
10가지 흥미로운 고급 Python 스크립트, 수집에 권장됩니다!

- 王林앞으로
- 2023-04-14 20:46:012342검색

일상 업무에서 우리는 항상 다양한 문제에 직면하게 됩니다.
이러한 문제 중 대부분은 간단한 Python 코드를 사용하여 해결할 수 있습니다.
예를 들어, 얼마 전 복단의 한 상사는 130줄의 Python 코드를 사용하여 핵산 통계를 완성했는데, 이로 인해 효율성이 크게 향상되고 많은 시간이 절약되었습니다.
오늘 Xiao F는 Python 스크립트 프로그램 10가지를 가르쳐 드립니다.
간단하지만 여전히 꽤 유용합니다.
관심 있는 사람은 직접 구현하고 도움이 되는 기술을 찾을 수 있습니다.
1.Jpg를 Png로
이미지 형식 변환, 예전에 Xiao F가 가장 먼저 떠올랐던 것은 [Format Factory] 소프트웨어였습니다.
요즘에는 Python 스크립트를 작성하면 다양한 이미지 형식의 변환을 완료할 수 있습니다. 여기서는 jpg를 png로 변환하는 것을 예로 들어보겠습니다.
두 가지 솔루션이 있으며 둘 다 모든 사람과 공유됩니다.
# 图片格式转换, Jpg转Png
# 方法①
from PIL import Image
img = Image.open('test.jpg')
img.save('test1.png')
# 方法②
from cv2 import imread, imwrite
image = imread("test.jpg", 1)
imwrite("test2.png", image)
2. PDF 암호화 및 암호 해독
암호화해야 할 PDF 파일이 100개 이상인 경우 수동으로 암호화하는 것은 불가능하며 시간이 많이 걸립니다.
Python의 pikepdf 모듈을 사용하여 파일을 암호화하고 루프를 작성하여 문서를 일괄적으로 암호화합니다.
# PDF加密
import pikepdf
pdf = pikepdf.open("test.pdf")
pdf.save('encrypt.pdf', encryption=pikepdf.Encryption(owner="your_password", user="your_password", R=4))
pdf.close()
암호화가 있으면 복호화가 진행됩니다.
# PDF解密
import pikepdf
pdf = pikepdf.open("encrypt.pdf",password='your_password')
pdf.save("decrypt.pdf")
pdf.close()
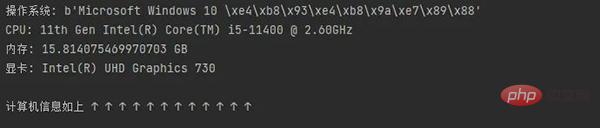
3. 컴퓨터 구성 정보 얻기
많은 친구들이 Master Lu를 사용하여 소프트웨어를 다운로드해야 하는 컴퓨터 구성을 확인할 수 있습니다.
Python의 WMI 모듈을 사용하면 컴퓨터 정보를 쉽게 볼 수 있습니다.
# 获取计算机信息
import wmi
def System_spec():
Pc = wmi.WMI()
os_info = Pc.Win32_OperatingSystem()[0]
processor = Pc.Win32_Processor()[0]
Gpu = Pc.Win32_VideoController()[0]
os_name = os_info.Name.encode('utf-8').split(b'|')[0]
ram = float(os_info.TotalVisibleMemorySize) / 1048576
print(f'操作系统: {os_name}')
print(f'CPU: {processor.Name}')
print(f'内存: {ram} GB')
print(f'显卡: {Gpu.Name}')
print("n计算机信息如上 ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑")
System_spec()
Xiao F의 컴퓨터를 예로 들어 코드를 실행하면 구성을 볼 수 있습니다.
4. 파일 압축 풀기
zipfile 모듈을 사용하여 파일 압축을 풀 수도 있습니다.
# 解压文件
from zipfile import ZipFile
unzip = ZipFile("file.zip", "r")
unzip.extractall("output Folder")
5. Excel 워크시트 병합
은 Excel 워크시트를 하나의 테이블로 병합하는 데 도움이 됩니다. 테이블 내용은 다음과 같습니다.
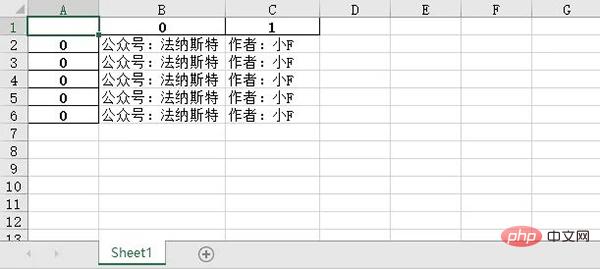
테이블 6개, 나머지 테이블의 내용은 첫 번째 테이블과 동일합니다.
테이블 수를 5개로 설정하면 처음 5개 테이블의 내용이 병합됩니다.
import pandas as pd # 文件名 filename = "test.xlsx" # 表格数量 T_sheets = 5 df = [] for i in range(1, T_sheets+1): sheet_data = pd.read_excel(filename, sheet_name=i, header=None) df.append(sheet_data) # 合并表格 output = "merged.xlsx" df = pd.concat(df) df.to_excel(output)
결과는 다음과 같습니다.
6. 이미지를 스케치로 변환
은 이미지를 처리하는 이전 이미지 형식 변환과 다소 유사합니다.
과거에는 Meitu Xiuxiu를 사용했을 수도 있지만 이제는 Douyin의 필터일 수도 있습니다.
실제로 Python의 OpenCV를 사용하면 원하는 많은 효과를 빠르게 얻을 수 있습니다.
# 图像转换
import cv2
# 读取图片
img = cv2.imread("img.jpg")
# 灰度
grey = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
invert = cv2.bitwise_not(grey)
# 高斯滤波
blur_img = cv2.GaussianBlur(invert, (7, 7), 0)
inverse_blur = cv2.bitwise_not(blur_img)
sketch_img = cv2.divide(grey, inverse_blur, scale=256.0)
# 保存
cv2.imwrite('sketch.jpg', sketch_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
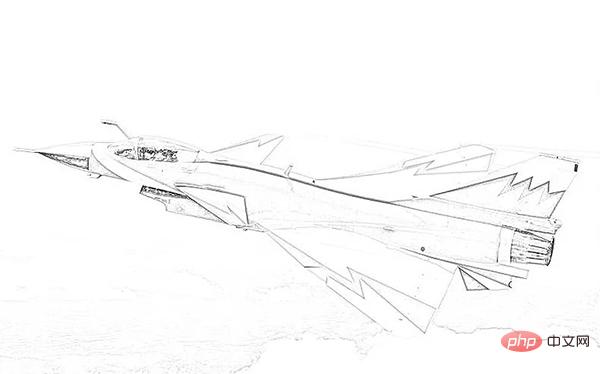
원본사진은 아래와 같습니다.

스케치는 다음과 같은데 꽤 괜찮습니다.
7. CPU 온도 얻기
이 Python 스크립트를 사용하면 CPU 온도를 알기 위해 어떤 소프트웨어도 필요하지 않습니다.
# 获取CPU温度
from time import sleep
from pyspectator.processor import Cpu
cpu = Cpu(monitoring_latency=1)
with cpu:
while True:
print(f'Temp: {cpu.temperature} °C')
sleep(2)
8. PDF 테이블 추출
때때로 PDF에서 테이블 데이터를 추출해야 할 때가 있습니다.
먼저 수작업 마무리를 떠올리시겠지만, 특히 작업량이 많은 경우에는 수작업이 더 힘들 수 있습니다.
그러면 PDF 테이블을 추출하는 소프트웨어와 웹 도구가 생각날 수도 있습니다.
아래의 간단한 스크립트는 단 몇 초 만에 동일한 작업을 수행하는 데 도움이 됩니다.
# 方法①
import camelot
tables = camelot.read_pdf("tables.pdf")
print(tables)
tables.export("extracted.csv", f="csv", compress=True)
# 方法②, 需要安装Java8
import tabula
tabula.read_pdf("tables.pdf", pages="all")
tabula.convert_into("table.pdf", "output.csv", output_format="csv", pages="all")
PDF 문서의 내용은 표를 포함하여 다음과 같습니다.
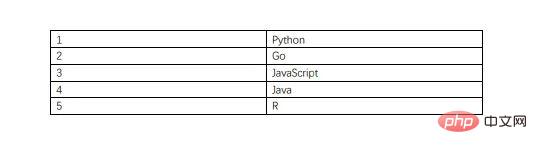
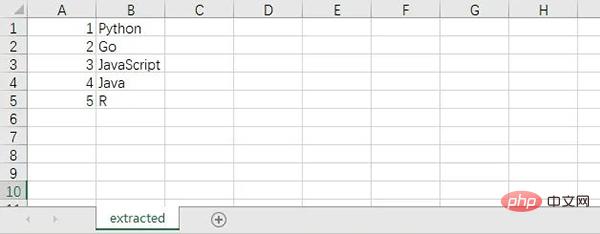
추출된 CSV 파일 내용은 다음과 같습니다.
9. 스크린샷
이 스크립트는 스크린샷 소프트웨어를 사용하지 않고 간단히 스크린샷을 찍습니다.
아래 코드에서는 Python에서 스크린샷을 찍는 두 가지 방법을 보여줍니다.
# 方法①
from mss import mss
with mss() as screenshot:
screenshot.shot(output='scr.png')
# 方法②
import PIL.ImageGrab
scr = PIL.ImageGrab.grab()
scr.save("scr.png")
10. 맞춤법 검사기
이 Python 스크립트는 맞춤법 검사를 수행할 수 있습니다. 물론 중국어는 광범위하고 심오합니다.
아아아아위 내용은 10가지 흥미로운 고급 Python 스크립트, 수집에 권장됩니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!