
간단하고 사용하기 쉬운 Python의 병렬 가속 기술

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-12 14:25:151821검색
1. 소개

우리가 일상적으로 Python을 사용하여 다양한 데이터 계산 및 처리 작업을 수행할 때, 확실한 계산 가속화 효과를 얻으려면 가장 간단하고 명확한 방법은 작업을 실행하는 방법을 찾는 것입니다. 기본적으로 단일 프로세스에서 다중 프로세스 또는 다중 스레드 실행을 사용하도록 확장되었습니다.
데이터 분석에 종사하는 사람들에게는 프로그램 작성에 너무 많은 시간을 소비하지 않도록 가장 간단한 방법으로 동등한 가속 작업을 달성하는 것이 특히 중요합니다. 오늘 기사에서는 Fei씨가 매우 간단하고 사용하기 쉬운 라이브러리인 joblib에서 관련 기능을 사용하여 병렬 컴퓨팅 가속 효과를 빠르게 얻는 방법을 가르쳐 드리겠습니다.
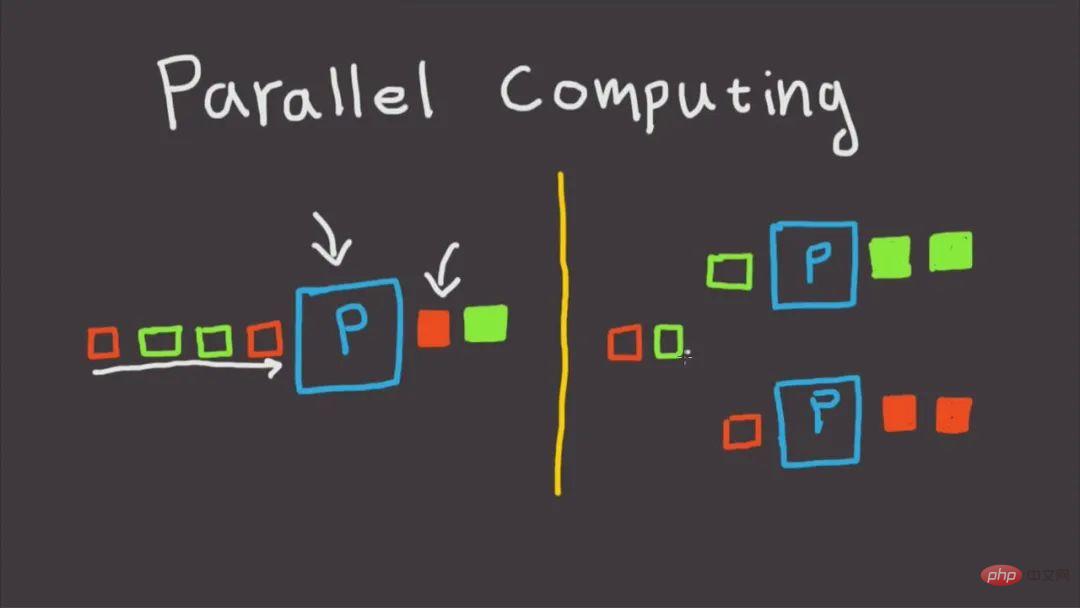
2. 병렬 컴퓨팅을 위해 joblib 사용
널리 사용되는 타사 Python 라이브러리(예: scikit-learn 프로젝트 프레임워크는 많은 기계 학습 알고리즘의 병렬 가속화를 위해 joblib를 광범위하게 사용함)로 pip를 사용할 수 있습니다. 설치가 완료되면 joblib에서 병렬 컴퓨팅의 일반적인 방법을 알아보겠습니다.
2.1 병렬 가속을 위해 병렬 및 지연 사용
joblib에서 병렬 컴퓨팅을 구현하려면 병렬 및 지연만 사용하면 됩니다. 지연 이 방법은 사용하기 매우 간단하고 편리합니다. 작은 예를 통해 직접 보여드리겠습니다.
병렬 컴퓨팅을 구현하는 joblib의 아이디어는 루프를 통해 생성된 일련의 직렬 컴퓨팅 하위 작업을 다중 컴퓨팅으로 결합하는 것입니다. 사용자 정의 컴퓨팅 작업을 위해 해야 할 일은 이를 함수 형태로 캡슐화하는 것뿐입니다. 예:
import time def task_demo1(): time.sleep(1) return time.time()
그런 다음 Parallel()에 대해 다음 형식을 따르고 하위 작업을 생성하는 목록 파생 프로세스를 통해 Loop를 연결합니다. 여기서는 Delayed()를 사용하여 사용자 정의 작업 함수를 래핑한 다음, Connected()를 사용하여 작업 함수에 필요한 매개변수를 전달합니다. 동시에 병렬 작업을 실행하는 작업자 수를 설정하는 데 사용되므로 이 예에서는 진행률 표시줄이 4개 그룹으로 증가하는 것을 볼 수 있으며, 최종 시간 오버헤드도 병렬 가속 효과를 달성하는 것을 볼 수 있습니다. :
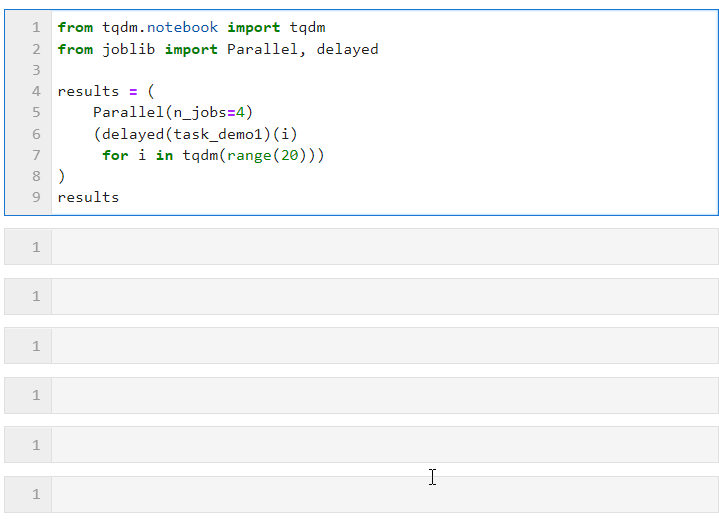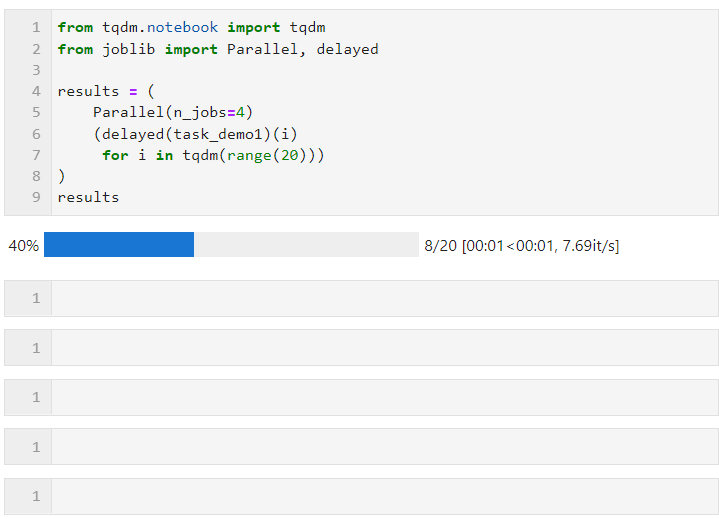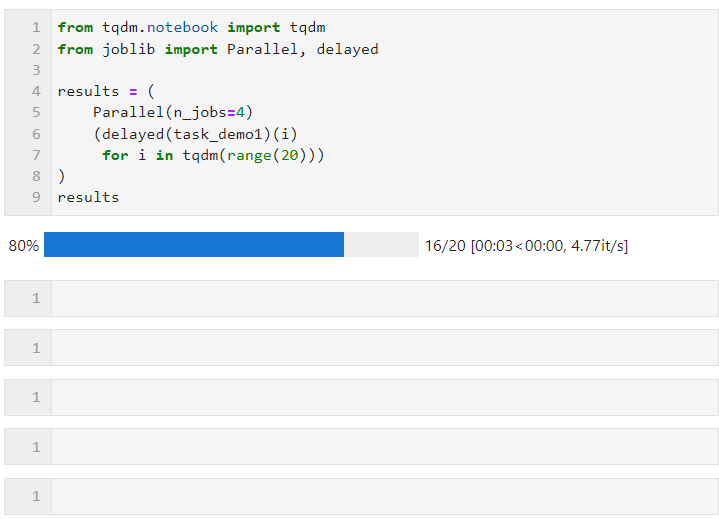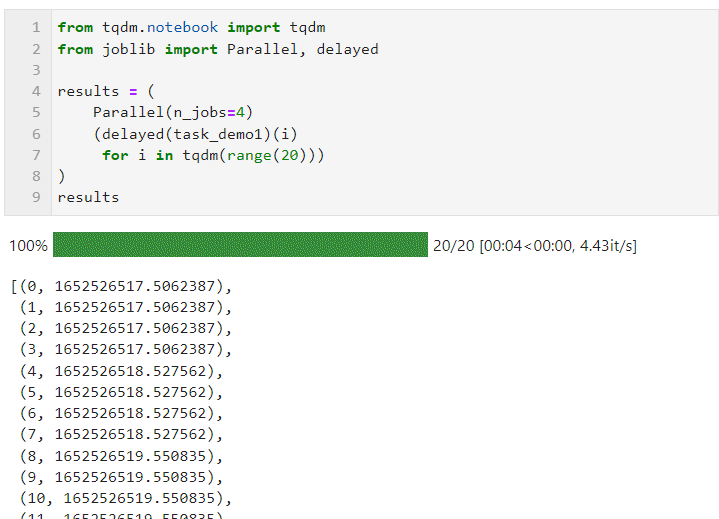
특정 상황은 병렬일 수 있습니다(컴퓨팅 작업 및 기계 CPU 코어 수에 따라). 핵심 매개변수는 다음과 같습니다.
- 백엔드: 는 병렬 모드를 설정하는 데 사용됩니다. 다중 프로세스 모드에는 'loky'(더 안정적임)와 '다중 처리'라는 두 가지 옵션이 있으며 다중 스레딩 모드에는 '스레딩' 옵션이 있습니다. 기본값은 'loky'입니다.
- n_jobs: 병렬 작업을 동시에 실행할 작업자 수를 설정하는 데 사용됩니다. 병렬 모드가 다중 프로세스인 경우 n_jobs는 머신 CPU의 논리 코어 수를 초과하는 경우 설정할 수 있습니다. 이 숫자는 모든 코어를 켜는 것과 같습니다. 모든 논리 코어를 빠르게 활성화하려면 이 값을 -1로 설정하면 됩니다. 병렬 작업이 모든 CPU 리소스를 사용하지 않으려면 더 작은 음수를 설정하면 됩니다. 적절한 유휴 코어를 유지합니다. 예를 들어 모든 코어(1개 코어)를 활성화하려면 -2로 설정합니다. 모든 코어(2개 코어)를 활성화하려면 -3으로 설정합니다.
예를 들어 다음 예에서는 논리 코어가 8개 있는 내 컴퓨터에서 두 개의 코어가 병렬 계산을 위해 예약되어 있습니다.
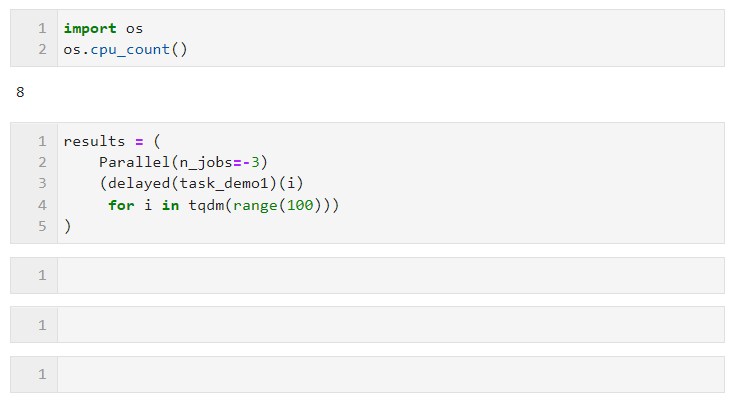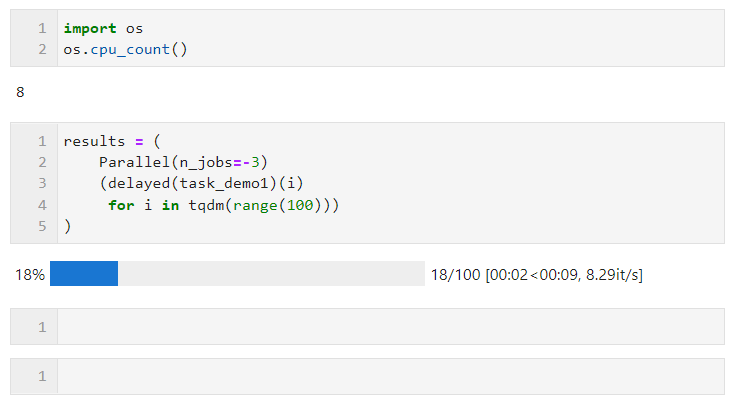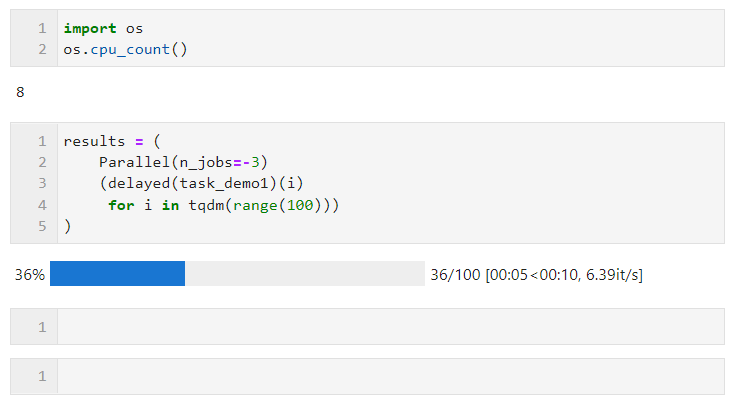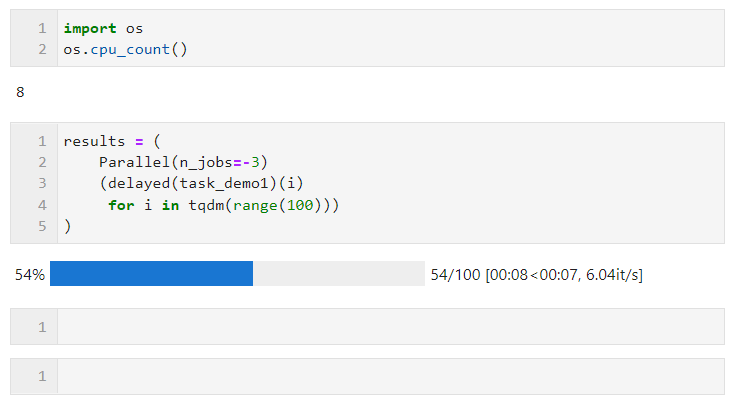
병렬 방법 선택과 관련하여 Python의 멀티스레딩에서 전역 인터프리터로 인해 잠금 제한. 작업이 계산 집약적이라면 가속을 위해 기본 다중 프로세스 방법을 사용하는 것이 좋습니다. 작업이 파일 읽기 및 쓰기, 네트워크 요청 등과 같이 IO 집약적이라면 멀티 스레딩이 더 좋습니다. n_jobs를 큰 값으로 설정할 수 있습니다. 간단한 예로 멀티 스레드 병렬 처리를 통해 5초 만에 1,000개의 요청을 완료한 것을 볼 수 있습니다. 이는 100개의 요청을 처리하는 단일 스레드의 17초보다 훨씬 빠른 것입니다. 참고용으로 배우고 시도할 때 다른 사람의 웹 사이트를 너무 자주 방문하지 마십시오.):
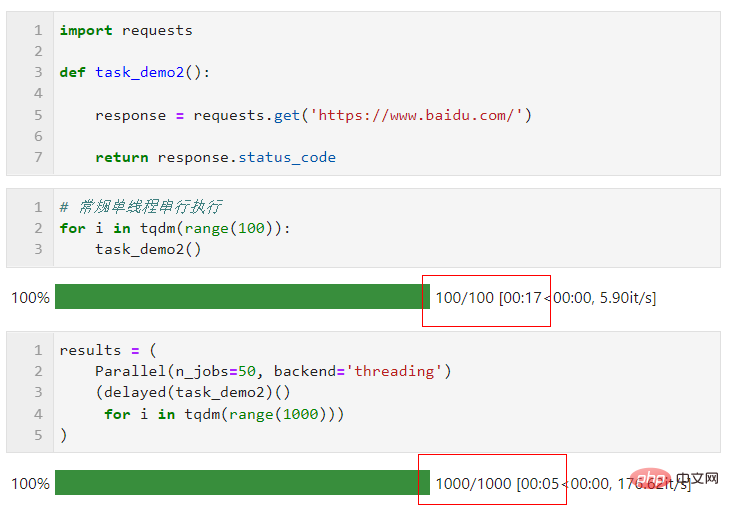
joblib를 잘 활용하면 실제 업무에 따라 일상 업무의 속도를 높일 수 있습니다.
위 내용은 간단하고 사용하기 쉬운 Python의 병렬 가속 기술의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!