
OpenAI 및 Microsoft Sentinel 소개

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-13 12:07:111757검색
OpenAI 및 Microsoft Sentinel에 대한 시리즈에 오신 것을 환영합니다! OpenAI의 GPT3 제품군과 같은 LLM(Large Language Model)은 텍스트 요약, 인간과 유사한 대화, 코드 구문 분석 및 디버깅 및 기타 여러 예와 같은 혁신적인 사용 사례로 대중의 상상력을 장악하고 있습니다. 우리는 ChatGPT가 각본과 시를 쓰고, 음악을 작곡하고, 에세이를 쓰고, 컴퓨터 코드를 한 언어에서 다른 언어로 번역하는 것을 보았습니다.
이 놀라운 잠재력을 활용하여 보안 운영 센터의 사고 대응자를 도울 수 있다면 어떨까요? 물론 가능합니다. 그리고 쉽습니다! Microsoft Sentinel에는 Azure Logic Apps로 구동되는 자동화 플레이북에서 구현할 수 있는 OpenAI GPT3 모델용 기본 제공 커넥터가 이미 포함되어 있습니다. 이러한 강력한 워크플로우는 쉽게 작성하고 SOC 운영에 통합할 수 있습니다. 오늘은 OpenAI 커넥터를 살펴보고 Sentinel 이벤트와 관련된 MITRE ATT&CK 정책을 설명하는 간단한 사용 사례를 사용하여 구성 가능한 매개변수 중 일부를 살펴보겠습니다.
시작하기 전에 몇 가지 전제 조건을 살펴보겠습니다.
- 아직 Microsoft Sentinel 인스턴스가 없는 경우 무료 Azure 계정을 사용하여 인스턴스를 만들고 Sentinel 시작하기 빠른 시작을 따를 수 있습니다.
- Microsoft Sentinel Training Lab에서 사전 기록된 데이터를 사용하여 플레이북을 테스트합니다.
- GPT3 연결을 위해서는 API 키가 있는 개인 OpenAI 계정도 필요합니다.
- 또한 ChatGPT 및 Sentinel을 사용한 이벤트 처리에 대한 Antonio Formato의 훌륭한 블로그를 확인하는 것이 좋습니다. 여기서 Antonio는 현재까지 Sentinel의 거의 모든 OpenAI 모델 구현에 대한 참조가 된 매우 유용한 다목적 매뉴얼을 소개합니다.
기본적인 사고 트리거 플레이북(Sentinel > Automation > Create > Playbook with Incident Trigger)부터 시작하겠습니다.
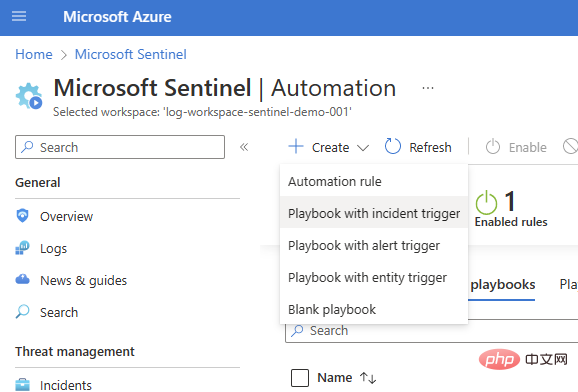
구독 및 리소스 그룹을 선택하고 스크립트 이름을 추가한 후 연결 탭으로 이동합니다. 하나 또는 두 개의 인증 옵션이 있는 Microsoft Sentinel이 표시되어야 합니다. 이 예에서는 관리 ID를 사용하고 있습니다. 하지만 아직 연결이 없는 경우 Logic Apps Designer에서 Sentinel 연결을 추가할 수도 있습니다.
플레이북을 보고 생성하면 몇 초 후에 리소스가 성공적으로 배포되고 논리 앱 디자이너 캔버스로 이동됩니다.
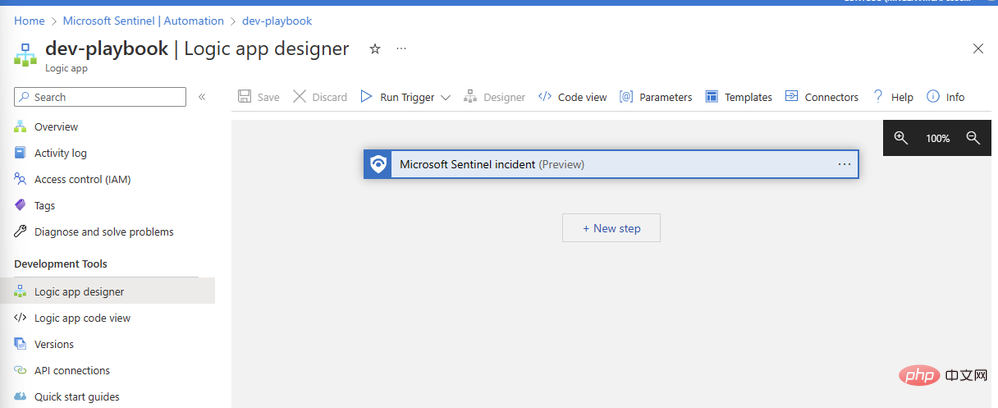
OpenAI 커넥터를 추가해 보겠습니다. New Step을 클릭하고 검색창에 "OpenAI"를 입력하세요. 상단 창에 커넥터가 있고 그 아래에 두 가지 작업이 표시됩니다. "이미지 만들기" 및 "GPT3 팁 완성":
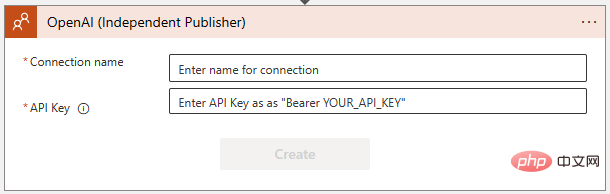
"GPT3 팁 완성"을 선택하세요. 그러면 다음 대화 상자에서 OpenAI API에 대한 연결을 생성하라는 메시지가 표시됩니다. 아직 키를 생성하지 않았다면 https://platform.openai.com/account/api-keys에서 키를 생성하고 안전한 곳에 보관하세요!
OpenAI API 키를 추가할 때 지침을 정확하게 따라야 합니다. "Bearer"라는 단어와 공백, 키 자체가 필요합니다.
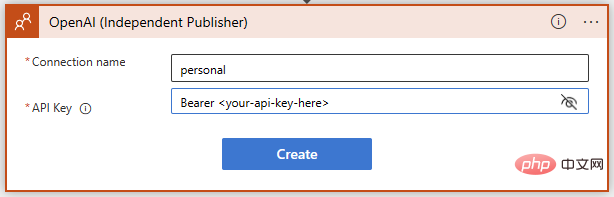
성공! 이제 프롬프트에 대한 GPT3 텍스트 완성이 준비되었습니다. AI 모델이 Sentinel 이벤트와 관련된 MITRE ATT&CK 전략 및 기술을 해석하도록 하고자 하므로 Sentinel의 이벤트 전략을 삽입하기 위해 동적 콘텐츠를 사용하여 간단한 프롬프트를 작성해 보겠습니다.
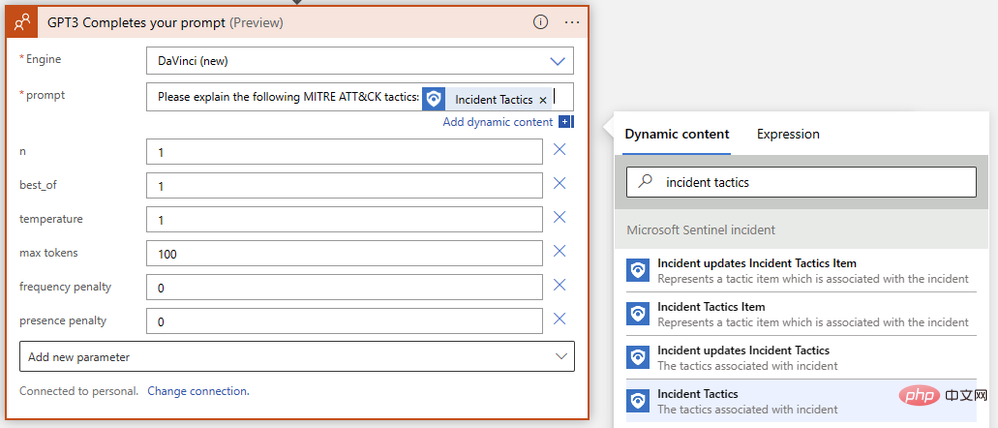
거의 완료되었습니다! 논리 앱을 저장하고 Microsoft Sentinel Events로 이동하여 테스트 실행해 보세요. 내 인스턴스에는 Microsoft Sentinel Training Lab의 테스트 데이터가 있으므로 악의적인 받은 편지함 규칙 경고에 의해 트리거된 이벤트에 대해 이 플레이북을 실행하겠습니다.
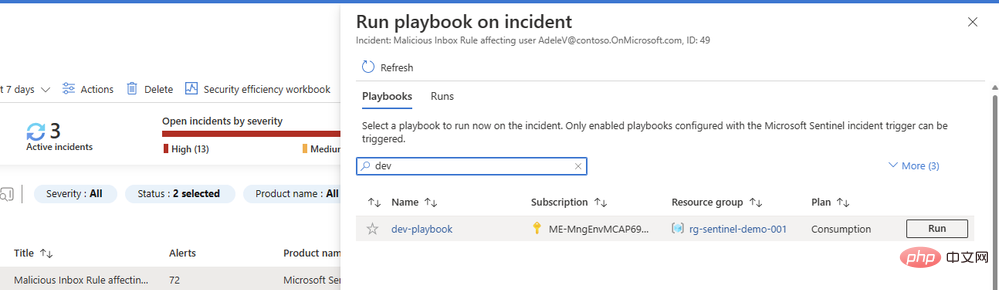
플레이북에 결과가 있는 댓글이나 작업을 추가하는 두 번째 작업을 구성하지 않은 이유가 궁금하실 것입니다. 우리는 거기에 도달할 것입니다. 그러나 먼저 프롬프트가 AI 모델에서 좋은 콘텐츠를 반환하는지 확인하고 싶습니다. 플레이북으로 돌아가서 새 탭에서 개요를 엽니다. 실행 기록에 녹색 확인 표시가 있는 항목이 표시되어야 합니다.
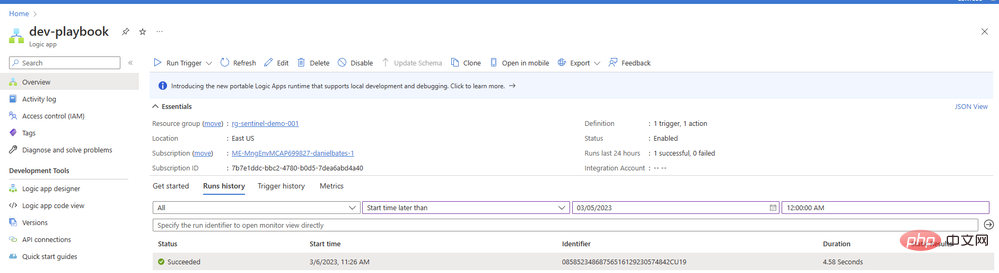
해당 항목을 클릭하면 실행 중인 논리 앱에 대한 세부 정보를 볼 수 있습니다. 모든 작업 블록을 확장하여 자세한 입력 및 출력 매개변수를 볼 수 있습니다.
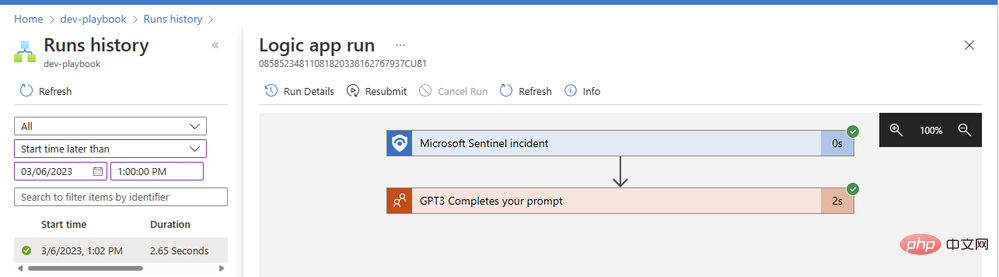
GPT3 작업은 단 2초 만에 성공적으로 완료되었습니다. 액션 블록을 클릭하여 확장하고 입력 및 출력의 전체 세부 정보를 살펴보겠습니다.
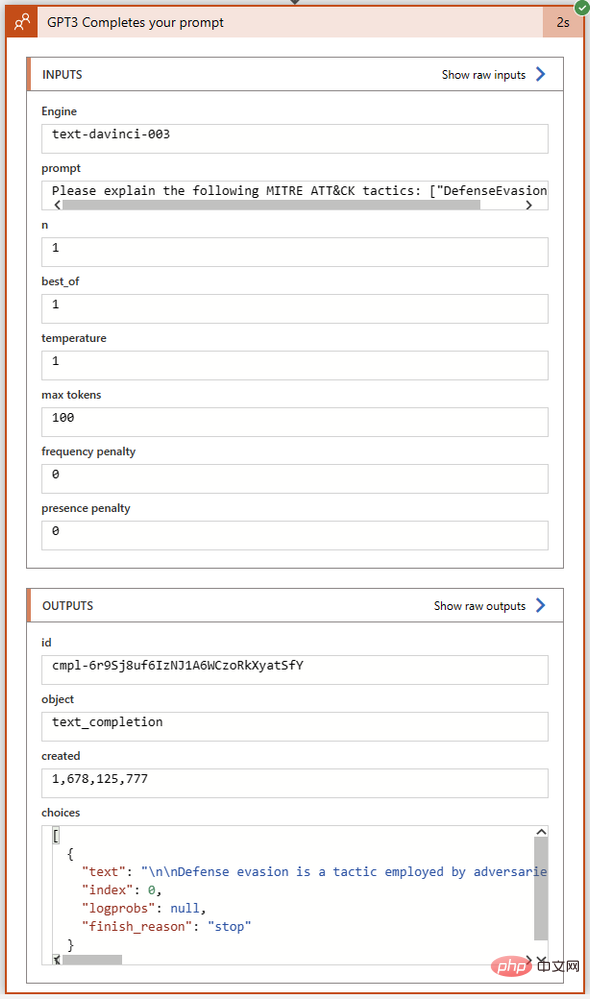
출력 섹션의 선택 필드를 자세히 살펴보겠습니다. 여기에서 GPT3가 완료 상태 및 오류 코드와 함께 완료 텍스트를 반환합니다. Choices 출력의 전체 텍스트를 Visual Studio Code에 복사했습니다.
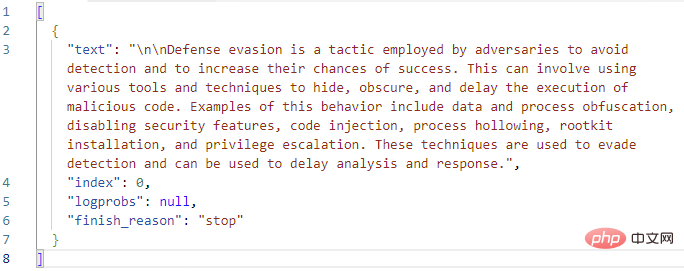
지금까지는 괜찮아 보입니다! GPT3는 "방어 회피"에 대한 MITRE 정의를 올바르게 확장합니다. 이 답변 텍스트가 포함된 이벤트 댓글을 생성하기 위해 플레이북에 논리적 작업을 추가하기 전에 GPT3 작업 자체의 매개변수를 다시 살펴보겠습니다. OpenAI 텍스트 완성 작업에는 엔진 선택 및 힌트를 제외한 총 9개의 매개변수가 있습니다.
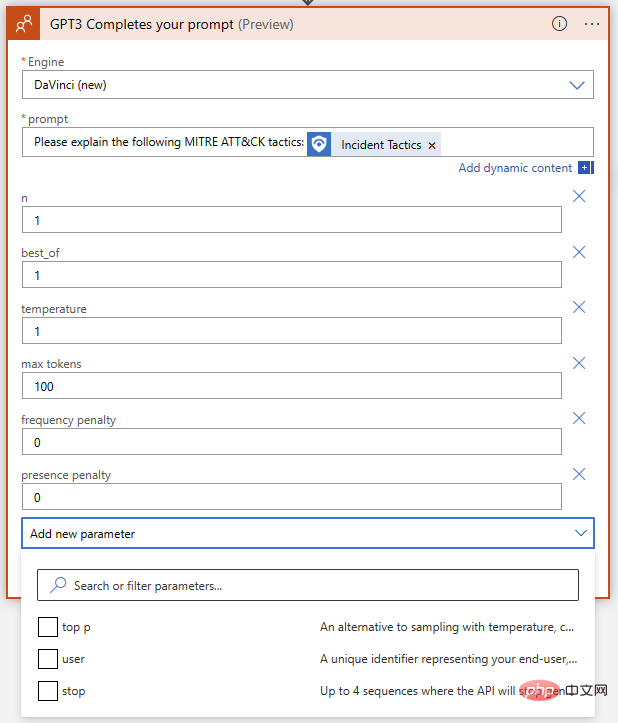
이러한 의미는 무엇이며, 최상의 결과를 얻으려면 어떻게 조정해야 합니까? 각 매개변수가 결과에 미치는 영향을 이해하는 데 도움이 되도록 OpenAI API Playground로 이동해 보겠습니다. 논리 앱이 실행되는 입력 필드에 정확한 프롬프트를 붙여넣을 수 있지만 제출을 클릭하기 전에 매개 변수가 일치하는지 확인하려고 합니다. 다음은 Azure Logic App OpenAI Connector와 OpenAI Playground 간의 매개 변수 이름을 비교하는 빠른 표입니다.
| Azure Logic App Connector | OpenAI Playground | Explanation |
| Engine | Model | 이 완성된 모델을 생성합니다. OpenAI 커넥터에서 Leonardo da Vinci(new), Leonardo da Vinci(old), Curie, Babbage 또는 Ada를 선택할 수 있으며, 각각 'text-davinci-003', 'text-davinci-002', 'text -curie에 해당합니다. 플레이그라운드의 -001' , 'text-babbage-001' 및 'text-ada-001' |
| n | NA | 각 프롬프트에 대해 생성된 완료 횟수입니다. 이는 플레이그라운드에서 프롬프트를 여러 번 다시 입력하는 것과 같습니다. |
| Best | (동일) | 여러 개의 완성을 생성하고 가장 좋은 것을 반환합니다. 주의해서 사용하세요. 토큰이 많이 소모됩니다! |
| 온도 | (동일) | 은 응답의 무작위성(또는 창의성)을 정의합니다. 모델이 항상 가장 확실한 선택을 반환하는 매우 결정적이고 반복적인 프롬프트 완료를 위해 0으로 설정합니다. 보다 임의적으로 창의적 응답을 최대화하려면 1로 설정하거나 원하는 경우 그 사이에 설정합니다. |
| 최대 토큰 | 최대 길이 | 토큰으로 제공되는 ChatGPT 응답의 최대 길이입니다. 토큰은 대략 4개의 문자와 같습니다. ChatGPT는 작성 당시 토큰 가격을 사용하며 1000개 토큰의 가격은 $0.002입니다. API 호출 비용에는 응답과 함께 힌트 토큰 길이가 포함되므로 응답당 가장 낮은 비용을 유지하려면 1000에서 힌트 토큰 길이를 빼서 응답을 제한하세요. |
| 빈도 페널티 | (동일) | 숫자 범위는 0~2입니다. 값이 높을수록 모델이 라인을 그대로 반복할 가능성이 줄어듭니다(라인의 동의어 또는 재진술을 찾으려고 시도합니다). |
| 페널티가 있습니다. | (동일) | 0에서 2 사이의 숫자입니다. 값이 높을수록 모델이 응답에서 이미 언급된 주제를 반복할 가능성이 줄어듭니다. |
| TOP | (동일) | 온도를 사용하지 않는 경우 "창의성" 응답을 설정하는 또 다른 방법입니다. 이 매개변수는 확률을 기준으로 가능한 답변 토큰을 제한합니다. 1로 설정하면 모든 토큰이 고려되지만 값이 작을수록 가능한 답변 세트가 상위 X%로 줄어듭니다. |
| 사용자 | 해당 없음 | 고유 식별자입니다. API 키가 이미 식별자 문자열로 사용되었으므로 이 매개변수를 설정할 필요가 없습니다. |
| Stop | Stop Sequence | 최대 4개의 시퀀스가 모델의 응답을 종료합니다. |
다음 OpenAI API 플레이그라운드 설정을 사용하여 논리 애플리케이션 작업을 일치시켜 보겠습니다.
- 모델: text-davinci-003
- 온도: 1
- 최대 길이: 100
이것은 GPT3 엔진 결과에서 얻은 것입니다. .
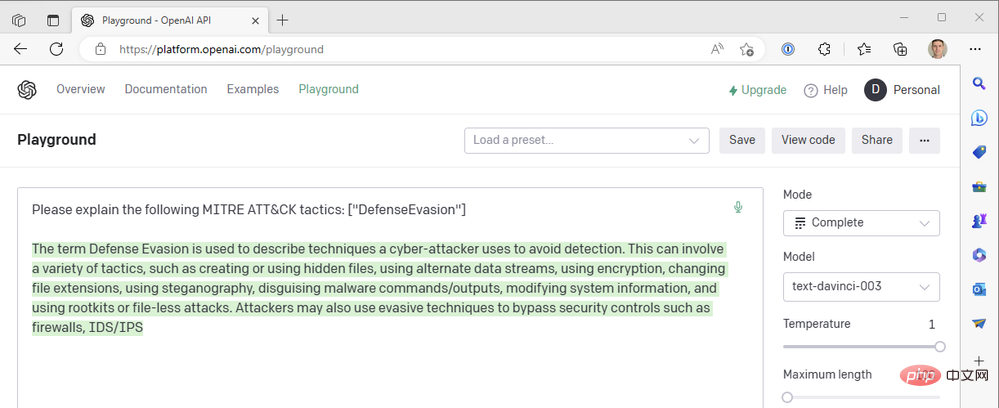
응답이 문장 중간에 잘린 것 같아서 최대 길이 매개변수를 늘려야 합니다. 그렇지 않으면 이 응답은 꽤 좋아 보입니다. 우리는 가능한 가장 높은 온도 값을 사용하고 있습니다. 보다 확실한 반응을 얻기 위해 온도를 낮추면 어떻게 될까요? 온도가 0인 경우를 예로 들어보겠습니다.
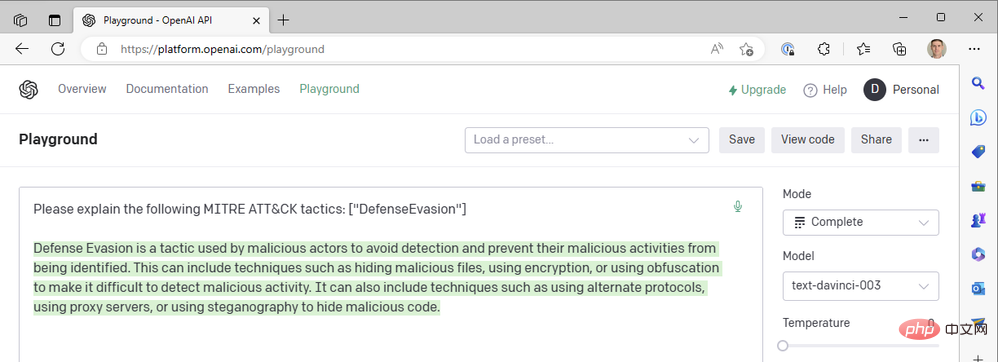
온도=0에서는 이 프롬프트를 몇 번이나 다시 생성하더라도 거의 동일한 결과를 얻습니다. 이는 GPT3에 기술 용어를 정의하도록 요청할 때 잘 작동합니다. MITRE ATT&CK 전술로서 "방어 회피"가 의미하는 바에는 큰 차이가 없어야 합니다. 동일한 단어("기술적 유사")를 재사용하는 모델의 경향을 줄이기 위해 빈도 페널티를 추가하여 응답의 가독성을 향상시킬 수 있습니다. 주파수 페널티를 최대 2까지 높이겠습니다.
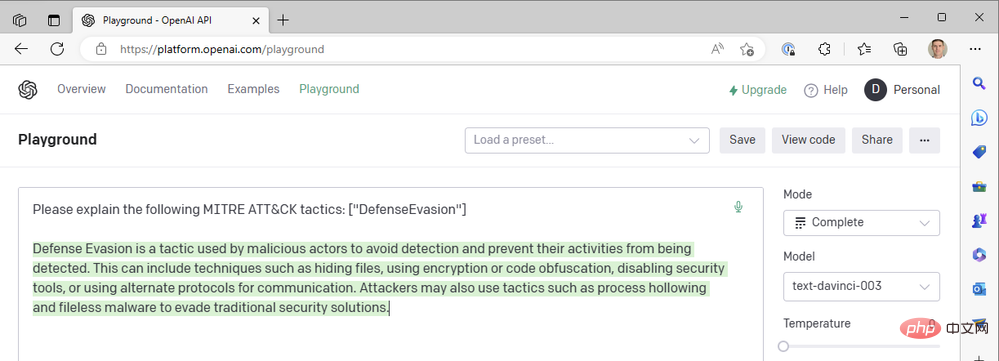
지금까지 우리는 작업을 빠르게 완료하기 위해 최신 da Vinci 모델만 사용했습니다. Curie, Babbage 또는 Ada와 같은 OpenAI의 더 빠르고 저렴한 모델 중 하나로 떨어지면 어떻게 될까요? 모델을 "text-ada-001"로 변경하고 결과를 비교해 보겠습니다.
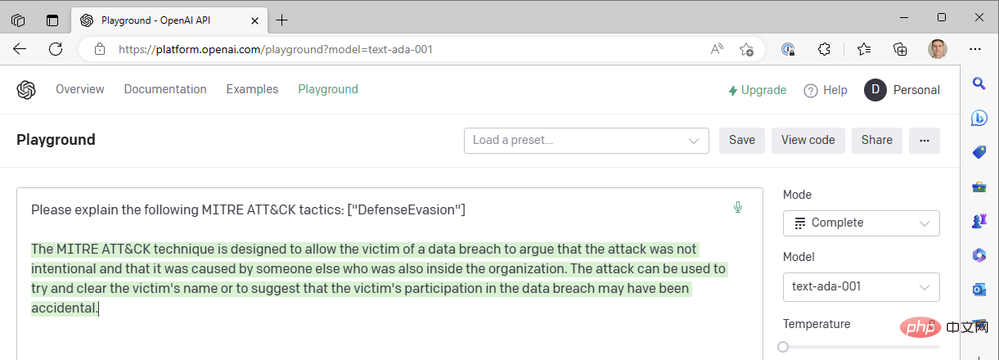
음… 그렇지는 않습니다. Babbage를 시도해 봅시다:
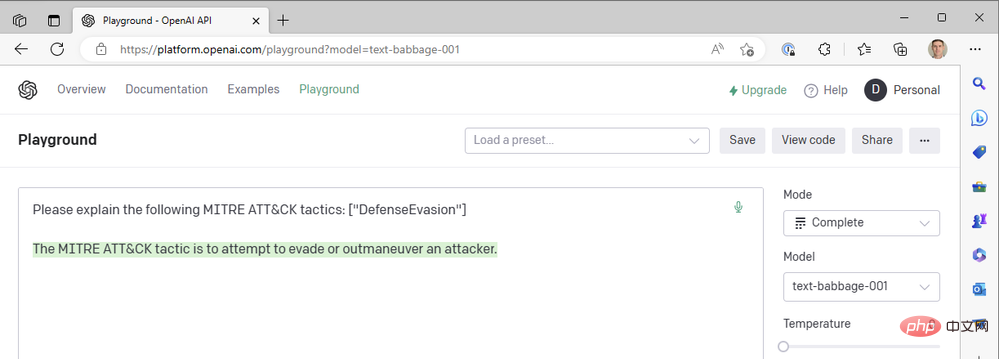
Babbage도 우리가 찾고 있는 결과를 반환하지 않는 것 같습니다. 어쩌면 퀴리가 더 나을 수도 있지 않을까?
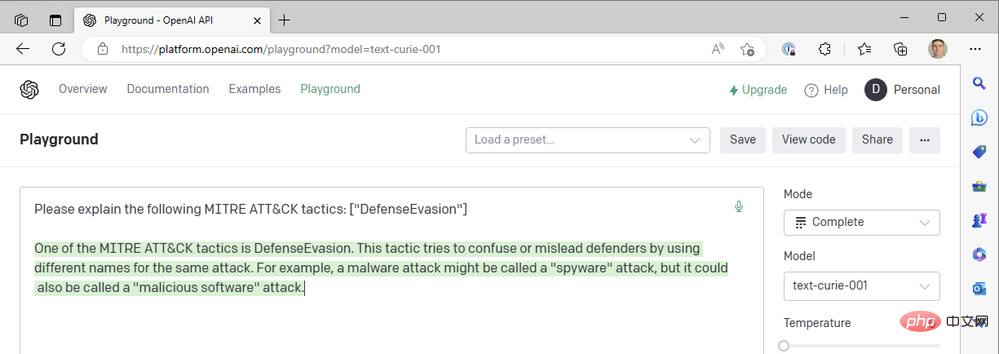
슬프게도 퀴리 역시 레오나르도 다빈치가 정한 기준을 충족하지 못했습니다. 확실히 빠르지만 보안 이벤트에 컨텍스트를 추가하는 사용 사례는 1초 미만의 응답 시간에 의존하지 않습니다. 요약의 정확성이 더 중요합니다. 우리는 다빈치 모델, 저온 및 고주파 처벌의 성공적인 조합을 계속 사용하고 있습니다.
로직 앱으로 돌아가서 플레이그라운드에서 발견한 설정을 OpenAI Action Block으로 전송해 보겠습니다.
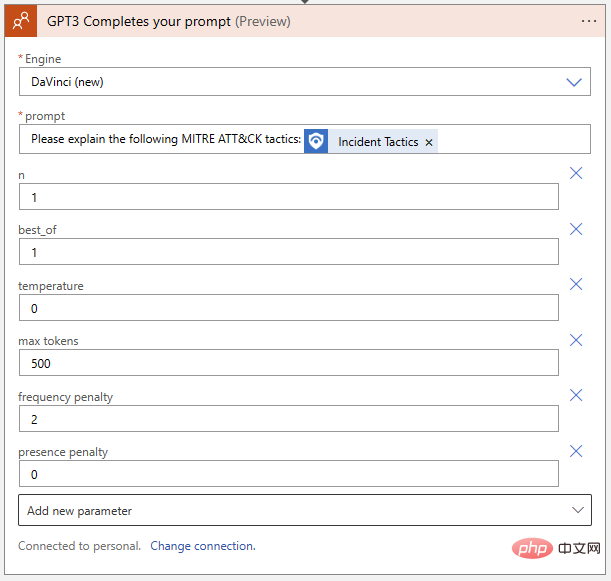
로직 앱에서는 이벤트에 대한 댓글도 작성할 수 있어야 합니다. "새 단계"를 클릭하고 Microsoft Sentinel 커넥터에서 "이벤트에 설명 추가"를 선택합니다.
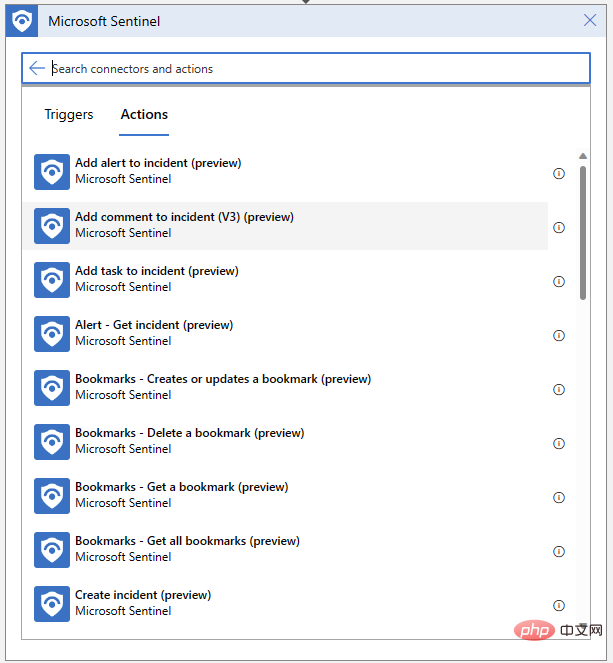
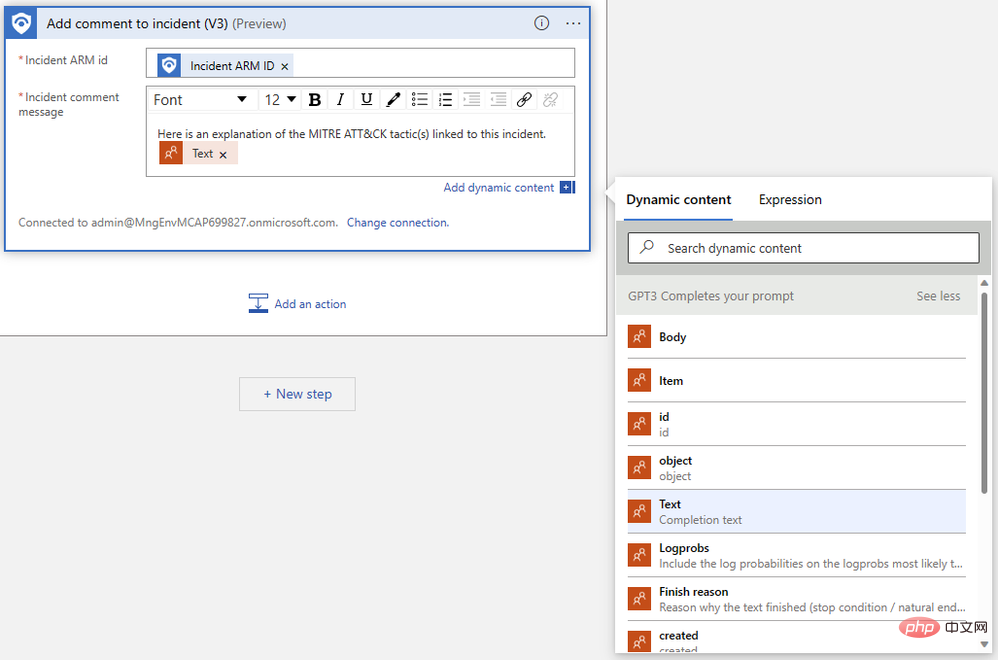
이벤트 ARM 식별자를 지정하고 설명 메시지를 작성하기만 하면 됩니다. 먼저 동적 콘텐츠 팝업 메뉴에서 "이벤트 ARM ID"를 검색합니다.
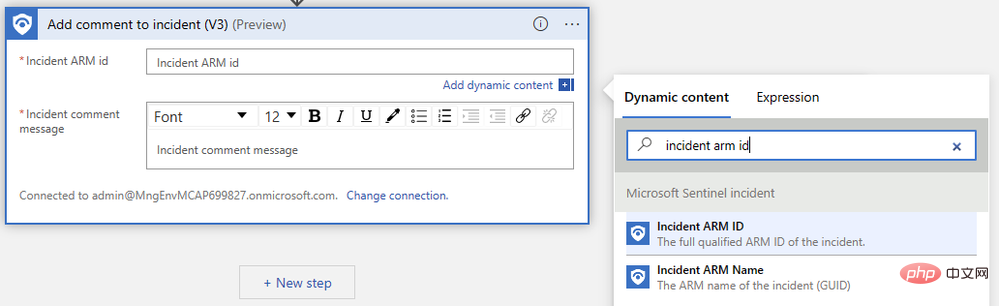
다음으로 이전 단계에서 출력한 "텍스트"를 찾습니다. 출력을 보려면 자세히 보기를 클릭해야 할 수도 있습니다. 논리 앱 디자이너는 동일한 프롬프트에 대해 여러 완성이 생성되는 경우를 처리하기 위해 "각각" 논리 블록에 주석 작업을 자동으로 래핑합니다.
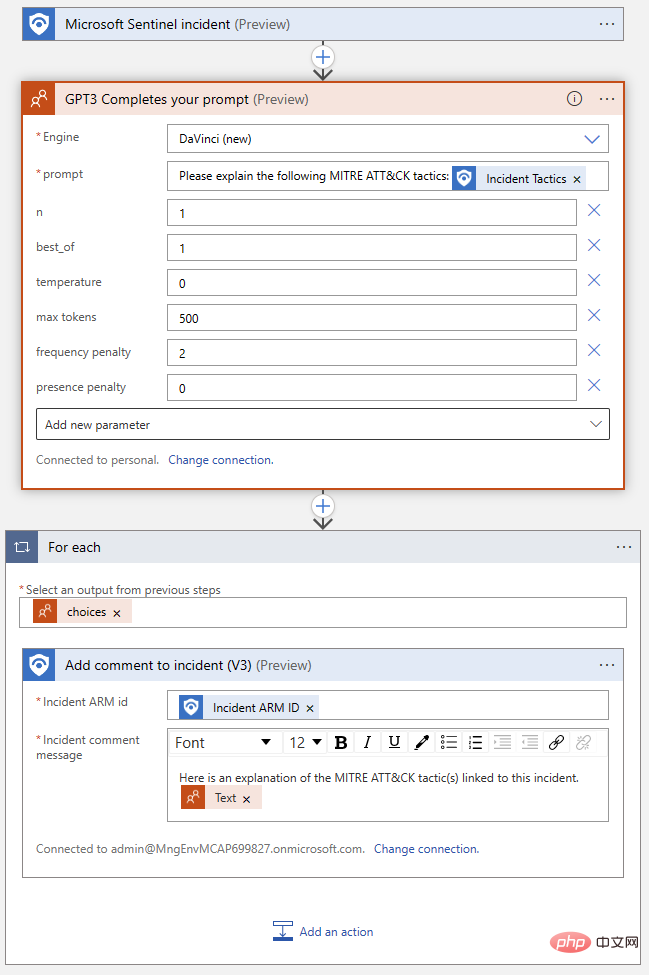
완성된 논리 앱은 다음과 같아야 합니다.
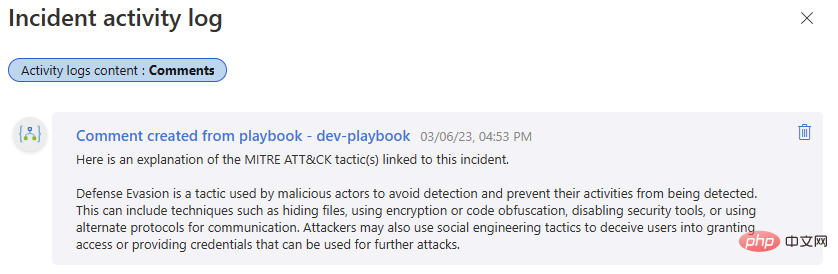
다시 테스트해 보겠습니다! 해당 Microsoft Sentinel 이벤트로 돌아가서 플레이북을 실행하세요. 논리 앱 실행 기록에 또 다른 성공적인 완료가 표시되고 이벤트 활동 로그에 새 설명이 표시됩니다.
지금까지 저희와 연락해 오셨다면 이제 OpenAI GPT3를 Microsoft Sentinel과 통합하여 보안 조사에 가치를 더하실 수 있습니다. OpenAI 모델을 Sentinel과 통합하여 보안 플랫폼을 최대한 활용하는 데 도움이 되는 워크플로를 잠금 해제하는 더 많은 방법에 대해 논의할 다음 기사를 계속 지켜봐 주시기 바랍니다!
위 내용은 OpenAI 및 Microsoft Sentinel 소개의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!