
Python을 사용하여 14억 개의 데이터 분석

- PHPz앞으로
- 2023-04-12 22:19:251828검색

Google Ngram 뷰어는 책에서 스캔한 Google의 방대한 데이터를 사용하여 시간에 따른 단어 사용 변화를 표시하는 재미있고 유용한 도구입니다. 예를 들어 Python이라는 단어(대소문자 구분):
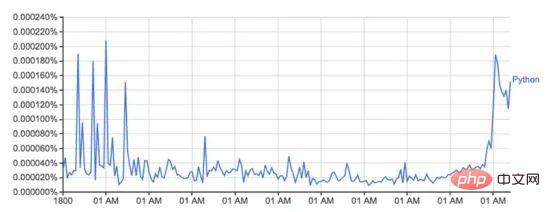
books.google.com/ngrams에서 가져온 이 그래프는 시간 경과에 따른 'Python'이라는 단어의 사용을 보여줍니다.
책이 인쇄된 각 연도 동안 Google 도서에서 특정 단어나 구문의 사용을 기록하는 Google의 n-gram 데이터세트를 기반으로 합니다. 이것이 완전하지는 않지만(지금까지 출판된 모든 책을 포함하지는 않습니다!) 데이터 세트에는 16세기부터 2008년까지의 기간에 걸쳐 수백만 권의 책이 있습니다. 데이터 세트는 여기에서 무료로 다운로드할 수 있습니다.
저는 Python과 새로운 데이터 로딩 라이브러리 PyTubes를 사용하여 위의 플롯을 재생성하는 것이 얼마나 쉬운지 확인하기로 결정했습니다.
Challenge
1그램 데이터 세트는 하드 디스크의 27GB 데이터로 확장할 수 있는데, 이는 파이썬으로 읽을 때 엄청난 양의 데이터입니다. Python은 한 번에 기가바이트의 데이터를 쉽게 처리할 수 있지만 데이터가 손상되어 처리되면 속도가 느려지고 메모리 효율성이 떨어집니다.
총 14억 개의 데이터 조각(1,430,727,243)이 38개의 소스 파일에 분산되어 있으며 총 2,400만(24,359,460)개의 단어(및 품사 태그, 아래 참조)가 포함되어 있으며 1505년부터 2008년까지 계산됩니다. .
10억 행의 데이터를 처리하면 작업 속도가 빠르게 느려집니다. 그리고 기본 Python은 데이터의 이러한 측면을 처리하도록 최적화되어 있지 않습니다. 다행히도 numpy는 많은 양의 데이터를 처리하는 데 정말 능숙합니다. 몇 가지 간단한 트릭을 사용하면 numpy를 사용하여 이 분석을 실현 가능하게 만들 수 있습니다.
Python/numpy에서 문자열을 처리하는 것은 복잡합니다. Python에서 문자열의 메모리 오버헤드는 상당하며, numpy는 알려진 고정 길이의 문자열만 처리할 수 있습니다. 이러한 상황으로 인해 대부분의 단어의 길이가 다르기 때문에 이는 이상적이지 않습니다.
데이터 로드
아래의 모든 코드/예제는 8GB RAM을 갖춘 2016 Macbook Pro에서 실행됩니다. 하드웨어 또는 클라우드 인스턴스의 RAM 구성이 더 좋으면 성능이 더 좋아집니다.
1그램 데이터는 다음과 같이 탭으로 구분된 형식으로 파일에 저장됩니다.

각 데이터 조각에는 다음 필드가 포함됩니다.
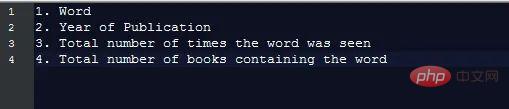
차트를 생성하려면 필수, 우리만 이 정보를 알아야 합니다. 즉:

이 정보를 추출하면 길이가 다른 문자열 데이터를 처리하는 데 드는 추가 비용이 무시되지만 여전히 값을 비교해야 합니다. 어떤 데이터 행이 우리가 관심 있는 필드인지 구별하기 위해 다른 문자열을 사용합니다. pytubes가 할 수 있는 일은 다음과 같습니다:
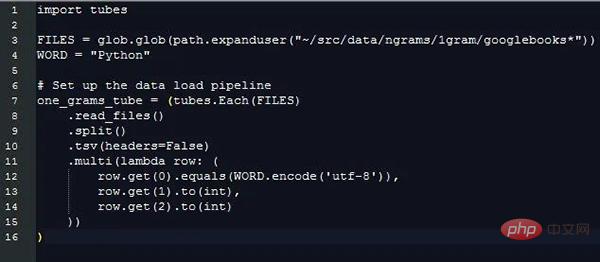
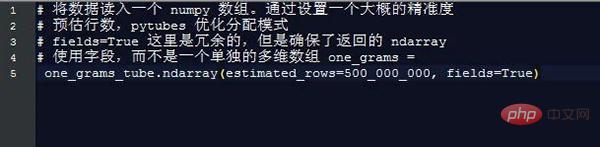
거의 170초(3분) 후 one_grams는 거의 14억 행의 데이터를 포함하는 numpy 배열입니다(그림을 위해 헤더가 추가됨):
╒ ===========╤========╤=========╕
│ Is_Word │연도 │수 │
╞== │
├─ ──────── ──┼────────┼─────────┤
│ 0 │ 1804 │ 1 │
├──────── ───┼──── ────┼────────┤
│ 0 │ 1805 │ 1 │
├───────────┼──── ──────┼── ───────┤
│ 0 │ 1811 │ 1 │
├───────────┼────────┼ ───────── ┤
│ 0 │ 1820년 │ ... │
╘==========╧=======╧==== = ====╛
여기서부터는 numpy 방법을 사용하여 무언가를 계산하기만 하면 됩니다.
각 연도의 총 단어 사용량
Google은 각 단어의 발생 비율(해당 연도에 특정 단어가 나타나는 횟수/전체)을 표시합니다. 해당 연도의 모든 단어 발생 횟수) 이는 원래 단어를 세는 것보다 더 유용합니다. 이 백분율을 계산하려면 총 단어 수가 얼마인지 알아야 합니다.
다행히도 numpy를 사용하면 이 작업이 매우 쉽습니다.
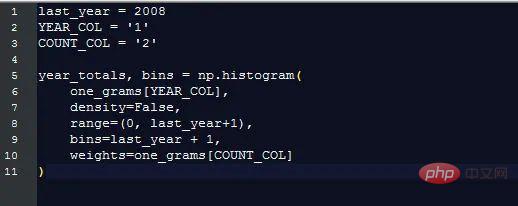
Google이 매년 수집한 단어 수를 표시하려면 이 그래프를 표시하세요.
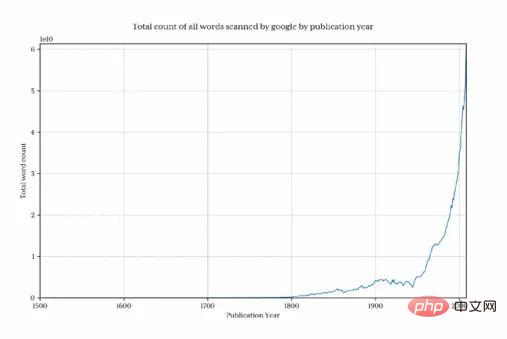
1800년 이전에는 전체 데이터 양이 매우 빠르게 삭제되어 왜곡된다는 것이 분명합니다. 최종 결과와 관심 있는 패턴을 숨기는 것입니다. 이 문제를 방지하기 위해 1800년 이후의 데이터만 가져옵니다.
이렇게 하면 13억 행의 데이터가 반환됩니다(1800년 이전 데이터의 3.7%만 해당).
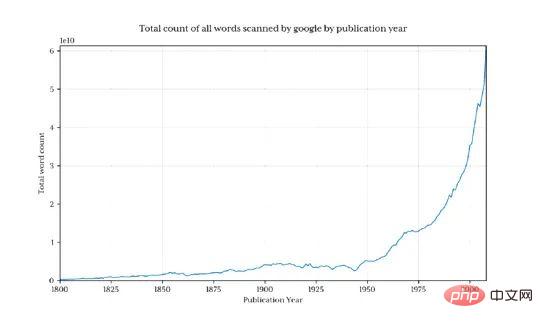
매년 Python의 비율
백분율 구하기 매년 Python을 사용하는 것은 이제 특히 간단합니다.
간단한 방법을 사용하여 2008년 요소 길이는 각 연도의 인덱스가 해당 연도의 숫자와 동일하다는 것을 의미합니다. 1995.
이것은 numpy를 사용하여 작업할 가치가 없습니다.

word_counts를 플로팅한 결과:

모양이 Google 버전과 비슷해 보입니다.
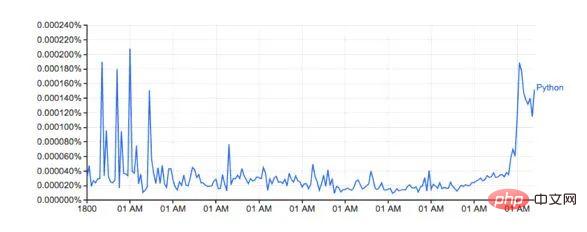
실제 백분율이 일치하지 않는 것 같습니다. 다운로드한 데이터 세트에 다른 단어(예: Python_VERB)가 포함되어 있기 때문입니다. 이 데이터 세트는 Google 페이지에 잘 설명되어 있지 않으며 몇 가지 질문을 제기합니다.
Python을 동사로 어떻게 사용합니까?
'Python'의 총 계산량에 'Python_VERB'도 포함되나요? 잠깐
다행스럽게도 제가 사용한 방법은 Google과 매우 유사해 보이는 아이콘을 생성하고 관련 트렌드에 영향을 미치지 않는다는 것을 모두 알고 있으므로 이번 탐색에서는 이를 수정하려고 하지 않을 것입니다.
성능
Google은 약 1초 만에 이미지를 생성하는데, 이는 이 스크립트의 8분에 비해 합리적인 수준입니다. Google의 단어 개수 백엔드는 준비된 데이터 세트의 명시적인 보기에서 작동합니다.
예를 들어 전년도 전체 단어 사용량을 미리 계산해 별도의 조회 테이블에 저장하면 시간이 크게 절약됩니다. 마찬가지로 별도의 데이터베이스/파일에 단어 사용법을 유지한 다음 첫 번째 열을 인덱싱하면 처리 시간이 거의 모두 제거됩니다.
이 탐색은 표준 상용 하드웨어 및 Python과 함께 numpy 및 신생 pytube를 사용하여 합리적인 시간에 10억 행 데이터 세트에서 임의의 통계를 로드, 처리 및 추출하는 것이 가능하다는 것을 실제로 보여줍니다.
언어 전쟁
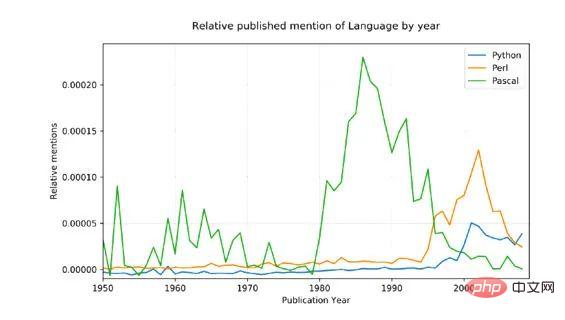
이를 입증하려면 좀 더 복잡한 예를 들어 관련해서 언급된 세 가지 프로그래밍 언어인 Python, Pascal, Perl을 비교하기로 했습니다.
소스 데이터에 노이즈가 있습니다. 하지만 예를 들어 python에는 기술적인 의미가 없습니다! ), 이와 관련하여 조정하기 위해 다음 두 가지 작업을 수행했습니다.
이름의 첫 글자만 대문자로 사용할 수 있습니다(Python은 일치하지 않습니다.) python)
각 언어에 대한 총 언급 수는 1800년부터 1960년까지의 평균 백분율로 변환되었으며, 이는 파스칼이 1970년에 처음 언급되었다는 점을 감안하면 합리적인 기준입니다.
결과:
Google과 비교(기준 조정 없음):
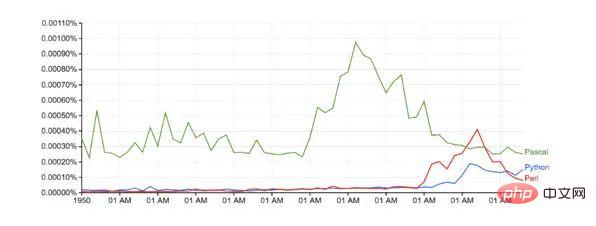
실행 시간: 10분 남짓
향후 PyTubes 개선
이 단계에서 pytubes는 64비트인 단일 정수 개념만 가지고 있습니다. 이는 pytubes에 의해 생성된 numpy 배열이 모든 정수에 대해 i8 dtype을 사용한다는 것을 의미합니다. ngram 데이터와 같은 일부 위치에서는 8비트 정수가 약간 과도하고 메모리를 낭비합니다(총 ndarray는 38Gb이며 dtypes는 이를 60%까지 쉽게 줄일 수 있습니다). 레벨 1, 2 및 4비트 정수 지원을 추가할 계획입니다( github.com/stestagg/py… )
추가 필터링 논리 - Tube.skip_unless()는 행을 필터링하는 비교적 간단한 방법이지만 결합 기능이 부족합니다. 조건(AND/OR/NOT). 이를 통해 일부 사용 사례에서는 로드된 데이터의 크기를 더 빠르게 줄일 수 있습니다.
더 나은 문자열 일치 - startwith, endwith, contain 및 is_one_of와 같은 간단한 테스트를 쉽게 추가하여 문자열 데이터 로드의 효율성을 크게 향상시킬 수 있습니다.
위 내용은 Python을 사용하여 14억 개의 데이터 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!