



문서 구문 분석에는 문서의 데이터를 검사하고 유용한 정보를 추출하는 작업이 포함됩니다. 자동화를 통해 수작업을 많이 줄일 수 있습니다. 널리 사용되는 구문 분석 전략은 문서를 이미지로 변환하고 인식을 위해 컴퓨터 비전을 사용하는 것입니다. 문서 이미지 분석은 문서 이미지의 픽셀 데이터로부터 정보를 얻는 기술을 말하며, 어떤 경우에는 기대되는 결과(텍스트, 이미지, 차트, 숫자, 표, 수식)가 무엇인지에 대한 명확한 답이 없습니다. ..).

OCR(Optical Character Recognition, 광학 문자 인식)은 컴퓨터 비전을 통해 이미지 속 텍스트를 감지하고 추출하는 프로세스입니다. 이는 제1차 세계대전 중에 이스라엘 과학자 에마누엘 골드버그(Emanuel Goldberg)가 문자를 읽고 이를 전신 코드로 변환할 수 있는 기계를 만들면서 발명되었습니다. 이제 이 분야는 이미지 처리, 텍스트 위치 파악, 문자 분할 및 문자 인식이 혼합된 매우 정교한 수준에 도달했습니다. 기본적으로 텍스트에 대한 객체 감지 기술입니다.
이 기사에서는 문서 구문 분석에 OCR을 사용하는 방법을 보여 드리겠습니다. 다른 유사한 상황(복사, 붙여넣기, 실행)에서 쉽게 사용할 수 있는 몇 가지 유용한 Python 코드를 보여주고 전체 소스 코드 다운로드를 제공하겠습니다.
여기에서는 상장 회사의 PDF 형식 재무제표를 예로 들어 보겠습니다(아래 링크).
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

이 PDF에서 텍스트 감지 및 추출 , 그래프 및 표
환경 설정
문서 구문 분석에서 성가신 부분은 다양한 유형의 데이터(텍스트, 그래프, 표)를 위한 도구가 너무 많고 그 중 어느 것도 완벽하게 작동하지 않는다는 것입니다. 가장 널리 사용되는 방법과 패키지는 다음과 같습니다.
- 문서를 텍스트로 처리합니다. PyPDF2를 사용하여 텍스트를 추출하고, Camelot 또는 TabulaPy를 사용하여 표를 추출하고, PyMuPDF를 사용하여 그래픽을 추출합니다.
- 문서를 이미지로 변환(OCR): pdf2image를 사용하여 변환하고, PyTesseract 및 기타 여러 라이브러리를 사용하여 데이터를 추출하거나, LayoutParser를 사용하세요.
"PDF 파일을 직접 처리하지 않고 페이지를 이미지로 변환할 수 있는 이유는 무엇입니까?"라고 질문하실 수도 있습니다. 이 전략의 가장 큰 단점은 인코딩 문제입니다. 문서는 여러 인코딩(예: UTF-8, ASCII, 유니코드)으로 될 수 있으므로 텍스트로 변환하면 데이터가 손실될 수 있습니다. 따라서 이 문제를 피하기 위해 OCR을 사용하고 PDF2image를 사용하여 페이지를 이미지로 변환하겠습니다. PDF 렌더링 라이브러리 Poppler가 필요합니다.
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
파일을 쉽게 읽을 수 있습니다.
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a page스크린샷과 똑같이 페이지 이미지를 로컬에 저장하려면 다음 코드를 사용할 수 있습니다.
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
마지막으로 CV 엔진을 설정해야 합니다. 사용. LayoutParser는 딥러닝을 기반으로 한 최초의 OCR용 범용 패키지인 것으로 보입니다. 작업을 수행하기 위해 두 가지 잘 알려진 모델을 사용합니다.
Detection: Facebook의 가장 진보된 개체 감지 라이브러리(여기서는 두 번째 버전 Detectron2가 사용됩니다).
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract: 1985년 Hewlett-Packard가 만들고 현재 Google이 개발한 가장 유명한 OCR 시스템입니다.
pip install "layoutparser[ocr]"
이제 정보 감지 및 추출을 위한 OCR 프로그램을 시작할 준비가 되었습니다.
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
Detection
(대상) 감지는 사진에서 정보 조각을 찾아 직사각형 테두리로 둘러싸는 과정입니다. 문서 구문 분석의 경우 정보는 제목, 텍스트, 그래픽, 표입니다...
몇 가지 항목이 포함된 복잡한 페이지를 살펴보겠습니다.
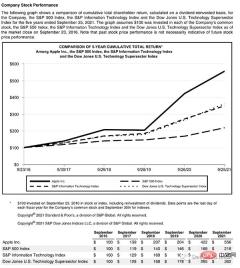
이 페이지는 제목으로 시작하고 텍스트 블록이 있습니다. 그런 다음 그래프와 테이블이 있으므로 이러한 객체를 인식하려면 훈련된 모델이 필요합니다. 운 좋게도 Detectron이 이를 수행할 수 있으므로 여기에서 모델을 선택하고 코드에서 해당 경로를 지정하기만 하면 됩니다.
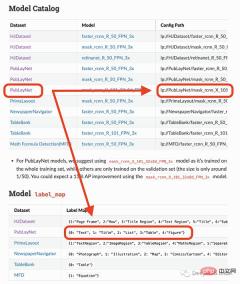
제가 사용할 모델은 4개의 객체(텍스트, 제목, 목록, 표, 그래프)만 감지할 수 있습니다. 따라서 방정식과 같은 다른 항목을 식별해야 하는 경우 다른 모델을 사용해야 합니다.
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
提取
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
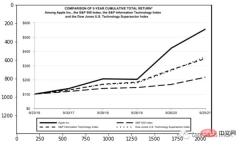
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
总结
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
위 내용은 Python 및 OCR을 사용한 문서 구문 분석의 전체 코드 데모(코드 첨부)의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Python 文本终端 GUI 框架,太酷了Apr 12, 2023 pm 12:52 PM
Python 文本终端 GUI 框架,太酷了Apr 12, 2023 pm 12:52 PMCurses首先出场的是 Curses[1]。CurseCurses 是一个能提供基于文本终端窗口功能的动态库,它可以: 使用整个屏幕 创建和管理一个窗口 使用 8 种不同的彩色 为程序提供鼠标支持 使用键盘上的功能键Curses 可以在任何遵循 ANSI/POSIX 标准的 Unix/Linux 系统上运行。Windows 上也可以运行,不过需要额外安装 windows-curses 库:pip install windows-curses 上面图片,就是一哥们用 Curses 写的 俄罗斯
 五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM
五个方便好用的Python自动化脚本Apr 11, 2023 pm 07:31 PM相比大家都听过自动化生产线、自动化办公等词汇,在没有人工干预的情况下,机器可以自己完成各项任务,这大大提升了工作效率。编程世界里有各种各样的自动化脚本,来完成不同的任务。尤其Python非常适合编写自动化脚本,因为它语法简洁易懂,而且有丰富的第三方工具库。这次我们使用Python来实现几个自动化场景,或许可以用到你的工作中。1、自动化阅读网页新闻这个脚本能够实现从网页中抓取文本,然后自动化语音朗读,当你想听新闻的时候,这是个不错的选择。代码分为两大部分,第一通过爬虫抓取网页文本呢,第二通过阅读工
 用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM
用Python写了个小工具,再复杂的文件夹,分分钟帮你整理!Apr 11, 2023 pm 08:19 PM糟透了我承认我不是一个爱整理桌面的人,因为我觉得乱糟糟的桌面,反而容易找到文件。哈哈,可是最近桌面实在是太乱了,自己都看不下去了,几乎占满了整个屏幕。虽然一键整理桌面的软件很多,但是对于其他路径下的文件,我同样需要整理,于是我想到使用Python,完成这个需求。效果展示我一共为将文件分为9个大类,分别是图片、视频、音频、文档、压缩文件、常用格式、程序脚本、可执行程序和字体文件。# 不同文件组成的嵌套字典 file_dict = { '图片': ['jpg','png','gif','webp
 用 WebAssembly 在浏览器中运行 PythonApr 11, 2023 pm 09:43 PM
用 WebAssembly 在浏览器中运行 PythonApr 11, 2023 pm 09:43 PM长期以来,Python 社区一直在讨论如何使 Python 成为网页浏览器中流行的编程语言。然而网络浏览器实际上只支持一种编程语言:JavaScript。随着网络技术的发展,我们已经把越来越多的程序应用在网络上,如游戏、数据科学可视化以及音频和视频编辑软件。这意味着我们已经把繁重的计算带到了网络上——这并不是JavaScript的设计初衷。所有这些挑战提出了对新编程语言的需求,这种语言可以提供快速、可移植、紧凑和安全的代码执行。因此,主要的浏览器供应商致力于实现这个想法,并在2017年向世界推出
 一文读懂层次聚类(Python代码)Apr 11, 2023 pm 09:13 PM
一文读懂层次聚类(Python代码)Apr 11, 2023 pm 09:13 PM首先要说,聚类属于机器学习的无监督学习,而且也分很多种方法,比如大家熟知的有K-means。层次聚类也是聚类中的一种,也很常用。下面我先简单回顾一下K-means的基本原理,然后慢慢引出层次聚类的定义和分层步骤,这样更有助于大家理解。层次聚类和K-means有什么不同?K-means 工作原理可以简要概述为: 决定簇数(k) 从数据中随机选取 k 个点作为质心 将所有点分配到最近的聚类质心 计算新形成的簇的质心 重复步骤 3 和 4这是一个迭代过程,直到新形成的簇的质心不变,或者达到最大迭代次数
 从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM
从头开始构建,DeepMind新论文用伪代码详解TransformerApr 09, 2023 pm 08:31 PM2017 年 Transformer 横空出世,由谷歌在论文《Attention is all you need》中引入。这篇论文抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。这一开创性的研究颠覆了以往序列建模和 RNN 划等号的思路,如今被广泛用于 NLP。大热的 GPT、BERT 等都是基于 Transformer 构建的。Transformer 自推出以来,研究者已经提出了许多变体。但大家对 Transformer 的描述似乎都是以口头形式、图形解释等方式介绍该架构。关于 Tra
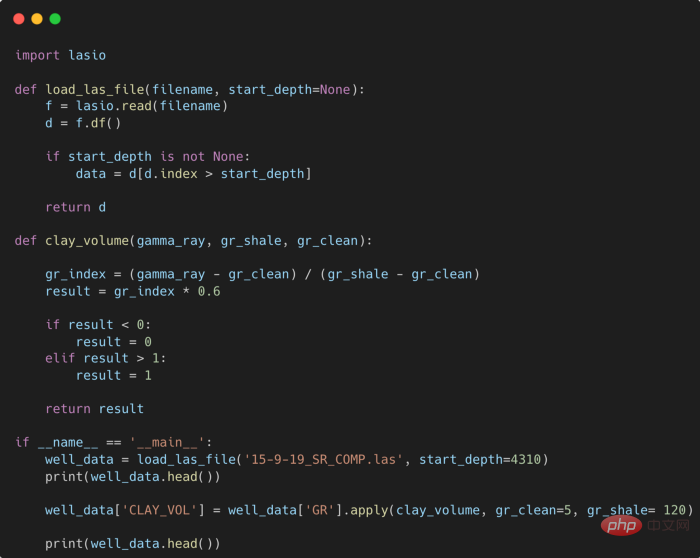 提高Python代码可读性的五个基本技巧Apr 11, 2023 pm 09:07 PM
提高Python代码可读性的五个基本技巧Apr 11, 2023 pm 09:07 PM译者 | 赵青窕审校 | 孙淑娟你是否经常回头看看6个月前写的代码,想知道这段代码底是怎么回事?或者从别人手上接手项目,并且不知道从哪里开始?这样的情况对开发者来说是比较常见的。Python中有许多方法可以帮助我们理解代码的内部工作方式,因此当您从头来看代码或者写代码时,应该会更容易地从停止的地方继续下去。在此我给大家举个例子,我们可能会得到如下图所示的代码。这还不是最糟糕的,但有一些事情需要我们去确认,例如:在load_las_file函数中f和d代表什么?为什么我们要在clay函数中检查结果
 Python-master,实用Python脚本合集!Apr 11, 2023 pm 05:04 PM
Python-master,实用Python脚本合集!Apr 11, 2023 pm 05:04 PMPython这门语言很适合用来写些实用的小脚本,跑个自动化、爬虫、算法什么的,非常方便。这也是很多人学习Python的乐趣所在,可能只需要花个礼拜入门语法,就能用第三方库去解决实际问题。我在Github上就看到过不少Python代码的项目,几十行代码就能实现一个场景功能,非常实用。比方说仓库Python-master里就有很多不错的实用Python脚本,举几个简单例子:1. 创建二维码import pyqrcode import png from pyqrcode import QRCode


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

맨티스BT
Mantis는 제품 결함 추적을 돕기 위해 설계된 배포하기 쉬운 웹 기반 결함 추적 도구입니다. PHP, MySQL 및 웹 서버가 필요합니다. 데모 및 호스팅 서비스를 확인해 보세요.

MinGW - Windows용 미니멀리스트 GNU
이 프로젝트는 osdn.net/projects/mingw로 마이그레이션되는 중입니다. 계속해서 그곳에서 우리를 팔로우할 수 있습니다. MinGW: GCC(GNU Compiler Collection)의 기본 Windows 포트로, 기본 Windows 애플리케이션을 구축하기 위한 무료 배포 가능 가져오기 라이브러리 및 헤더 파일로 C99 기능을 지원하는 MSVC 런타임에 대한 확장이 포함되어 있습니다. 모든 MinGW 소프트웨어는 64비트 Windows 플랫폼에서 실행될 수 있습니다.

스튜디오 13.0.1 보내기
강력한 PHP 통합 개발 환경

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

