
30개의 Python 함수가 데이터 처리 작업의 99%를 해결합니다!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-15 10:07:021084검색

우리는 Pandas가 Python에서 가장 널리 사용되는 데이터 분석 및 조작 라이브러리라는 것을 알고 있습니다. 데이터 분석에서 데이터 처리 문제를 신속하게 해결할 수 있는 다양한 기능과 방법을 제공합니다.
Python 함수의 사용법을 더 잘 익히기 위해 고객 이탈 데이터 세트를 예로 들어 데이터 분석 프로세스에서 가장 일반적으로 사용되는 30가지 함수와 방법을 공유했습니다. 해당 데이터는 기사 마지막 부분에서 다운로드할 수 있습니다. .
데이터는 다음과 같습니다.
import numpy as np
import pandas as pd
df = pd.read_csv("Churn_Modelling.csv")
print(df.shape)
df.columns
결과 출력
(10000, 14) Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography','Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember', 'EstimatedSalary', 'Exited'],dtype='object')
1. 열 삭제
df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True) print(df[:2]) print(df.shape)
결과 출력
설명: "axis" 매개변수는 열을 배치하려면 1로, 행을 배치하려면 0으로 설정됩니다. 변경 사항을 저장하려면 "inplace=True" 매개변수를 True로 설정하세요. 4개의 열을 빼서 열 수가 14개에서 10개로 줄었습니다.
GeographyGenderAgeTenureBalanceNumOfProductsHasCrCard 0FranceFemale 42 20.011 IsActiveMemberEstimatedSalaryExited 0 1101348.88 1 (10000, 10)
2.특정 열 선택
csv 파일에서 부분 열 데이터를 읽어옵니다. usecols 매개변수를 사용할 수 있습니다.
df_spec = pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_spec.head()
3.nrows
nrows 매개변수를 사용하여 csv 파일의 처음 5000개 행을 포함하는 데이터 프레임을 생성할 수 있습니다. Skiprows 매개변수를 사용하여 파일 끝에서 행을 선택할 수도 있습니다. Skiprows=5000은 csv 파일을 읽을 때 처음 5000행을 건너뛴다는 의미입니다.
df_partial = pd.read_csv("Churn_Modelling.csv", nrows=5000)
print(df_partial.shape)
4. 샘플
데이터 프레임을 생성한 후 데이터를 테스트하기 위해 작은 샘플이 필요할 수 있습니다. n 또는 frac 매개변수를 사용하여 샘플 크기를 결정할 수 있습니다.
df= pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_sample = df.sample(n=1000)
df_sample2 = df.sample(frac=0.1)
5. 누락된 값 확인
isna 함수는 데이터 프레임의 누락된 값을 확인합니다. sum 함수와 함께 isna를 사용하면 각 열의 누락된 값 수를 확인할 수 있습니다.
df.isna().sum()
6. loc과 iloc을 사용하여 누락된 값을 추가합니다.
loc과 iloc을 사용하여 누락된 값을 추가합니다.
- loc: 레이블로 선택
- iloc: 인덱스 선택
먼저 20개의 무작위 인덱스를 생성하여 선택합니다.
missing_index = np.random.randint(10000, size=20)
loc를 사용하여 일부 값을 np.nan(결측값)으로 변경하겠습니다.
df.loc[missing_index, ['Balance','Geography']] = np.nan
"균형" 및 "지역" 열에 20개의 값이 누락되었습니다. iloc을 사용하여 또 다른 예를 살펴보겠습니다.
df.iloc[missing_index, -1] = np.nan
7. 누락된 값 채우기
fillna 함수는 누락된 값을 채우는 데 사용됩니다. 다양한 옵션을 제공합니다. 특정 값, 평균과 같은 집계 함수, 이전 또는 다음 값을 사용할 수 있습니다.
avg = df['Balance'].mean() df['Balance'].fillna(value=avg, inplace=True)
fillna 함수의 메소드 매개변수를 사용하면 열의 이전 또는 다음 값을 기준으로 누락된 값을 채울 수 있습니다(예: method="ffill"). 시계열과 같은 순차 데이터에 매우 유용할 수 있습니다.
8. 누락된 값 삭제
누락된 값을 처리하는 또 다른 방법은 누락된 값을 삭제하는 것입니다. 다음 코드는 누락된 값이 있는 행을 삭제합니다.
df.dropna(axis=0, how='any', inplace=True)
9. 조건에 따라 행 선택
어떤 경우에는 특정 조건에 맞는 관찰(즉, 행)이 필요합니다
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)] france_churn.Geography.value_counts()
10. 쿼리로 조건을 설명하세요
쿼리 기능은 보다 유연한 전달 조건부 방법을 제공합니다. 문자열을 사용하여 설명할 수 있습니다.
df2 = df.query('80000 < Balance < 100000')
df2 = df.query('80000 < Balance < 100000'
df2 = df.query('80000 < Balance < 100000')
11. isin을 사용하여 조건을 설명하세요
조건에는 여러 값이 있을 수 있습니다. 이 경우에는 값을 개별적으로 작성하는 것보다 isin 메소드를 사용하는 것이 더 좋습니다.
df[df['Tenure'].isin([4,6,9,10])][:3]

12. Groupby 기능
Pandas Groupby 기능은 데이터 개요를 얻는 데 도움이 되는 다양하고 사용하기 쉬운 기능입니다. 이를 통해 데이터 세트를 더 쉽게 탐색하고 변수 간의 기본 관계를 확인할 수 있습니다.
그룹 비율 함수의 몇 가지 예를 들어보겠습니다. 간단하게 시작해 보겠습니다. 다음 코드는 지리, 성별 조합을 기반으로 행을 그룹화한 다음 각 그룹의 평균 흐름을 제공합니다
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()
13.Groupby는 집계 함수와 결합됩니다
agg 함수는 그룹에 여러 집계 함수를 적용할 수 있도록 합니다. 함수는 매개변수 전달과 같습니다.
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])
14. 서로 다른 그룹에 서로 다른 집계 함수 적용
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum', 'Balance':'mean'})
df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)
또한 "NamedAgg 함수"를 사용하면 집계에서 열 이름을 바꿀 수 있습니다
import pandas as pd
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers = pd.NamedAgg('Exited', 'sum'),Average_balance_of_customers = pd.NamedAgg('Balance', 'mean'))
print(df_summary)

15. 위 그림을 보셨나요? 데이터 형식. 인덱스를 재설정하여 이를 변경할 수 있습니다.
print(df_summary.reset_index())
 16. 원본 인덱스 재설정 및 삭제
16. 원본 인덱스 재설정 및 삭제
경우에 따라 인덱스 재설정과 원본 인덱스 삭제가 동시에 필요합니다.
df[['Geography','Exited','Balance']].sample(n=6).reset_index(drop=True)
17. 특정 열을 인덱스로 설정
데이터 프레임의 모든 열을 인덱스로 설정할 수 있습니다.
df_new.set_index('Geography')
18. 새 열 삽입
group = np.random.randint(10, size=6) df_new['Group'] = group
19. where 함수
조건에 따라 행이나 열의 값을 바꾸는 데 사용됩니다. 기본 대체 값은 NaN이지만 대체 값을 지정할 수도 있습니다.
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)
20. 순위 함수
순위 함수는 순위를 값에 할당합니다. 잔액을 기준으로 고객의 순위를 매기는 열을 만들어 보겠습니다.
df_new['rank'] = df_new['Balance'].rank(method='first', ascending=False).astype('int')
21. 열의 고유 값 수
범주형 변수로 작업할 때 유용합니다. 고유한 카테고리 수를 확인해야 할 수도 있습니다. 값 카운트 함수에 의해 반환된 시퀀스의 크기를 확인하거나 nunique 함수를 사용할 수 있습니다.
df.Geography.nunique
22. 메모리 사용량
memory_usage 함수를 사용하면 이 값은 메모리를 바이트 단위로 표시합니다.
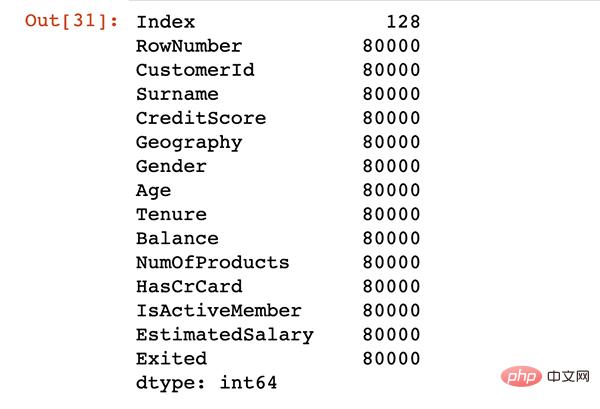
df.memory_usage()
23.数据类型转换
默认情况下,分类数据与对象数据类型一起存储。但是,它可能会导致不必要的内存使用,尤其是当分类变量具有较低的基数。
低基数意味着列与行数相比几乎没有唯一值。例如,地理列具有 3 个唯一值和 10000 行。
我们可以通过将其数据类型更改为"类别"来节省内存。
df['Geography'] = df['Geography'].astype('category')
24.替换值
替换函数可用于替换数据帧中的值。
df['Geography'].replace({0:'B1',1:'B2'})
25.绘制直方图
pandas 不是一个数据可视化库,但它使得创建基本绘图变得非常简单。
我发现使用 Pandas 创建基本绘图更容易,而不是使用其他数据可视化库。
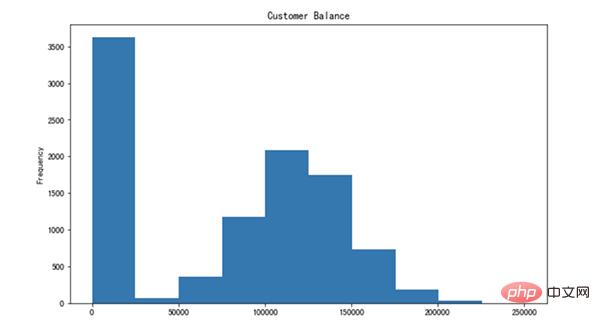
让我们创建平衡列的直方图。
26.减少浮点数小数点
pandas 可能会为浮点数显示过多的小数点。我们可以轻松地调整它。
df['Balance'].plot(kind='hist', figsize=(10,6), title='Customer Balance')
27.更改显示选项
我们可以更改各种参数的默认显示选项,而不是每次手动调整显示选项。
- get_option:返回当前选项
- set_option:更改选项 让我们将小数点的显示选项更改为 2。
pd.set_option("display.precision", 2)
可能要更改的一些其他选项包括:
- max_colwidth:列中显示的最大字符数
- max_columns:要显示的最大列数
- max_rows:要显示的最大行数
28.通过列计算百分比变化
pct_change用于计算序列中值的变化百分比。在计算时间序列或元素顺序数组中更改的百分比时,它很有用。
ser= pd.Series([2,4,5,6,72,4,6,72]) ser.pct_change()
29.基于字符串的筛选
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。
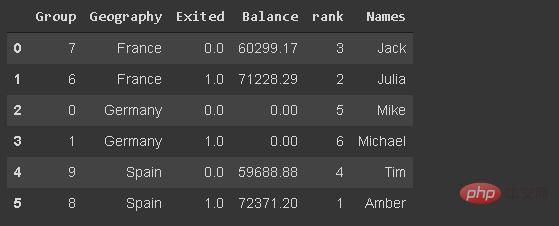
df_new[df_new.Names.str.startswith('Mi')]
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。

30.设置数据样式
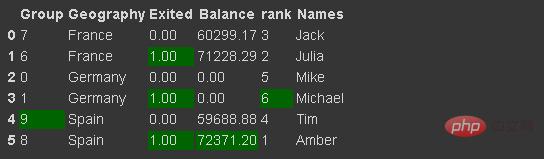
我们可以通过使用返回 Style 对象的 Style 属性来实现此目的,它提供了许多用于格式化和显示数据框的选项。例如,我们可以突出显示最小值或最大值。
它还允许应用自定义样式函数。
df_new.style.highlight_max(axis=0, color='darkgreen')
위 내용은 30개의 Python 함수가 데이터 처리 작업의 99%를 해결합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!