
2022년 시계열 예측 및 분류 분야 딥러닝 연구 진행 검토

- PHPz앞으로
- 2023-04-13 12:25:021121검색
시계열 예측에서 트랜스포머의 쇠퇴와 시계열 임베딩 방법의 등장, 이상 탐지 및 분류도 진전을 이루었습니다
2022년에는 전 분야가 여러 측면에서 진전을 이루었습니다. 작년에 등장한 보다 유망하고 중요한 논문과 Flow Forecast(FF) 예측 프레임워크. ㅋㅋㅋ
변압기 관련 연구 Autoformer, Pyraformer, Fedformer 등의 효과와 문제점을 비교해 보세요
Autoformer(Neurips 2021), Pyraformer(ICLR 2022), Fedformer(ICML 2022), EarthFormer(Neurips 2022) 및 Non-Stationary Transformer(Neurips) ) 및 기타 모델을 통해 시계열 예측 아키텍처의 Transformer 시리즈가 계속해서 성장하고 있습니다. 그러나 데이터를 정확하게 예측하고 기존 방법을 능가하는 이러한 모델의 능력은 특히 새로운 연구(나중에 논의할)에 비추어 볼 때 여전히 의문의 여지가 있습니다.
Autoformer: Informer 모델의 성능이 확장되고 향상되었습니다. Autoformer는 모델이 표준 주의보다 시간적 종속성을 더 잘 학습할 수 있도록 하는 자동 상관 메커니즘을 갖추고 있습니다. 시간적 데이터의 추세와 계절적 구성요소를 정확하게 분해하는 것을 목표로 합니다.
Pyraformer: 저자는 "PAM(Pyramid Attention Module)을 소개합니다. 이 모듈에서는 규모 간 트리 구조가 다양한 해상도의 기능을 요약하고 규모 내 이웃 연결이 다양한 범위의 시간적 의존성을 모델로 삼습니다." Fedformer: 이 모델은 시계열 데이터의 글로벌 추세를 포착하는 데 중점을 둡니다. 저자는 시계열의 전역적 특성을 포착하도록 설계된 계절 추세 분해 모듈을 제안합니다.
Earthformer: 아마도 이 논문 중 가장 독특한 논문일 것입니다. 특히 날씨, 기후, 농업과 같은 지구 시스템을 예측하는 데 초점을 맞추고 있습니다. 새로운 직육면체 주의 아키텍처가 도입되었습니다. 많은 고전적인 Transformer가 하천 및 돌발 홍수 예측에 대한 연구에 실패했기 때문에 이 논문은 큰 잠재력을 가져야 합니다.
Non-Stationary Transformer: 예측을 위해 변환기를 사용한 최신 논문입니다. 저자는 비정상 시계열을 처리하기 위해 Transformer를 더 잘 조정하는 것을 목표로 합니다. 그들은 주의력을 불안정하게 만드는 메커니즘과 일련의 안정화 메커니즘이라는 두 가지 메커니즘을 사용합니다. 이러한 메커니즘은 기존 Transformer 모델에 연결될 수 있으며 저자는 Informer, Autoformer 및 기존 Transformer에 연결하여 성능을 향상시키는 것을 테스트했습니다(부록에서는 Fedformer의 성능을 향상시킬 수 있음도 표시됨). 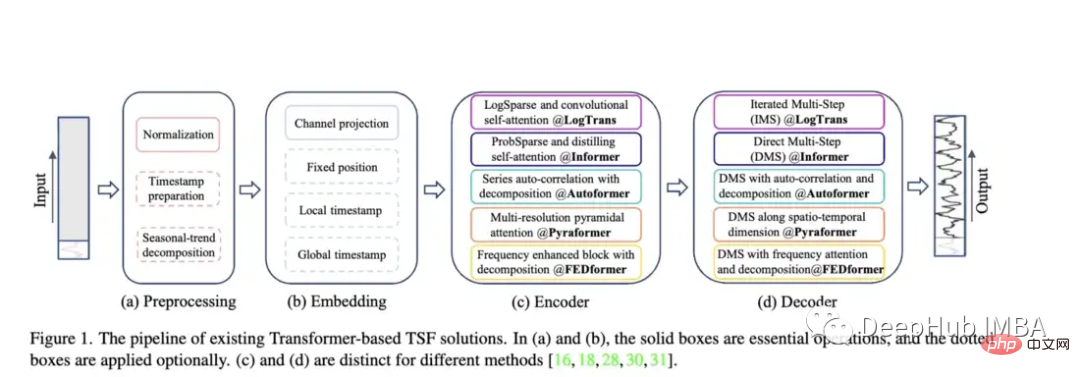
이 논문은 매우 훌륭하지만 Transformer 관련 논문만 비교합니다. 사실 더 간단한 방법과 비교해야 합니다. 예를 들어 단순 선형 회귀, LSTM/GRU 또는 XGB와 같은 트리 모델도 있습니다. 또 다른 점은 다른 시계열 관련 데이터 세트에서는 좋은 성능을 보지 못했기 때문에 일부 표준 데이터 세트로 제한되어서는 안 된다는 것입니다. 예를 들어 정보 제공자는 강의 흐름을 정확하게 예측하는 데 큰 문제가 있으며 LSTM이나 일반 Transformer에 비해 성능이 떨어지는 경우가 많습니다. 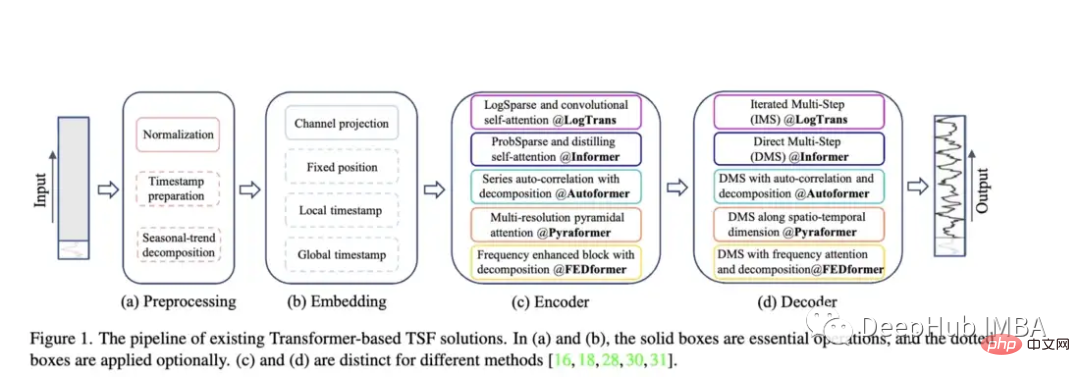
실제로는 최첨단 방법과 혁신적인 모델을 중요하게 생각하는 사람으로서 소위 "좋은" 모델이 작동하도록 몇 달 동안 노력했지만 결국 그렇지 않다는 것을 알게 되었습니다. 간단한 선형 회귀 분석도 수행합니다. 이번 달의 요점은 무엇입니까? 소위 좋은 모델의 요점은 무엇입니까?
모든 트랜스포머 페이퍼는 제한된 평가라는 동일한 문제를 안고 있습니다. 복잡한 모델은 처음부터 더 엄격한 비교와 단점에 대한 명확한 설명을 요구해야 합니다. 단순한 모델보다 낫지만, 이를 얼버무리거나 단순히 사실이 아니라고 가정하기보다는 논문에 명시적으로 기술해야 합니다.
하지만 논문은 여전히 좋습니다. MovingMNIST 데이터세트의 Earthformer와 N- 평가는 다음과 같습니다. Body MNIST 데이터 세트를 대상으로 수행되었으며, 저자는 이를 사용하여 직육면체 Attention의 유효성을 검증하고 순간 강수 예측과 엘니뇨 주기 예측을 평가했습니다. 이는 물리적 지식을 Attention 모델 아키텍처에 통합한 좋은 예라고 생각합니다.
2. Transformers는 시계열 예측(2022)에 효과적인가요?
https://www.php.cn/link/bf4d73f316737b26f1e860da0ea63ec8
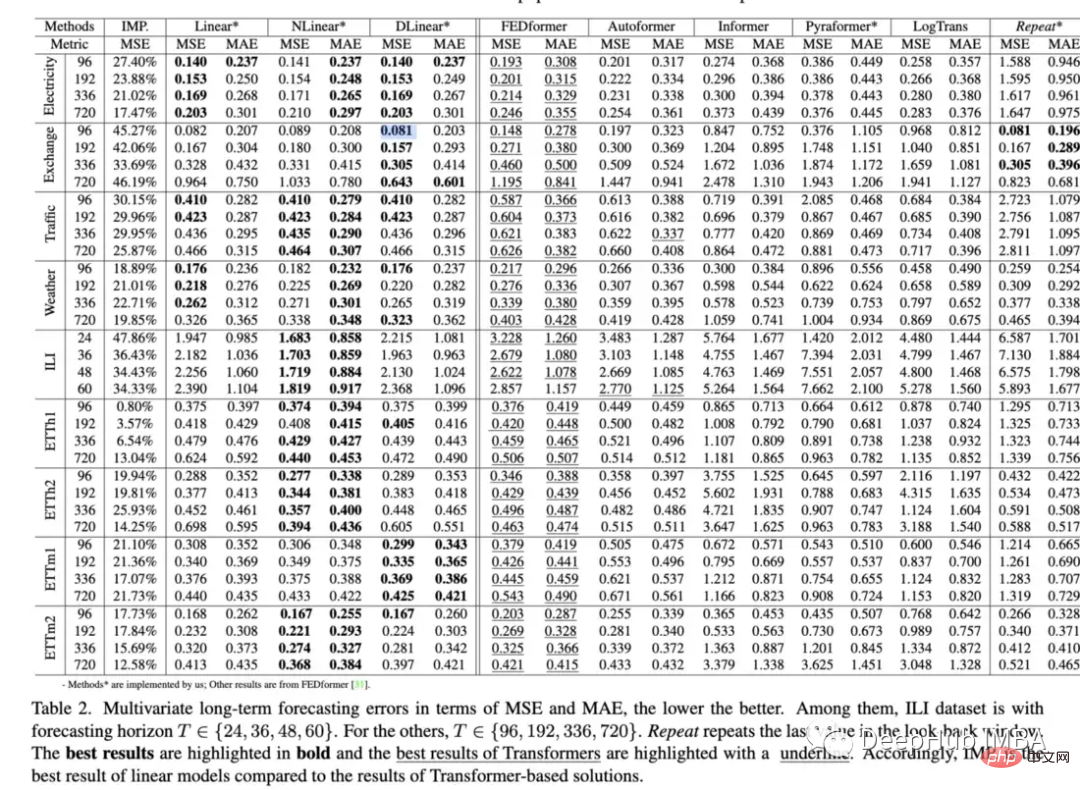
이 문서에서는 기준 방법과 비교하여 데이터를 예측하는 Transformer의 능력. 결과는 Transformer가 일반적으로 단순한 모델보다 성능이 떨어지고 조정하기 어렵다는 점을 어느 정도 재확인했습니다. 흥미로운 점:
- self-attention을 기본 선형 레이어로 대체하고 다음과 같은 사실을 발견했습니다. Informer는 점진적인 단순화와 함께 성장하며, 이는 적어도 기존 LTSF 벤치마크의 경우 self-attention 체계 및 기타 복잡한 모듈이 필요하지 않음을 나타냅니다."
- 전환 창을 늘리면 Transformers의 성능이 향상되는지 조사한 결과 다음과 같은 사실을 발견했습니다. SOTA 변환기는 약간 감소했는데, 이는 이러한 모델이 인접한 시계열 시간 정보에서만 유사한 데이터를 캡처함을 나타냅니다. ”
- 위치 임베딩이 실제로 시계열의 시간 순서를 잘 포착하는지 조사했습니다. 그들은 입력 시퀀스를 Transformer로 무작위로 섞음으로써 이 작업을 수행했습니다. 그들은 이 섞기가 결과에 영향을 미치지 않는다는 것을 발견했습니다(이 인코딩은 매우 번거롭습니다).
지난 몇 년 동안 Transformer 모델의 수많은 시계열 실험 결과는 대부분의 경우 이상적이지 않았으며 오랫동안 우리는 뭔가 잘못되었거나 사소한 일이 발생했다고 생각했습니다. 구현 세부 사항은 모두 누락되었습니다. 그러나 이 문서에는 일관된 아이디어가 있습니다. 단순한 모델이 Transformer보다 성능이 뛰어나면 계속 사용해야 합니다. 모든 Transformer는 본질적으로 결함이 있는 것입니까? 현재 메커니즘으로 돌아가야 할까요? lstm, gru 또는 간단한 피드포워드 모델로 돌아가야 할까요? 이러한 질문에 대한 답은 없지만 이 문서의 전체적인 영향은 아직 알 수 없을 것 같습니다. 결국, BERT는 처음에 NLP 환경에서 좋은 표현을 만드는 데 성공했습니다.
하지만 제 생각에는 시계열 Transformer를 완전히 고려해서는 안 됩니다. Fedformer는 단순 모델에 매우 가깝고 다양한 제거 작업에서 더 나은 성능을 발휘합니다. 많은 경우 벤치마크를 예측하기 어렵지만 데이터의 내부 표현은 매우 좋습니다. 내부 표현과 실제 예측 출력 사이의 단절을 더 잘 이해해야 합니다. 저자가 제안한 것처럼 마지막으로 Transformer의 모델은 다양한 이상 탐지 데이터 세트에서 매우 잘 작동할 수 있습니다. 아래에 소개하겠습니다.
변환기를 예측에 적용하는 데 중점을 둔 연구는 있지만, 이상 탐지에 대한 연구는 상대적으로 적습니다. 이 기사에서는 특수하게 구성된 모델을 사용하여 이상을 탐지하는 (비지도) 변환기를 소개합니다. 역학과 최소최대 전략 .이 기사에서는 서버 머신 데이터 세트, 풀링된 서버 메트릭, 토양 수분 활성 수동 및 NeurIPS-TS(5개의 서로 다른 데이터 세트로 구성됨)를 포함한 5개의 실제 데이터 세트에 대한 모델 성능을 평가합니다. 특히 두 번째 논문의 관점과 관련하여 이 모델에 대해 회의적인 사람이 있을 수 있지만 이 평가는 매우 엄격합니다. Neurips-TS는 이상 탐지 모델에 대한 보다 엄격한 평가를 제공하기 위해 특별히 설계된 최근 생성된 데이터세트입니다. 이 모델은 단순한 이상 탐지 모델에 비해 성능이 향상된 것으로 보입니다.
저자는 수많은 이상 탐지 데이터 세트에서 우수한 성능을 발휘하는 고유한 비지도 변환기를 제안합니다. 이것은 지난 몇 년간 시계열 Transformers 분야에서 가장 유망한 논문 중 하나입니다. 왜냐하면 미래에 여러 단계에 걸쳐 가능한 값의 거대한 범위를 예측하려고 하기 때문에 분류나 이상 탐지보다 예측이 더 어렵기 때문입니다. 분류나 이상 탐지를 무시한 채 예측에만 초점을 맞춘 연구가 너무 많습니다. Transformer에 대해서는 단순하게 시작해야 할까요?
4. WaveBound: 안정적인 시계열 예측을 위한 동적 오류 경계(Neurips 2022):
https://www.php.cn/link/ae95296e27d7f695f891cd26b4f37078
이 논문에서는 새로운 규칙성 형식을 소개합니다. 이는 심층 시계열 예측 모델(특히 위에서 언급한 변환기)의 학습을 향상시킬 수 있습니다.
저자는 기존 Transformer + LSTNet 모델에 연결하여 평가합니다. 그들은 대부분의 경우 성능이 크게 향상된다는 것을 발견했습니다. Fedformer와 같은 최신 모델이 아닌 Autoformer 모델만 테스트했지만.
새로운 형태의 정규화 또는 손실 함수는 일반적으로 기존 시계열 모델에 연결할 수 있으므로 항상 유용합니다. Fedformer + 비고정 메커니즘 + Wavebound를 결합하면 아마도 성능 면에서 단순 선형 회귀를 이길 수 있을 것입니다. :)
시계열 표현
Transformer가 예측 방향에서는 제대로 작동하지 않지만 Transformer는 유용한 시계열 표현을 만드는 데 많은 발전을 이루었습니다. 저는 이것이 시계열 딥러닝 분야에서 더 깊이 탐구되어야 할 인상적인 새로운 영역이라고 생각합니다.
5. TS2Vec: 시계열의 보편적 표현을 향하여(AAAI 2022)
https://www.php.cn/link/7690dd4db7a92524c684e3191919eb6b
TS2Vec은 시계열 표현을 학습하기 위한 범용 도구입니다. 임베딩 프레임. 논문 자체는 다소 오래되었지만 시계열 표현 학습 논문의 추세를 시작했습니다.
예측 및 이상 탐지를 위한 표현을 사용하여 평가된 이 모델은 Informer 및 Log Transformer와 같은 많은 모델보다 성능이 뛰어납니다.
6. 시계열 예측을 위한 잠재 계절 추세 표현 학습(Neurips 2022)
https://www.php.cn/link/0c5534f554a26f7aeb7c780e12bb1525

작성자가 모델을 만들었습니다. ( LAST)는 변동 추론을 사용하여 계절성과 추세를 분리하여 표현합니다.
저자는 표현에 예측 변수를 추가하여 다운스트림 예측 작업에서 모델을 평가했습니다(위 그림의 B 참조). 또한 표현의 시각화를 보여주는 흥미로운 플롯을 제공합니다. 이 모델은 TS2Vec 및 비용뿐만 아니라 여러 예측 작업에서 Autoformer보다 성능이 뛰어납니다. 또한 일부 예측 작업에서는 위에서 언급한 단순 선형 회귀보다 더 나은 성능을 발휘할 수 있는 것처럼 보입니다.

표준적인 예측 작업만 평가하는 모델에 대해서는 회의적이지만 이 모델은 예측 작업 자체보다는 표현에 중점을 두기 때문에 정말 빛납니다. 논문에 표시된 일부 그래프를 보면 모델이 계절성과 추세를 구별하는 방법을 학습하는 것으로 보입니다. 서로 다른 데이터 세트의 시각적 표현도 동일한 공간에 포함되어 있으며 상당한 차이를 보인다면 흥미로울 것입니다. C7, Cost: Contractive Learning of Disentangled Seasonal-Trend Representations for Time Series ForeCasting(ICLR 2022) 200DCECA07F99ddd178
이것은 2022년 초입니다. 얼마 전 ICLR에 발표된 논문은 계절 및 추세 표현 학습 측면에서 LaST와 매우 유사합니다. LaST는 성능을 크게 대체했기 때문에 여기서는 자세히 설명하지 않습니다. 하지만 읽고 싶은 분들을 위해 위에 링크를 걸어두었습니다.기타 흥미로운 논문
8. Attention Sharing을 통한 시계열 예측을 위한 도메인 적응(ICML 2022)
https://www.php.cn/link/d4ea5dacfff2d8a35c0952291779290d

부족한 경우 예측 중 데이터를 훈련할 때 DNN의 과제입니다. 본 논문에서는 풍부한 데이터가 있는 도메인에 대해 공유 주의 레이어를 사용한 다음 대상 도메인에 대해 별도의 모듈을 사용합니다.
제안된 모델은 합성 데이터세트와 실제 데이터세트를 모두 사용하여 평가됩니다. 합성 환경에서 콜드 스타트 학습과 퓨샷 학습을 테스트한 결과 해당 모델이 일반 Transformer 및 DeepAR보다 성능이 뛰어난 것으로 나타났습니다. 실제 데이터세트에는 Kaggle 소매 데이터세트가 채택되었으며 모델은 이 실험에서 기준선보다 훨씬 뛰어난 성능을 보였습니다.
콜드 스타트, 소수의 샘플, 유한 학습은 매우 중요한 주제이지만 시계열을 다루는 논문은 거의 없습니다. 이 모델은 이러한 문제 중 일부를 해결하기 위한 중요한 단계를 제공합니다. 이는 보다 다양하고 제한된 실제 데이터 세트에서 평가할 수 있으며 더 많은 기본 모델과 비교할 수 있음을 의미합니다. 미세 조정 또는 정규화의 이점은 모든 아키텍처에 맞게 조정할 수 있다는 것입니다.
9. 개입 시기: 중요한 사건에 대한 최적의 개입 정책 학습(Neurips 2022)
https://www.php.cn/link/f38fef4c0e4988792723c29a0bd3ca98
이 글은 "전형적인" 기사는 아니지만 " ” 시계열 문서이지만 이 문서의 초점은 기계가 고장나기 전에 개입할 최적의 시간을 찾는 데 있기 때문에 이 목록에 포함하기로 결정했습니다. 이것을 OTI 또는 최적의 개입 시간이라고 합니다.
OTI 평가와 관련된 문제 중 하나는 기본 생존 분석의 정확성입니다(잘못된 경우 평가도 잘못됩니다). 저자는 두 가지 정적 임계값에 대해 모델을 평가한 후 성능이 우수하다는 것을 확인하고 다양한 정책에 대한 예상 성능과 적중률을 표시했습니다.
이것은 흥미로운 문제이며 저자는 Openreview의 한 해설자가 다음과 같이 언급한 것처럼 새로운 솔루션을 제안합니다. 이 트레이드오프 곡선의 모양을 시각적으로 볼 수 있습니다.”
최근 데이터세트/벤치마크
마지막은 데이터세트의 벤치마크입니다
Monash 시계열 예측 아카이브(Neurips 2021): 이 아카이브의 목적. 다양한 시계열 데이터 세트의 "마스터 목록"을 제공하고 보다 권위 있는 벤치마크를 제공합니다. 리포지토리에는 의료, 소매, 차량 공유, 인구통계 등 다양한 산업에 걸친 20개 이상의 다양한 데이터 세트가 포함되어 있습니다.
https://www.php.cn/link/5d7009220a974e94404889274d3a9553
하계절 예측 Microsoft(2021): 이는 하위계절 예측을 개선하기 위해 기계 학습 사용을 장려하기 위해 Microsoft에서 공개적으로 발표한 데이터 세트입니다( 예: 다음 2~6주). 계절별 예측은 정부 기관이 기상 상황과 농부의 결정에 더 잘 대비하는 데 도움이 됩니다. Microsoft는 이 작업을 위해 여러 가지 벤치마크 모델을 포함시켰으며 일반적으로 딥 러닝 모델은 다른 방법에 비해 성능이 상당히 낮습니다. 최고의 DL 모델은 단순한 피드포워드 모델이며 Informer의 성능은 매우 낮습니다.
https://www.php.cn/link/c3cbd51329ff1a0169174e9a78126ee1
시계열 이상치 탐지 재검토: 이 논문에서는 기존의 많은 이상치/이상치 탐지 데이터 세트를 검토하고 35개의 새로운 데이터 세트를 제안합니다. 합성 데이터 세트와 4개의 실제 데이터 세트 -world 데이터 세트는 벤치마킹에 사용됩니다.
https://www.php.cn/link/03793ef7d06ffd63d34ade9d091f1ced
오픈 소스 시계열 예측 프레임워크 FF
Flow Forecast는 다음 모델을 포함하는 오픈 소스 시계열 예측 프레임워크입니다.
Vanilla LSTM (LSTM), SimpleTransformer, Multi-Head Attention, Transformer with a Linear Decoder, DARNN, Transformer XL, Informer, DeepAR, DSANet, SimpleLinearModel 등
Deep 사용 학습에 좋은 모델 코드입니다. 시간 예측을 위한 학습 출처, 관심있으신 분들은 확인해보시면 됩니다.
https://www.php.cn/link/fea33a31df7d05a276193d32621ecbe4
Summary
지난 2년 동안 우리는 시계열 예측 분야에서 Transformers의 상승과 하락 가능성을 보았습니다. 시계열 임베딩 방법, 이상 탐지 및 분류에 대한 추가적인 혁신이 이루어졌습니다.
그러나 딥 러닝 시계열의 경우 모델이 실행되는 위치와 성능 실패가 발생하는 위치가 매우 중요하기 때문에 해석 가능성, 시각화 및 벤치마킹 방법이 여전히 부족합니다. 또한 앞으로는 성능 향상을 위한 더 많은 형태의 정규화, 전처리, 전이 학습이 나타날 수 있습니다.
Transformer는 시계열 예측에 좋을 수도 있고 아닐 수도 있습니다. VIT와 마찬가지로 Transformer도 Patch가 등장하지 않으면 여전히 쓸모없다고 간주될 수 있습니다. 또한 시계열에서 Transformer의 개발이나 교체에 계속해서 관심을 기울일 것입니다.
위 내용은 2022년 시계열 예측 및 분류 분야 딥러닝 연구 진행 검토의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!