
스테이션 B 음성인식 기술 구현 사례

- 王林앞으로
- 2023-04-15 10:40:021789검색
자동음성인식(ASR) 기술은 오디오 및 비디오 콘텐츠 보안 검토, AI 자막(C사이드, 머스트컷, S12 라이브 방송 등) 등 빌리빌리의 관련 비즈니스 시나리오에 대규모로 구현됐다. 영상이해(전문검색) )잠깐만요.
또한 Bilibili의 ASR 엔진은 2022년 11월에 진행된 산업용 벤치마크 SpeechIO(https://github.com/SpeechColab/Leaderboard)의 최근 본격 평가에서도 1위를 차지했습니다(https://github.com/). SpeechColab/Leaderboard#5-순위), 비공개 테스트 세트에서 이점이 더욱 분명해졌습니다.
모든 테스트 세트의 순위 | ||
Ranking |
Manufacturer |
단어 오류율 |
1 |
B역 | 2.82% |
2 |
알리바바 클라우드 |
2.85% |
3 |
Y itu |
3.16% |
4 | Microsoft |
3.28% |
5 |
Tencent |
3.85% |
6 |
iFlytek |
4.05% |
7 |
속도 |
5.19% |
8 |
Baidu |
8.14% |
- AI자막(중국어 및 영어 C면, 머스트컷, S12 라이브 방송 등)
- 전체 텍스트 검색
이번 글에서는 그 과정을 소개하며, 데이터와 알고리즘을 축적하고 탐구해왔습니다.
고품질 ASR 엔진
산업 생산에 적합한 고품질(비용 효율적인) ASR 엔진으로 다음과 같은 특성을 가져야 합니다.
| 설명 |
높은 정확성 |
관련 비즈니스 시나리오에서 높은 정확성과 우수한 견고성 |
고성능 |
산업 배포는 대기 시간이 짧고 속도가 빠르며 시간이 오래 걸립니다. 컴퓨팅 리소스 적게 |
높은 확장성 |
비즈니스 반복 사용자 정의를 효율적으로 지원하고 신속한 비즈니스 업데이트 요구 사항을 충족할 수 있습니다 |
다음은 스테이션 B의 사업 시나리오를 바탕으로 위의 측면에 대한 우리의 관련 탐구와 실천을 소개합니다.
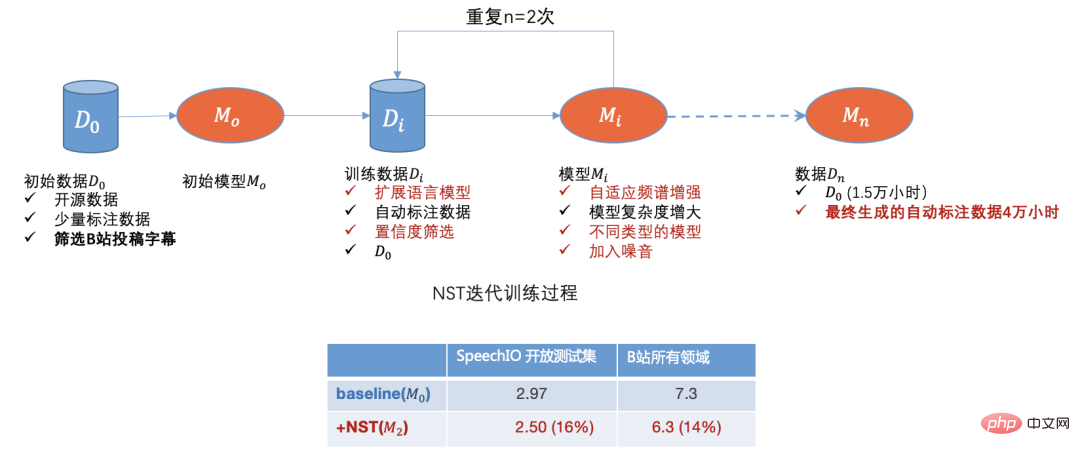
데이터 콜드 스타트
음성 인식 작업은 음성(음성에서 텍스트로)에서 텍스트 내용을 완전히 식별하는 것입니다.
현대 산업 생산의 요구를 충족하는 ASR 시스템은 방대하고 다양한 훈련 데이터에 의존합니다. 여기서 "다양성"은 화자의 주변 환경, 장면 맥락(현장) 및 말하는 사람의 억양.
Bilibili의 비즈니스 시나리오에서는 먼저 음성 훈련 데이터의 콜드 스타트 문제를 해결해야 합니다.
- 콜드 스타트: 오픈 소스 데이터가 매우 적습니다. 구매한 데이터가 비즈니스 시나리오와 일치하는 정도가 매우 낮습니다.
- 다양한 비즈니스 시나리오: 스테이션 B의 오디오 및 비디오 비즈니스 시나리오는 일반 분야로 간주될 수 있고 데이터 "다양성"에 대한 요구 사항이 높은 수십 가지 분야를 포괄합니다.
- 중국어와 영어 혼합: 스테이션 B에는 젊은 사용자가 더 많고 중국어와 영어가 혼합된 일반 지식 비디오가 더 많습니다.
위 문제에 대해 다음과 같은 데이터 솔루션을 채택했습니다.
비즈니스 데이터 필터링
B 사이트에는 UP 소유자 또는 사용자가 제출한 자막(CC 자막) 수가 적지만, 문제도 있습니다:
- 타임 스탬프가 정확하지 않습니다. 문장의 시작 및 끝 타임 스탬프가 종종 첫 번째 단어와 마지막 단어 사이에 있거나 몇 단어 뒤에 있습니다.
- 음성과 텍스트가 완전히 일치하지 않습니다. 단어가 너무 많고, 단어가 너무 적고, 의미에 따른 해석이 있습니다.
- 2002년 자막 등의 디지털 변환(2002년, 2002년 등의 실제 발음);
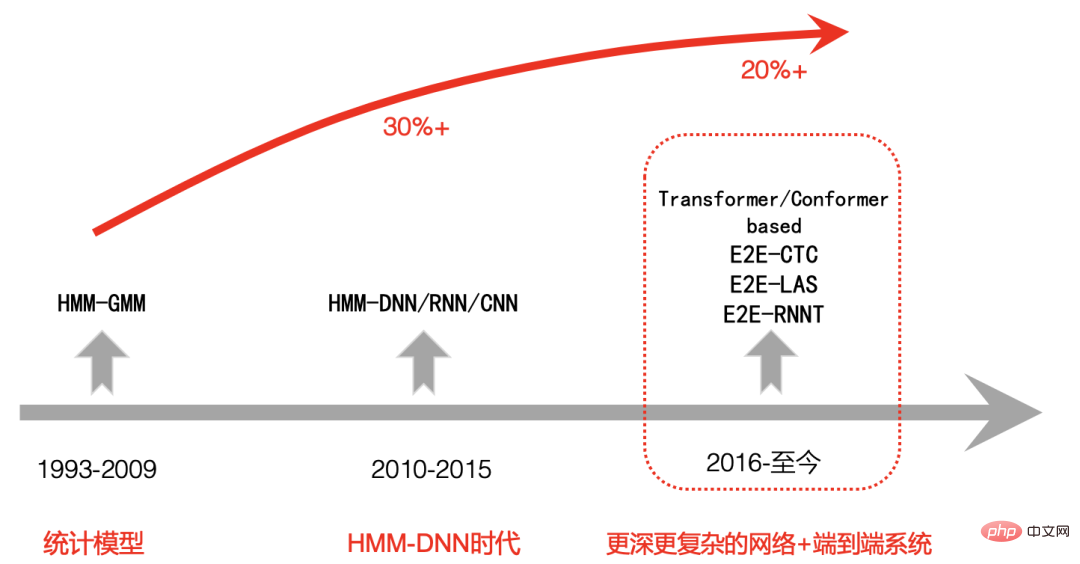
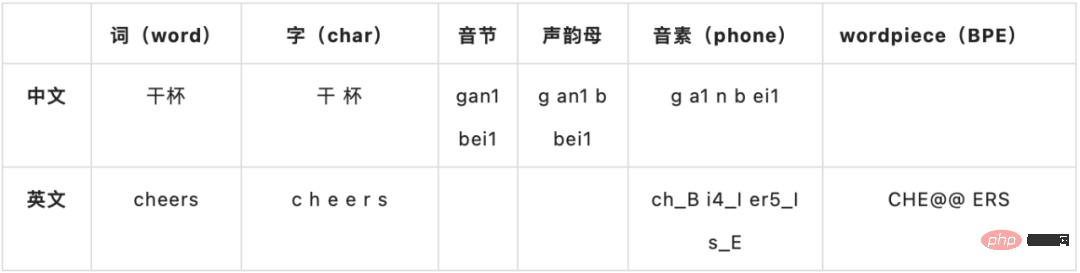
Hybrid 또는 E2E
신경망 기반 하이브리드 프레임워크인 HMM-DNN의 두 번째 단계는 HMM-GMM 시스템의 첫 번째 단계에 비해 음성 인식 정확도가 크게 향상되었음을 모두가 인정한 것입니다.
그러나 2단계와 E2E(End-to-End) 시스템의 3단계 비교는 AI 기술의 발전, 특히 트랜스포머의 등장으로 한동안 업계에서 논란이 되기도 했습니다. 관련 모델, 모델의 표현 능력은 점점 더 강력해지고 있습니다.
동시에 GPU 컴퓨팅 성능이 크게 향상되면서 더 많은 데이터 교육을 추가할 수 있게 된 엔드투엔드 솔루션은 점차 그 장점을 보여줍니다. , 점점 더 많은 회사가 엔드투엔드 계획을 선택합니다.
여기에서는 Bilibili의 비즈니스 시나리오를 기반으로 이 두 가지 솔루션을 비교합니다.
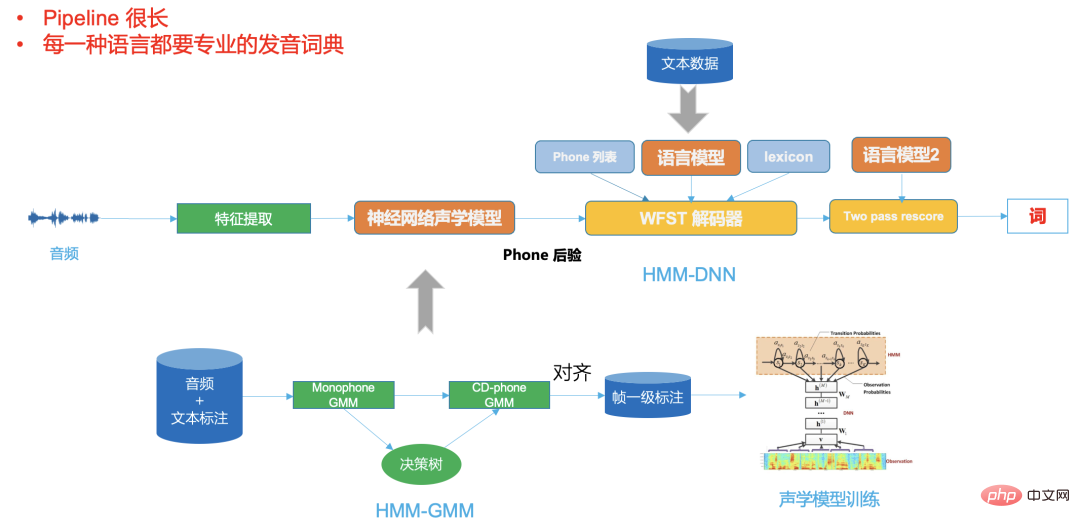
그림 3
그림 2는 일반적인 DNN-HMM 프레임워크이며 파이프라인이 매우 길고 언어가 다르다는 것을 알 수 있습니다. 전문적인 전문 지식이 필요합니다.
그리고 그림 3의 엔드투엔드 시스템은 이 모든 것을 신경망 모델에 넣습니다. 신경망의 입력은 오디오(또는 기능)이고 출력은 인식 결과입니다. 우리는 원한다.
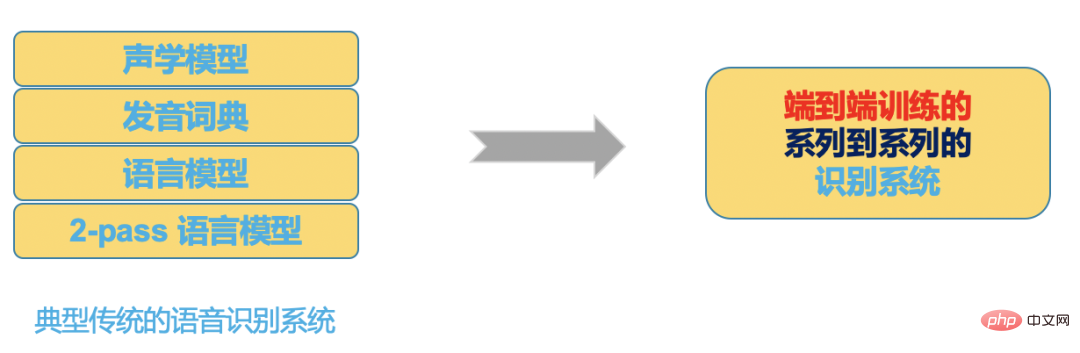
그림 4
기술이 발전함에 따라 개발 도구, 커뮤니티 및 성능 측면에서 엔드투엔드 시스템의 장점이 점점 더 분명해지고 있습니다.
- 대표 도구 및 커뮤니티 비교
하이브리드 프레임워크(하이브리드) |
엔드 투 엔드 프레임워크(E2E) |
|
대표 오픈 소스 도구 및 커뮤니티 |
HTK, Kaldi |
Espnet, Wenet, DeepSpeech, K2 등 |
프로그래밍 언어 |
C/C++, Shell |
Python, Shell |
확장성 |
|
TensorFlow /Pytorch |
- 성능 비교
다음 표는 대표적인 도구를 기반으로 한 일반적인 데이터 세트의 최적 결과(CER)입니다. (하이브리드)
| 는 도구를 의미합니다. | KaldiEspnet | |
| tdnn+chain+rnnlm 점수 다시 매기기 G igaSpeech | 14.84 | 10.80 |
|
Aishell-1 |
7.43 | 4.72 |
WenetSpeech |
12.83 |
8.80 |
간단히 말하면, 특정 리소스가 주어지면 기존 하이브리드 프레임워크와 비교하여 엔드 투 엔드 시스템을 선택함으로써 고품질 ASR 시스템을 더 빠르고 더 좋게 개발할 수 있습니다.
물론 하이브리드 프레임워크를 기반으로 동등하게 발전된 모델과 고도로 최적화된 디코더도 사용한다면 엔드투엔드에 가까운 결과를 얻을 수 있지만, 개발하고 개발하기 위해서는 몇 배의 인력과 자원을 투자해야 할 수도 있습니다. 이 시스템을 최적화하세요.
엔드 투 엔드 솔루션 선택
Bilibili는 매일 복사해야 하는 수십만 시간의 오디오를 보유하고 있으며 ASR 시스템 처리량과 속도, 생성 정확도에 대한 높은 요구 사항을 가지고 있습니다. AI 자막 요구 사항도 높으며, B 스테이션의 장면 범위도 매우 광범위합니다. 합리적이고 효율적인 ASR 시스템을 선택하는 것이 중요합니다.
이상적인 ASR 시스템
그림 5
B 스테이션 시나리오의 문제를 해결하기 위해 end-to-end 프레임워크 기반의 효율적인 ASR 시스템을 구축하고자 합니다.
엔드 투 엔드 시스템 비교
그림 6
그림 4는 대표적인 세 가지 엔드 투 엔드 시스템[5], 즉 E2E-CTC, E2E-RNNT, E2E-AED입니다. 다음은 다양한 측면에서 각 시스템의 장단점을 비교한 것입니다(점수가 높을수록 좋음)
- 시스템 비교
|
E2E-AED |
E2E-RNNT |
최적화된 E2E-CTC |
|
인식 정확도 |
6 |
5 |
6 |
|
실시간(스트리밍) |
3 |
5 |
5 |
비용 및 속도 |
4 |
3 |
5 |
빠른 수정 |
3 |
3 |
6 |
빠르고 효율적인 반복 |
6 |
4 |
5 |
- 비 스트리밍 정확도 비교(CER)
2000시간 |
15000시간 |
|
|
칼디 체인 모델+LM |
13.7 |
-- |
E2E-AED |
11.8 |
6.6 |
E2E-RNNT |
12.4 |
-- |
E2E-CTC(탐욕) |
13.1 |
7.1 |
최적화된 E2E-CTC+LM |
1 0.2 | 5.8 |
위는 각각 2000시간, 15000시간의 영상 학습 데이터를 바탕으로 스테이션 B의 생활 장면과 음식 장면을 분석한 결과입니다. Chain과 E2E-CTC는 동일한 코퍼스인
E2E-AED와 E2E로 학습한 확장 언어 모델을 사용합니다. -RNNT는 확장을 사용하지 않습니다. 언어 모델과 엔드투엔드 시스템은 Conformer 모델을 기반으로 합니다.
두 번째 표에서 볼 수 있듯이 단일 E2E-CTC 시스템의 정확도는 다른 엔드투엔드 시스템보다 크게 떨어지지 않지만 동시에 E2E-CTC 시스템에는 다음과 같은 장점이 있습니다.
- 신경망(AED 디코더 및 RNNT 예측) 구조에는 자동 회귀가 없기 때문에 E2E-CTC 시스템은 스트리밍, 디코딩 속도 및 배포 비용 측면에서 자연스러운 이점을 갖습니다.
- 비즈니스 맞춤화 측면에서 E2E-CTC 시스템은 또한 다양한 언어 모델(nnlm 및 ngram)을 외부적으로 연결하기가 더 쉽습니다. 이로 인해 데이터 범위가 부족한 일반 개방형 필드에서 다른 엔드투엔드 시스템보다 일반화 안정성이 훨씬 향상됩니다.
고품질 ASR 솔루션
고정밀 확장형 ASR 프레임워크
그림 7
Bilibili의 생산 환경에서는 빠른 속도, 정확성 및 리소스 소비 요구 사항이 있습니다. , 다양한 시나리오(예: 원고와 관련된 엔터티 단어, 인기 게임 및 스포츠 이벤트의 사용자 정의 등)에서 신속한 업데이트 및 사용자 정의가 필요합니다.
여기에서는 일반적으로 엔드투엔드 CTC 시스템을 채택하고 해결합니다. 동적 디코더를 통한 문제. 다음은 모델 정확도, 속도 및 확장성 최적화 작업에 중점을 둡니다.
엔드 투 엔드 CTC 차별 훈련
저희 시스템은 한자와 영어 BPE 모델링을 사용합니다. AED와 CTC를 기반으로 한 다중 작업 교육 후 CTC 부분만 유지하고 나중에 차별 교육을 실시합니다. 우리는 엔드투엔드 격자 없는 mmi를 채택합니다[6][7] 차별적 훈련:
- 차별적 훈련 기준
- 차별적 기준-MMI

- 그리고 전통적 차별 성적 훈련의 차이점
1. 전통적인 접근 방식
a. 먼저 CPU의 모든 훈련 코퍼스에 해당하는 정렬 및 디코딩 격자를 생성합니다. b. 훈련 중에 각 미니 배치는 미리 생성된 분자와 격자를 각각 계산합니다. 분모 기울기 및 모델 업데이트
2. 접근 방식
a. 훈련 중에 각 미니배치는 GPU에서 직접 분자와 분모 기울기를 계산하고 모델을 업데이트합니다. 전화 기반 격자 무료 mmi 차별 훈련
- 1. 전화 흠 상태 전송 구조를 버리고 문자 및 영어 BPE 엔드 투 엔드를 직접 모델링합니다.
B국 영상 테스트 세트 |
CTC 기준선 | |
| 6.96 | 전통 DT | 6.63 |
E2E LFMMI DT |
6.13 |
하이브리드 시스템과 비교할 때 엔드투엔드 시스템 디코딩 결과 타임스탬프는 그다지 정확하지 않습니다. AED 훈련은 시간에 따라 단조롭게 정렬되지 않습니다. CTC 훈련 모델은 AED 타임스탬프보다 훨씬 정확하지만 스파이크 문제도 있습니다. 각 단어의 기간이 정확하지 않습니다.
종단 간 식별 훈련 후에는 모델 출력이 더 평평해지고 디코딩 결과의 타임스탬프 경계가 더 정확해집니다.
종단 간 CTC 디코더
음성인식 기술 개발 과정에서 GMM-HMM 기반의 1단계든, DNN-HMM 하이브리드 프레임워크 기반의 2단계든 디코더는 매우 중요한 구성요소입니다.
디코더의 성능은 최종 ASR 시스템의 속도와 정확성을 직접적으로 결정합니다. 비즈니스 확장 및 사용자 정의도 대부분 유연하고 효율적인 디코더 솔루션에 달려 있습니다. WFST를 기반으로 하는 동적 디코더이든 정적 디코더이든 기존 디코더는 많은 이론적 지식에 의존할 뿐만 아니라 뛰어난 성능을 갖춘 기존 디코딩 엔진을 개발하는 데도 필요합니다. 초기 단계에 인력 개발이 많이 필요하고, 이후 유지 관리 비용도 매우 높습니다.
일반적인 기존 WFST 디코더는 통합 FST 네트워크 검색 공간에서 흠, 삼음 컨텍스트, 사전 및 언어 모델을 통합 네트워크, 즉 HCLG로 컴파일해야 디코딩 속도와 정확성을 향상시킬 수 있습니다.
엔드-투-엔드 시스템 기술이 성숙해짐에 따라 전통적인 HMM 전달 구조, 트라이폰 컨텍스트 및 발음 사전이 제거되기 때문에 엔드-투-엔드 시스템 모델링 단위는 중국어 단어나 영어 단어와 같이 더 큰 입도를 갖게 됩니다. 이는 후속 디코딩 검색 공간이 훨씬 작아지므로 빔 검색을 기반으로 하는 간단하고 효율적인 동적 디코더를 선택합니다. 다음 그림은 기존 WFST 디코더와 비교하여 두 가지 디코딩 프레임워크를 보여줍니다. 다음과 같은 장점이 있습니다.
- 일반적으로 WFST 디코딩 리소스의 1/5을 차지합니다.
- 낮은 결합 수준으로 인해 비즈니스를 쉽게 맞춤화하고 다양한 언어 모델과 디코딩을 통합할 수 있습니다.
- 일반적으로 WFST 디코딩 속도보다 5배 빠른 워드 동기 디코딩[8]을 사용하여 디코딩 속도가 빠릅니다. to-end ASR 프레임워크에서 계산량이 가장 많은 부분은 신경망 모델의 추론이어야 하며, 이 계산 집약적인 부분은 GPU의 컴퓨팅 성능을 최대한 활용할 수 있으며 추론으로부터 모델 추론 배포를 최적화합니다. 서비스, 모델 구조 및 모델 정량화:
모델은 F16 반정밀도 추론을 사용합니다. 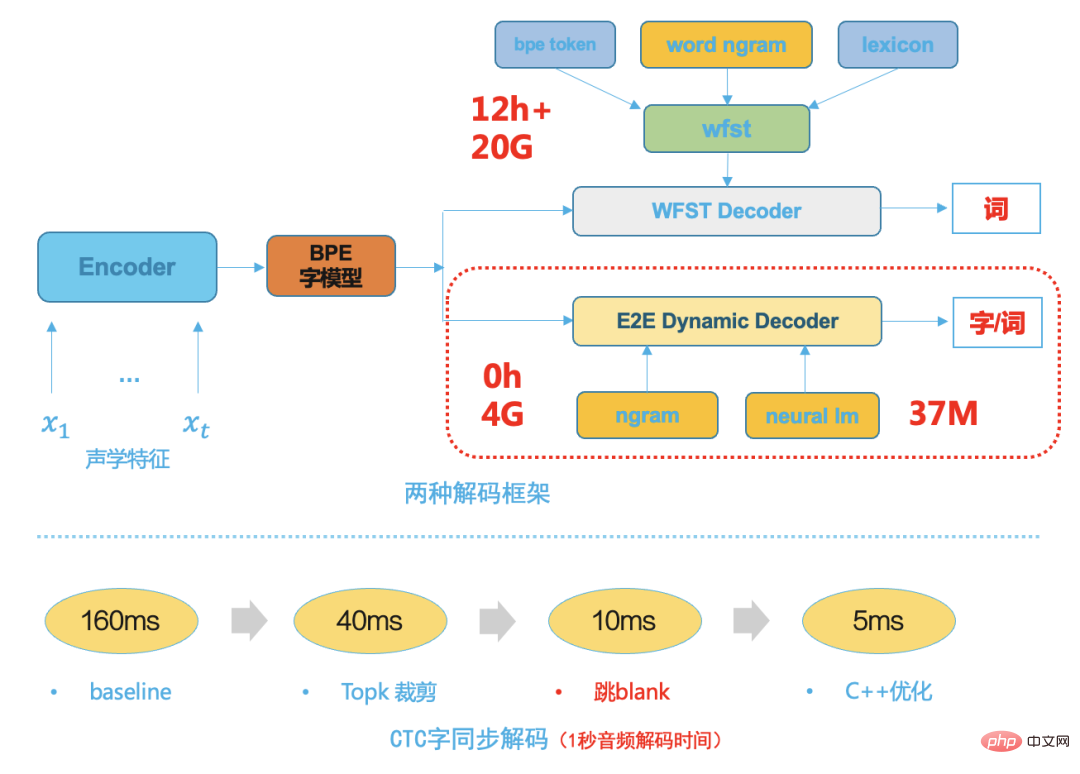
단일 GPU T4에서 속도는 30% 증가하고 처리량은 2배 증가하며 1시간 안에 3,000시간의 오디오를 복사할 수 있습니다.
- 이 글에서는 주로 Bilibili 현장에서 음성 인식 기술을 구현하는 방법, 처음부터 훈련 데이터 문제를 해결하는 방법, 전반적인 기술 솔루션 선택, 각 하위 요소의 도입 및 최적화를 소개합니다. 모델 훈련, 디코더 최적화 및 서비스 추론 배포 등을 포함한 모듈. 앞으로는 스트리밍 ASR 관련 기술과 결합하여 원고 수준에서 관련 엔터티 단어의 정확성을 최적화하기 위해 인스턴트 핫 워드 기술을 사용하고 실제 서비스에 대한 보다 효율적인 맞춤형 지원과 같은 관련 랜딩 시나리오에서 사용자 경험을 더욱 향상시킬 것입니다. 게임 및 스포츠 이벤트의 시간 자막 전사.
- 참고자료
[1] A Baevski, H Zhou, et al. wav2vec 2.0: 음성 표현의 자기 지도 학습을 위한 프레임워크
[2] A Baevski, W Hsu, et al. 음성, 시각 및 언어의 자기 지도 학습
[3] Daniel S, Y Zhang 외 자동 음성 인식을 위한 향상된 시끄러운 학생 교육
[4] C Lüscher, E Beck 외 RWTH ASR 시스템 LibriSpeech: 하이브리드 대 주의 - 데이터 증강 없음
[5] R Prabhavalkar, K Rao, et al, 음성 인식을 위한 시퀀스-시퀀스 모델 비교
[6] D Povey, V Peddinti1, et al, 무격자 MMI를 기반으로 한 ASR용 순전히 시퀀스 훈련된 신경망
[7] H Xiang, Z Ou, CTC 토폴로지를 사용한 CRF 기반 단일 스테이지 음향 모델링
[8] Z Chen, W Deng, et al, CTC Lattice를 사용한 전화 동기 디코딩
[9]
https://www.php.cn/link/2ea6241cf767c279cf1e80a790df1885
이 문제의 저자: Deng Wei수석 알고리즘 엔지니어
Bilibili 음성 인식 부문 책임자
위 내용은 스테이션 B 음성인식 기술 구현 사례의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!