
여러 가지 Python 정규 표현식을 컴파일했으며 바로 사용할 수 있습니다!

- PHPz앞으로
- 2023-04-14 18:07:051707검색

정규 표현식을 사용하여 텍스트를 검색, 편집 및 조작할 수 있습니다. Python RegEx는 거의 모든 회사에서 널리 사용되며 해당 응용 프로그램이 업계에서 좋은 평가를 받고 있어 정규 표현식이 점점 더 중요해지고 있습니다.
오늘은 Python 정규식을 함께 배워보겠습니다.
정규식을 사용하는 이유.
이 질문에 답하기 위해 먼저 우리가 직면한 다양한 문제를 정규 표현식을 사용하여 해결할 수 있는지 살펴보겠습니다.
다음 시나리오를 고려해보세요.
기사 마지막 부분에 많은 양의 데이터가 포함된 로그 파일이 있습니다. 이 로그 파일에서 날짜와 시간만 얻으려고 합니다. 언뜻 보면 로그 파일의 가독성이 매우 낮습니다.

이 경우 정규식을 사용하면 패턴을 식별하고 필요한 정보를 쉽게 추출할 수 있습니다.
다음 시나리오를 고려해 보세요. 귀하는 영업 사원이고 많은 이메일 주소를 가지고 있으며 그 중 대부분이 가짜이거나 유효하지 않습니다. 아래 이미지를 보십시오.

우리가 할 수 있는 것은 확인할 수 있는 정규식 공식을 사용하는 것입니다. 이메일 주소 형식을 변경하고 실제 ID에서 가짜 ID를 필터링합니다.
다음 시나리오는 영업사원 예와 매우 유사합니다. 다음 이미지를 고려하세요.

전화번호를 어떻게 확인하고 출신 국가에 따라 분류합니까?
각 올바른 숫자에는 정규식을 사용하여 추적하고 추적할 수 있는 특정 패턴이 있습니다.
다음은 또 다른 간단한 시나리오입니다.
이름, 나이, 주소와 같은 세부 정보가 포함된 학생 데이터베이스가 있습니다. 지역 코드가 원래 59006이었지만 지금은 59076으로 변경된 상황을 생각해 보십시오. 각 학생에 대해 이 코드를 수동으로 업데이트하는 데 시간이 많이 걸리고 프로세스도 매우 길어집니다.
기본적으로 정규식을 사용하여 이러한 문제를 해결하려면 먼저 핀 코드가 포함된 학생 데이터에서 특정 문자열을 찾은 다음 모두 새 문자열로 바꿉니다.
정규식이란 무엇입니까
정규식은 텍스트 문자열의 검색 패턴을 식별하는 데 사용됩니다. 또한 데이터의 정확성을 찾는 데도 도움이 됩니다. 정규식을 사용하여 데이터 찾기, 바꾸기 등을 수행할 수도 있습니다.
다음 예를 고려해 보세요.

주어진 문자열에 대한 모든 데이터 중에서 도시만 필요하다고 가정하면 형식화된 방식으로 이름과 도시만 포함하는 사전으로 변환할 수 있습니다. 이제 문제는 이름과 도시를 추측하는 패턴을 식별할 수 있느냐는 것입니다. 그리고 나이도 알 수 있는데, 나이가 들수록 쉽죠? 그것은 단지 정수입니다.
이 이름으로 무엇을 할까요? 패턴을 보면 모든 이름이 대문자로 시작됩니다. 정규식을 사용하면 이 방법을 사용하여 이름과 나이를 식별할 수 있습니다.
다음 코드를 사용할 수 있습니다.
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)출력:
{'Janice': '22', 'Theon': '33', 'Gabriel': '44', 'Joey': '21'}정규식의 몇 가지 예:
정규식을 사용하여 많은 작업을 수행할 수 있습니다. 여기에서는 정규식 사용법을 더 잘 이해하는 데 도움이 되는 몇 가지 매우 중요한 사항을 나열했습니다.
먼저 문자열에서 특정 단어를 찾는 방법을 확인해 보겠습니다.
문자열에서 단어 찾기
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")여기서 하는 모든 작업은 inform이라는 단어가 검색 문자열에 있는지 검색하는 것입니다.
물론 다음 코드도 최적화할 수 있습니다.
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)여기서는 이 특별한 경우 infor가 두 번 검색됩니다. 하나는 정보에서 나오고, 다른 하나는 정보에서 나옵니다.
위에 표시된 것처럼 정규식에서 단어를 찾는 것은 매우 간단합니다.
다음으로 정규식을 사용하여 반복자를 생성하는 방법을 알아봅니다.
반복자 생성
반복자 생성은 문자열의 시작 및 끝 인덱스를 찾고 대상으로 지정하는 간단한 프로세스입니다. 다음 예를 고려하십시오.
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str
locTuple = i.span()
print(locTuple)발견된 각 일치 항목에 대해 시작 및 끝 인덱스가 인쇄됩니다. 위 프로그램을 실행하면 출력은 다음과 같습니다.
(11, 18) (38, 45)
다음으로 정규식을 사용하여 단어와 패턴을 일치시키는 방법을 확인해 보겠습니다.
将单词与模式匹配
考虑一个输入字符串,我们必须将某些单词与该字符串匹配。要详细说明,请查看以下示例代码:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)字符串中有什么共同点?可以看到字母“a”和“t”在所有输入字符串中都很常见。代码中的 [shmp] 表示要查找的单词的首字母,因此,任何以字母 s、h、m 或 p 开头的子字符串都将被视为匹配,其中任何一个,并且最后必须跟在“at”后面。
Output:
hat mat pat
接下来我们将检查如何使用正则表达式一次匹配一系列字符。
匹配一系列字符范围
我们希望输出第一个字母应该在 h 和 m 之间并且必须紧跟 at 的所有单词。看看下面的例子,我们应该得到的输出是 hat 和 mat
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)Output:
hat mat
现在让我们稍微改变一下上面的程序以获得一个不同的结果
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)发现细微差别了吗,我们在正则表达式中添加了插入符号 (^),它的作用否定了它所遵循的任何效果。我们不会给出从 h 到 m 开始的所有内容的输出,而是会向我们展示除此之外的所有内容的输出。
我们可以预期的输出是不以 h 和 m 之间的字母开头但最后仍然紧随其后的单词。Output:
sat pat
替换字符串:
接下来,我们可以使用正则表达式检查另一个操作,其中我们将字符串中的一项替换为其他内容:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)在上面的示例中,单词 rat 被替换为单词 food。正则表达式的替代方法就是利用这种情况,它也有各种各样的实际用例。Output:
hat food mat pat
反斜杠问题
import re randstr = "Here is Edureka" print(randstr)
Output:
Here is Edureka
这就是反斜杠问题,其中一个斜线从输出中消失了,这个特殊问题可以使用正则表达式来解决。
import re randstr = "Here is Edureka" print(re.search(r"Edureka", randstr))
Output:
<re.Match object; span=(8, 16), match='Edureka'>
这就是使用正则表达式解决反斜杠问题的简单方法。
匹配单个字符
使用正则表达式可以轻松地单独匹配字符串中的单个字符
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))Output:
Matches: 1
删除换行符
我们可以在 Python 中使用正则表达式轻松删除换行符
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)Output:
You Never Walk Alone Liverpool FC You Never Walk Alone Liverpool FC
可以从上面的输出中看到,新行已被空格替换,并且输出打印在一行上。
还可以使用许多其他东西,具体取决于要替换字符串的内容
: Backspace : Formfeed : Carriage Return : Tab : Vertical Tab
可以使用如下代码
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))Output:
Matches: 5
从上面的输出可以看出,d 匹配字符串中存在的整数。但是,如果我们用 D 替换它,它将匹配除整数之外的所有内容,与 d 完全相反。
接下来我们了解一些在 Python 中使用正则表达式的重要实际例子。
正则表达式的实际例子
我们将检查使用最为广泛的 3 个主要用例
- 电话号码验证
- 电子邮件地址验证
- 网页抓取
电话号码验证
需要在任何相关场景中轻松验证电话号码
考虑以下电话号码:
- 444-122-1234
- 123-122-78999
- 111-123-23
- 67-7890-2019
电话号码的一般格式如下:
- 以 3 位数字和“-”符号开头
- 3 个中间数字和“-”号
- 最后4位数
我们将在下面的示例中使用 w,请注意 w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")Output:
Valid phone number
电子邮件验证
在任何情况下验证电子邮件地址的有效性。
考虑以下电子邮件地址示例:
- Anirudh@gmail.com
- Anirudh@com
- AC.com
- 123 @.com
我们只需一眼就可以从无效的邮件 ID 中识别出有效的邮件 ID,但是当我们的程序为我们做这件事时,却并没有那么容易,但是使用正则,就非常简单了。
指导思路,所有电子邮件地址应包括:
- 1 到 20 个小写和/或大写字母、数字以及 . _ % +
- 一个@符号
- 2 到 20 个小写和大写字母、数字和加号
- 一个点号
- 2 到 3 个小写和大写字母
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))Output:
Email Matches: 1
从上面的输出可以看出,我们输入的 4 封电子邮件中有一封有效的邮件。
这基本上证明了使用正则表达式并实际使用它们是多么简单和高效。
网页抓取
从网站上删除所有电话号码以满足需求。
要了解网络抓取,请查看下图:
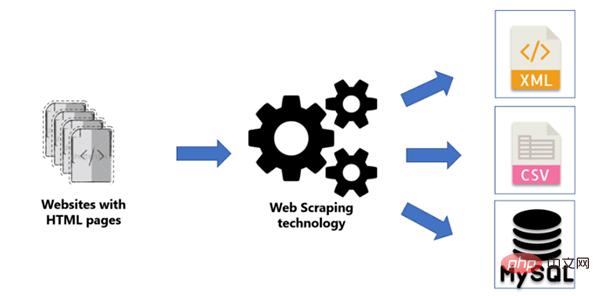
我们已经知道,一个网站将由多个网页组成,我们需要从这些页面中抓取一些信息。
网页抓取主要用于从网站中提取信息,可以将提取的信息以 XML、CSV 甚至 MySQL 数据库的形式保存,这可以通过使用 Python 正则表达式轻松实现。
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)Output:
(257) 563-7401 (372) 587-2335 (786) 713-8616 (793) 151-6230 (492) 709-6392 (654) 393-5734 (404) 960-3807 (314) 244-6306 (947) 278-5929 (684) 579-1879 (389) 737-2852 ...
我们首先是通过导入执行网络抓取所需的包,最终结果包括作为使用正则表达式完成网络抓取的结果而提取的电话号码。
위 내용은 여러 가지 Python 정규 표현식을 컴파일했으며 바로 사용할 수 있습니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!