데이트할 수 있지만 의존하는 코퍼스를 업데이트하거나 교체해야만 합니다. 저자는 Atlas 매개변수를 업데이트하지 않고 아래 그림과 같이 시계열 데이터 세트를 구성함으로써 2020 corpus Atlas를 사용하여 53.1%의 정확도를 달성했다는 점에서 흥미로운 점은 2020 데이터 미세 조정을 통해서도 가능하다는 것입니다. T5, T5 역시 그다지 좋은 성과를 내지 못했는데, 그 이유는 T5의 사전 훈련에 사용된 데이터가 2020년 이전의 데이터이기 때문이라고 저자는 생각한다.
결론
3명의 학생이 있다고 가정해 보겠습니다. 한 학생은 암기에만 의존하여 문제를 정확하게 암기할 수 있고, 다른 학생은 책을 읽는 데 의존합니다. .. 마주쳤을 때, 가장 적합한 정보를 찾기 위해 먼저 정보를 검색하고 하나씩 대답하는 방법을 몰랐습니다. 그러나 마지막 학생은 재능 있고 똑똑했습니다. 단순히 교과서에서 지식을 배우는 것뿐입니다.
분명히 소표본 학습의 이상은 세 번째 학생이 되는 것이지만, 현실은 첫 번째 학생 위에 머무를 가능성이 높습니다. 대형 모델은 사용하기 쉽지만, "빅"이 모델의 궁극적인 목표는 결코 아닙니다. 소규모 표본 학습의 원래 의도로 돌아가서 모델이 인간과 유사한 추론 판단과 추론 도출 능력을 갖기를 기대한다면, 우리는 이 논문이 다른 관점에서 나온 것임을 알 수 있습니다. 적어도 학생이 잠재적으로 중복될 수 있는 지식을 머리에 너무 많이 넣지 않고 교과서를 집어 들고 쉽게 읽을 수 있도록 한 단계 더 나아가는 것이 좋을 것입니다. 가볍게 여행을 하게 된다면 교과서를 가지고 계속해서 복습할 수 있도록 하여 암기하는 것보다 지능에 더 가까워질 것입니다.

위 내용은 GPT3와 Google PaLM을 완전히 폭발시키세요! 향상된 모델 검색 Atlas는 지식 기반 소규모 샘플 작업을 새로 고칩니다. SOTA의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!