




WeChat의 인기로 인해 점점 더 많은 사람들이 WeChat을 사용하기 시작했습니다. WeChat은 단순한 소셜 소프트웨어에서 점차 생활 방식으로 변모했습니다. 사람들은 일상적인 의사소통을 위해 WeChat을 필요로 하고, 업무상 의사소통을 위해서도 WeChat을 필요로 합니다. WeChat의 모든 친구는 사람들이 사회에서 수행하는 다양한 역할을 나타냅니다.

오늘 글에서는 Python을 기반으로 WeChat 친구에 대한 데이터 분석을 수행합니다. 여기서 선택한 차원은 주로 성별, 아바타, 서명 및 위치입니다. 그 중 결과는 주로 차트와 워드 클라우드의 형태로 표시됩니다. , 텍스트 정보의 경우 단어 빈도 분석과 감정 분석의 두 가지 방법을 사용합니다. 속담처럼: 노동자가 자신의 일을 잘하고 싶다면 먼저 도구를 갈고 닦아야 합니다. 이 기사를 공식적으로 시작하기 전에 이 기사에 사용된 타사 모듈을 간략하게 소개하겠습니다.
itchat: WeChat 웹 인터페이스는 이 기사에서 WeChat 친구 정보를 얻기 위해 사용되는 Python 버전을 캡슐화합니다.
jieba: 이 문서에서 텍스트 정보를 분할하는 데 사용되는 말더듬 단어 분할의 Python 버전입니다.
matplotlib: 이 기사에서 세로 막대형 차트와 원형 차트를 그리는 데 사용되는 Python의 차트 그리기 모듈
snownlp: 이 기사에서 텍스트 정보에 대한 감정적 판단을 내리는 데 사용되는 Python의 중국어 단어 분할 모듈.
PIL: 이 문서에서 이미지를 처리하는 데 사용되는 Python의 이미지 처리 모듈입니다.
numpy: 이 기사의 wordcloud 모듈과 함께 사용되는 Python의 수치 계산 모듈입니다.
wordcloud: 이 글에서는 Python의 단어 구름 모듈을 사용하여 단어 구름 그림을 그립니다.
TencentYoutuyun: 이 글에서는 Tencent Youtuyun에서 제공하는 Python 버전 SDK를 사용하여 얼굴을 인식하고 이미지 태그 정보를 추출합니다.
위 모듈은 pip를 통해 설치할 수 있습니다. 각 모듈의 사용에 대한 자세한 지침은 해당 설명서를 참조하세요.
1. 데이터 분석
WeChat 친구 데이터를 분석하기 위한 전제 조건은 itchat 모듈을 사용하면 다음 두 줄의 코드를 통해 이를 달성할 수 있다는 것입니다. WeChat과 마찬가지로 휴대폰으로 QR 코드를 스캔하여 로그인할 수 있습니다. 여기에 반환된 친구 개체는 컬렉션이고 첫 번째 요소는 현재 사용자입니다. 따라서 다음 데이터 분석 과정에서는 항상 friends[1:]을 원본 입력 데이터로 사용하며, 컬렉션의 각 요소는 사전 구조로 되어 있음을 예로 들면 Sex, City, Province가 있음을 알 수 있습니다. , HeadImgUrl 및 Signature는 다음 네 가지 필드에서 시작됩니다.
 2. 친구의 성별
2. 친구의 성별
친구의 성별을 분석하려면 먼저 모든 친구의 성별 정보를 얻어야 합니다. 여기서는 각 친구 정보의 Sex 필드를 추출한 다음 Male, Female 및 Unkonw의 수를 각각 계산하여 이 세 가지 값을 목록으로 모은 다음 matplotlib 모듈을 사용하여 파이를 그립니다. 차트는 다음과 같이 구현됩니다.
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
이 코드에 대한 간략한 설명은 다음과 같습니다. WeChat의 성별 필드에는 Unkonw, Male 및 Female의 세 가지 값이 있으며 해당 값은 다음과 같습니다. 각각 0, 1, 2입니다. 이 세 가지 다른 값은 Collection 모듈의 Counter()를 통해 계산되며 해당 items() 메서드는 튜플 컬렉션을 반환합니다.
이 튜플의 첫 번째 차원 요소는 키, 즉 0, 1, 2를 나타냅니다. 이 튜플의 두 번째 차원 요소는 숫자를 나타내고 이 튜플의 집합은 정렬됩니다. 즉, 키는 다음과 같습니다. 0, 1, 2. 2이므로 이 세 가지 다른 값의 수는 map() 메서드를 통해 얻을 수 있습니다. 이 세 가지 값의 백분율은 다음과 같이 계산됩니다. matplotlib. 다음 그림은 matplotlib에서 그린 친구의 성별 분포입니다.
 3. 친구 아바타
3. 친구 아바타
친구 아바타를 두 가지 측면에서 분석합니다. 첫째, 이 친구 아바타 중 사람 얼굴 아바타를 사용하는 친구의 비율은 두 번째입니다. 이 친구 아바타에서 어떤 가치 있는 키워드를 추출할 수 있는지 알아보세요.
여기서 HeadImgUrl 필드를 기반으로 로컬로 아바타를 다운로드한 다음 Tencent Youtu에서 제공하는 얼굴 인식 관련 API 인터페이스를 사용하여 아바타 이미지에 얼굴이 있는지 감지하고 이미지에 태그를 추출해야 합니다. 그 중 전자는 분류와 요약이고, 후자는 텍스트 분석이고, 워드클라우드를 이용해 결과를 제시하는 방식이다. 키 코드는 다음과 같습니다:
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
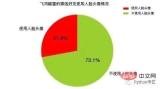
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
4. 好友签名
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
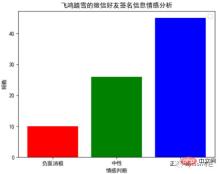
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
5. 好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
6. 总结
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
위 내용은 나는 Python을 사용하여 WeChat 친구를 크롤링했는데 그들은 다음과 같습니다...의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 파이썬 : 자동화, 스크립팅 및 작업 관리Apr 16, 2025 am 12:14 AM
파이썬 : 자동화, 스크립팅 및 작업 관리Apr 16, 2025 am 12:14 AM파이썬은 자동화, 스크립팅 및 작업 관리가 탁월합니다. 1) 자동화 : 파일 백업은 OS 및 Shutil과 같은 표준 라이브러리를 통해 실현됩니다. 2) 스크립트 쓰기 : PSUTIL 라이브러리를 사용하여 시스템 리소스를 모니터링합니다. 3) 작업 관리 : 일정 라이브러리를 사용하여 작업을 예약하십시오. Python의 사용 편의성과 풍부한 라이브러리 지원으로 인해 이러한 영역에서 선호하는 도구가됩니다.
 파이썬과 시간 : 공부 시간을 최대한 활용Apr 14, 2025 am 12:02 AM
파이썬과 시간 : 공부 시간을 최대한 활용Apr 14, 2025 am 12:02 AM제한된 시간에 Python 학습 효율을 극대화하려면 Python의 DateTime, Time 및 Schedule 모듈을 사용할 수 있습니다. 1. DateTime 모듈은 학습 시간을 기록하고 계획하는 데 사용됩니다. 2. 시간 모듈은 학습과 휴식 시간을 설정하는 데 도움이됩니다. 3. 일정 모듈은 주간 학습 작업을 자동으로 배열합니다.
 파이썬 : 게임, Guis 등Apr 13, 2025 am 12:14 AM
파이썬 : 게임, Guis 등Apr 13, 2025 am 12:14 AMPython은 게임 및 GUI 개발에서 탁월합니다. 1) 게임 개발은 Pygame을 사용하여 드로잉, 오디오 및 기타 기능을 제공하며 2D 게임을 만드는 데 적합합니다. 2) GUI 개발은 Tkinter 또는 PYQT를 선택할 수 있습니다. Tkinter는 간단하고 사용하기 쉽고 PYQT는 풍부한 기능을 가지고 있으며 전문 개발에 적합합니다.
 Python vs. C : 응용 및 사용 사례가 비교되었습니다Apr 12, 2025 am 12:01 AM
Python vs. C : 응용 및 사용 사례가 비교되었습니다Apr 12, 2025 am 12:01 AMPython은 데이터 과학, 웹 개발 및 자동화 작업에 적합한 반면 C는 시스템 프로그래밍, 게임 개발 및 임베디드 시스템에 적합합니다. Python은 단순성과 강력한 생태계로 유명하며 C는 고성능 및 기본 제어 기능으로 유명합니다.
 2 시간의 파이썬 계획 : 현실적인 접근Apr 11, 2025 am 12:04 AM
2 시간의 파이썬 계획 : 현실적인 접근Apr 11, 2025 am 12:04 AM2 시간 이내에 Python의 기본 프로그래밍 개념과 기술을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우기, 2. 마스터 제어 흐름 (조건부 명세서 및 루프), 3. 기능의 정의 및 사용을 이해하십시오. 4. 간단한 예제 및 코드 스 니펫을 통해 Python 프로그래밍을 신속하게 시작하십시오.
 파이썬 : 기본 응용 프로그램 탐색Apr 10, 2025 am 09:41 AM
파이썬 : 기본 응용 프로그램 탐색Apr 10, 2025 am 09:41 AMPython은 웹 개발, 데이터 과학, 기계 학습, 자동화 및 스크립팅 분야에서 널리 사용됩니다. 1) 웹 개발에서 Django 및 Flask 프레임 워크는 개발 프로세스를 단순화합니다. 2) 데이터 과학 및 기계 학습 분야에서 Numpy, Pandas, Scikit-Learn 및 Tensorflow 라이브러리는 강력한 지원을 제공합니다. 3) 자동화 및 스크립팅 측면에서 Python은 자동화 된 테스트 및 시스템 관리와 같은 작업에 적합합니다.
 2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?Apr 09, 2025 pm 04:33 PM
2 시간 안에 얼마나 많은 파이썬을 배울 수 있습니까?Apr 09, 2025 pm 04:33 PM2 시간 이내에 파이썬의 기본 사항을 배울 수 있습니다. 1. 변수 및 데이터 유형을 배우십시오. 이를 통해 간단한 파이썬 프로그램 작성을 시작하는 데 도움이됩니다.
 10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?Apr 02, 2025 am 07:18 AM
10 시간 이내에 프로젝트 및 문제 중심 방법에서 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법?Apr 02, 2025 am 07:18 AM10 시간 이내에 컴퓨터 초보자 프로그래밍 기본 사항을 가르치는 방법은 무엇입니까? 컴퓨터 초보자에게 프로그래밍 지식을 가르치는 데 10 시간 밖에 걸리지 않는다면 무엇을 가르치기로 선택 하시겠습니까?


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

Dreamweaver Mac版
시각적 웹 개발 도구

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

SublimeText3 영어 버전
권장 사항: Win 버전, 코드 프롬프트 지원!

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

