
10가지 Python 팁은 데이터 분석 요구 사항의 90%를 다룹니다!

- 王林앞으로
- 2023-04-12 08:04:021091검색
데이터 분석가의 일상 업무에는 데이터 전처리, 데이터 분석, 기계 학습 모델 생성, 모델 배포 등 다양한 작업이 포함됩니다.
이 글에서는 데이터 분석 문제의 90%를 다룰 수 있는 10가지 Python 작업을 공유하겠습니다. 좋아요, 즐겨찾기 및 관심을 얻으세요.
1. 데이터 세트 읽기
데이터 읽기는 데이터 분석의 필수적인 부분입니다. 다양한 파일 형식의 데이터를 읽는 방법을 이해하는 것이 데이터 분석가의 첫 번째 단계입니다. 다음은 팬더를 사용하여 코로나19 데이터가 포함된 csv 파일을 읽는 방법의 예입니다.
import pandas as pd
# reading the countries_data file along with the location within read_csv function.
countries_df = pd.read_csv('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_data.csv')
# showing the first 5 rows of the dataframe
countries_df.head()
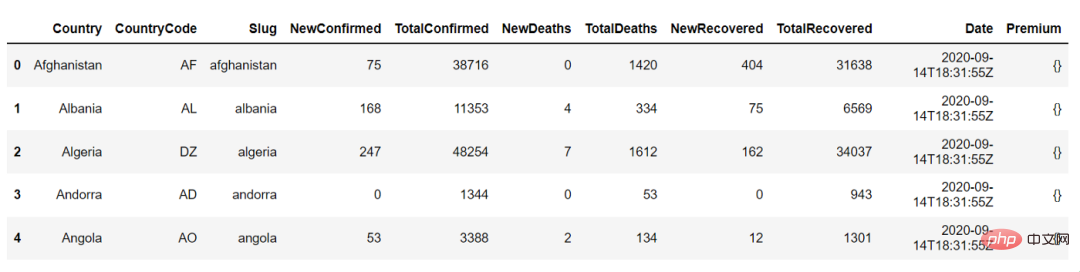
다음은 country_df.head()의 출력입니다. 이를 사용하여 데이터 프레임의 처음 5개 행을 볼 수 있습니다.
2. 요약 통계
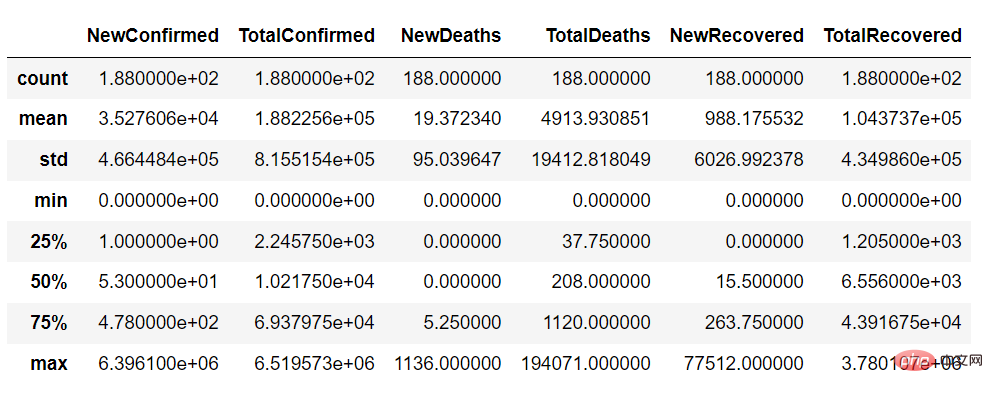
다음 단계는 데이터를 이해하는 것입니다. NewConfirmed와 같은 데이터 요약, TotalConfirmed와 같은 숫자 열의 개수, 평균, 표준편차, 분위수, 국가 코드와 같은 범주형 열의 빈도 및 최고 발생 값을 볼 수 있습니다.
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">countries_df</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">describe</span>()
describe 함수를 사용하면 데이터 세트의 연속 변수 요약은 다음과 같습니다.
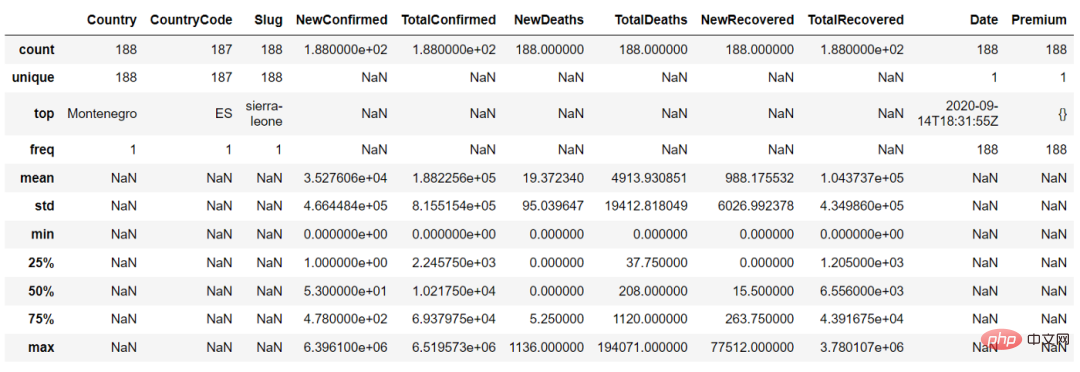
describe() 함수에서 "include = 'all'" 매개변수를 설정하여 연속 변수와 범주형 변수의 요약을 얻을 수 있습니다
countries_df.describe(include = 'all')
3. 데이터 선택 및 필터링
분석에는 실제로 모든 행과 열의 데이터 세트가 필요하지 않으며, 관심 있는 열을 선택하고 질문에 따라 일부 행을 필터링하면 됩니다.
예를 들어 다음 코드를 사용하여 Country 및 NewConfirmed 열을 선택할 수 있습니다.
countries_df[['Country','NewConfirmed']]
또한 loc를 사용하여 Country 데이터를 필터링할 수 있으며 아래와 같이 일부 값을 기반으로 열을 필터링할 수 있습니다.
countries_df.loc[countries_df['Country'] == 'United States of America']

4. 집계
개수, 합계, 평균 등의 데이터 집계는 데이터 분석에서 가장 일반적으로 수행되는 작업 중 하나입니다.
집계를 이용하면 국가별 신규확정 건수를 확인할 수 있습니다. groupby 및 agg 함수를 사용하여 집계를 수행합니다.
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})5. Join
2개의 데이터 세트를 하나의 데이터 세트로 결합하려면 Join 작업을 사용하세요.
예: 한 데이터 세트에는 여러 국가의 코로나19 사례 수가 포함될 수 있고, 다른 데이터 세트에는 여러 국가의 위도 및 경도 정보가 포함될 수 있습니다.
이제 이 두 정보를 결합해야 아래와 같이 연결 작업을 수행할 수 있습니다
countries_lat_lon = pd.read_excel('C:/Users/anmol/Desktop/Courses/Python for Data Science/Code/countries_lat_lon.xlsx')
# joining the 2 dataframe : countries_df and countries_lat_lon
# syntax : pd.merge(left_df, right_df, on = 'on_column', how = 'type_of_join')
joined_df = pd.merge(countries_df, countries_lat_lon, on = 'CountryCode', how = 'inner')
joined_df6. 내장 함수
min(), max(), 평균(), 합계() 등은 다양한 분석을 수행하는 데 매우 유용합니다.
이러한 함수를 호출하여 데이터프레임에 직접 적용할 수 있으며, 이 함수는 아래와 같이 열이나 집계 함수에서 독립적으로 사용할 수 있습니다.
# finding sum of NewConfirmed cases of all the countries
countries_df['NewConfirmed'].sum()
# Output : 6,631,899
# finding the sum of NewConfirmed cases across different countries
countries_df.groupby(['Country']).agg({'NewConfirmed':'sum'})
# Output
#NewConfirmed
#Country
#Afghanistan75
#Albania 168
#Algeria 247
#Andorra0
#Angola537. 사용자 정의 함수
우리가 직접 작성한 함수입니다. 사용자 정의 함수. 필요할 때 함수를 호출하여 이러한 함수의 코드를 실행할 수 있습니다. 예를 들어, 다음과 같이 2개의 숫자를 추가하는 함수를 만들 수 있습니다.
# User defined function is created using 'def' keyword, followed by function definition - 'addition()' # and 2 arguments num1 and num2 def addition(num1, num2): return num1+num2 # calling the function using function name and providing the arguments print(addition(1,2)) #output : 3
8, Pivot
Pivot은 열 행 내의 고유 값을 여러 개의 새 열로 변환하는 훌륭한 데이터 처리 기술입니다.
Covid-19 데이터세트에서 피벗_테이블() 함수를 사용하면 국가 이름을 별도의 새 열로 변환할 수 있습니다.
# using pivot_table to convert values within the Country column into individual columns and # filling the values corresponding to these columns with numeric variable - NewConfimed pivot_df = pd.pivot_table(countries_df,columns = 'Country', values = 'NewConfirmed') pivot_df
9. 데이터 프레임 탐색
데이터의 인덱스와 행을 탐색해야 하는 경우가 많습니다. iterrows 함수를 사용하여 데이터 프레임을 탐색할 수 있습니다:
# iterating over the index and row of a dataframe using iterrows() function
for index, row in countries_df.iterrows():
print('Index is ' + str(index))
print('Country is '+ str(row['Country']))
# Output :
# Index is 0
# Country is Afghanistan
# Index is 1
# Country is Albania
# .......10. 문자열 작업
데이터 세트의 문자열 열을 다루는 경우가 많으며, 이 경우 몇 가지 기본 문자열 작업을 이해하는 것이 중요합니다.
문자열을 대문자, 소문자로 변환하는 방법, 문자열의 길이를 찾는 방법 등.
아아아아위 내용은 10가지 Python 팁은 데이터 분석 요구 사항의 90%를 다룹니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!