
Python 자동화 오피스 애플릿: 보고서 자동화를 실현하고 자동으로 대상 사서함으로 보냅니다.

- PHPz앞으로
- 2023-04-11 23:49:142307검색

안녕하세요 여러분! 저는 타이거 형제입니다.
프로젝트 배경
데이터 분석가로서 통계 분석 차트를 만들어야 하는 경우가 많습니다. 하지만 보고서가 너무 많으면 보고서를 만드는 데 대부분의 시간이 걸리는 경우가 많습니다. 이로 인해 데이터 분석을 수행하는 데 많은 시간을 사용하지 못하게 되었습니다. 하지만 데이터 분석가로서 우리는 단순히 통계표와 차트를 만들어 보고서를 보내는 것이 아니라, 표와 차트의 데이터 뒤에 숨겨진 관련 정보를 찾아내는 데 최선을 다해야 합니다.
1. 보고서 자동화의 목적
1. 시간 절약 및 효율성 향상
자동화는 항상 시간을 절약하고 업무 효율성을 향상시킬 수 있습니다. 우리 프로그래밍을 통해 각 기능 구현 코드의 결합을 최대한 줄이고 코드를 더 잘 유지하도록 하세요. 이를 통해 우리는 많은 시간을 절약하고 더 가치 있고 의미 있는 일을 할 수 있게 될 것입니다.
2. 오류 줄이기
코딩 효과가 정확하면 영구적으로 사용할 수 있습니다. 요구 사항이 변경되면 코드의 일부만 수정하여 문제를 해결할 수 있으므로 고정된 프로그램에 맡기는 것이 더 안심입니다.
2. 보고서 자동화 범위
우선 비즈니스 요구에 따라 필요한 보고서를 작성해야 합니다. 일부 복잡한 2차 개발 지표 데이터에는 자동화된 프로그래밍이 필요하며 이는 더 복잡합니다. , 다양한 BUG가 숨겨져 있을 수 있습니다. 따라서 업무에 사용하는 보고서의 특징을 종합적으로 고려해야 할 사항은 다음과 같습니다.
1. 빈도
비즈니스에서 자주 사용하는 일부 테이블의 경우 자동화된 절차에 포함됩니다. 예를 들어 고객 정보 목록, 판매 흐름 보고서, 영업 손실 보고서, 월별 및 연간 보고서 등.
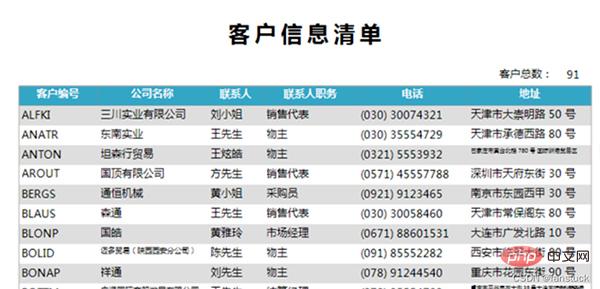
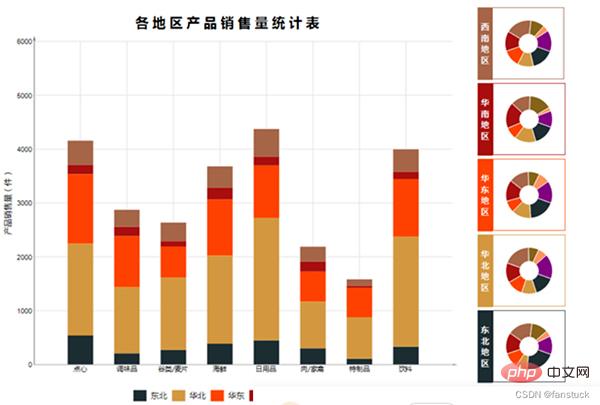
자주 사용되는 이러한 보고서를 자동화하는 것이 필요합니다. 가끔씩 사용해야 하는 보고서나 보조 개발 지표 또는 통계를 복사해야 하는 보고서의 경우 이러한 보고서를 자동화할 필요가 없습니다.
2. 개발 시간
일부 보고서의 자동화가 어렵고 일반적인 통계 분석에 필요한 시간을 초과하는 경우에는 자동화할 필요가 없습니다. 따라서 자동화 작업을 시작할 때 스크립트 개발에 소요되는 시간이 더 짧은지, 수동으로 테이블을 만드는 데 소요되는 시간이 더 짧은지 측정해야 합니다. 물론 구현 솔루션 세트를 제공하겠지만 일반적으로 사용되는 일부 보고서와 간단한 보고서에만 해당됩니다.
3. 프로세스
보고서의 각 프로세스와 단계는 회사마다 다르므로 비즈니스 시나리오에 따라 각 단계의 기능을 구현해야 합니다. 그러므로 우리가 만드는 프로세스는 비즈니스 논리와 일관되어야 하며, 우리가 만드는 프로그램도 논리적이어야 합니다.
3. 구현 단계
먼저 어떤 지표가 필요한지 알아야 합니다.
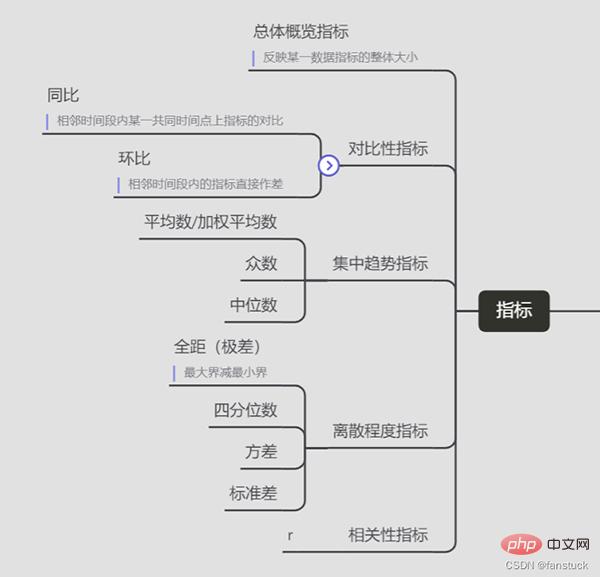
지표
- 전체 개요 지표
특정 데이터 지표의 전체 크기를 반영
- 비교 지표
- 모노그램
인접 기간 지표 간 직접적인 차이
- YoY
인접 기간 공통 시점의 지표 비교
- 중앙 경향 지표
- Median
- Mode
- 평균/가중 평균
- 분산 지수
- 표준 편차
- 분산
- 사분위수
- 전체 범위(극차)
- 최대 마이너스 최소 경계
- 상관 지수
- r
간단한 보고서를 사용하여 시뮬레이션하고 구현합니다.
1단계: 데이터 소스 파일 읽기
우선, 데이터의 출처, 즉 데이터 소스를 이해해야 합니다. 최종 데이터 처리는 분석을 위해 DataFrame으로 변환되므로 데이터 소스를 DataFrame 형식으로 변환해야 합니다.
import pandas as pd
import json
import pymysql
from sqlalchemy import create_engine
# 打开数据库连接
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
passwd='xxxx',
charset = 'utf8'
)
engine=create_engine('mysql+pymysql://root:xxxx@localhost/mysql?charset=utf8')
def read_excel(file):
df_excel=pd.read_excel(file)
return df_excel
def read_json(file):
with open(file,'r')as json_f:
df_json=pd.read_json(json_f)
return df_json
def read_sql(table):
sql_cmd ='SELECT * FROM %s'%table
df_sql=pd.read_sql(sql_cmd,engine)
return df_sql
def read_csv(file):
df_csv=pd.read_csv(file)
return df_csv위 코드는 테스트를 통해 정상적으로 사용할 수 있지만, pandas의 읽기 기능은 다양한 형식의 파일을 읽을 수 있도록 설계되었습니다. 읽기 기능 매개변수도 의미가 다르므로 테이블 형식에 따라 직접 조정해야 합니다.
다른 읽기 기능은 기사가 작성된 후에 추가될 예정입니다. read_sql이 데이터베이스에 연결해야 한다는 점을 제외하면 나머지는 비교적 간단합니다.
2단계: DataFrame 계산
사용자 정보를 예로 들어보겠습니다.
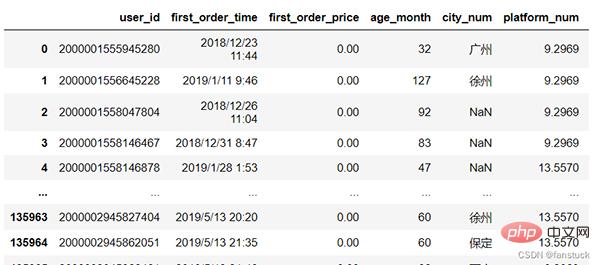
我们需要统计的指标为:
- #指标说明
- 单表图:
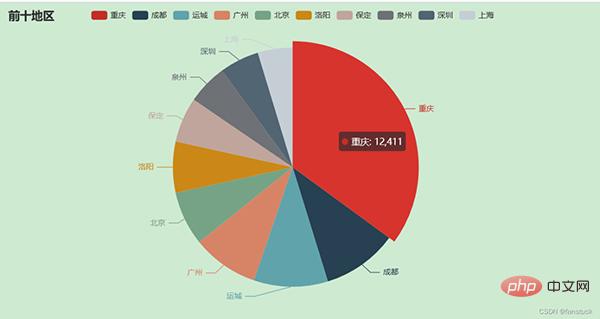
- 前十个产品受众最多的地区
#将城市空值的一行删除 df=df[df['city_num'].notna()] #删除error df=df.drop(df[df['city_num']=='error'].index) #统计df = df.city_num.value_counts()

我们仅获取前10名的城市就好了,封装为饼图:
def pie_chart(df):
#将城市空值的一行删除
df=df[df['city_num'].notna()]
#删除error
df=df.drop(df[df['city_num']=='error'].index)
#统计
df = df.city_num.value_counts()
df.head(10).plot.pie(subplots=True,figsize=(5, 6),autopct='%.2f%%',radius = 1.2,startangle = 250,legend=False)
pie_chart(read_csv('user_info.csv'))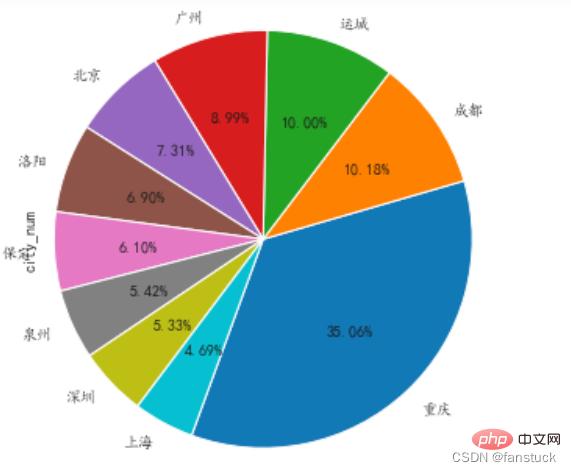
将图表保存起来:
plt.savefig('fig_cat.png')要是你觉得matplotlib的图片不太美观的话,你也可以换成echarts的图片,会更加好看一些:
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
pie.render_notebook()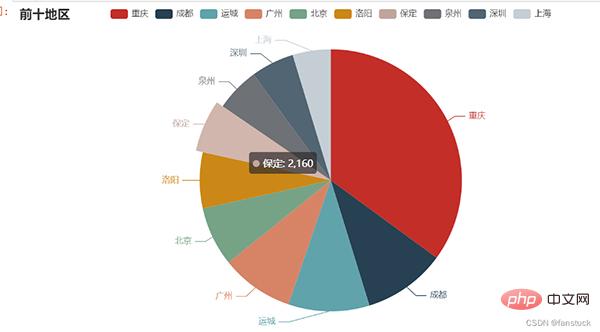
封装后就可以直接使用了:
def echart_pie(user_df):
user_df=user_df[user_df['city_num'].notna()]
user_df=user_df.drop(user_df[user_df['city_num']=='error'].index)
user_df = user_df.city_num.value_counts()
name=user_df.head(10).index.tolist()
value=user_df.head(10).values.tolist()
words=list(zip(list(name),list(value)))
pie = Pie()
pie.add("",words)
pie.set_global_opts(title_opts=opts.TitleOpts(title="前十地区"))
#pie.set_series_opts(label_opts=opts.LabelOpts(user_df))
return pie.render_notebook()
user_df=read_csv('user_info.csv')
echart_pie(user_df)可以进行保存,可惜不是动图:
from snapshot_selenium import snapshot make_snapshot(snapshot,echart_pie(user_df).render(),"test.png")
保存为网页的形式就可以自动加载JS进行渲染了:
echart_pie(user_df).render('problem.html')
os.system('problem.html')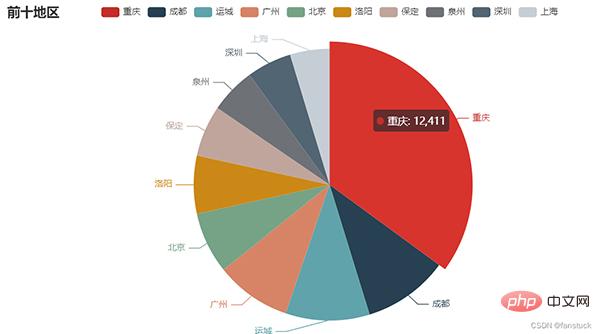
第三步:自动发送邮件
做出来的一系列报表一般都要发给别人看的,对于一些每天需要发送到指定邮箱或者需要发送多封报表的可以使用Python来自动发送邮箱。
在Python发送邮件主要借助到smtplib和email这个两个模块。
- smtplib:主要用来建立和断开与服务器连接的工作。
- email:主要用来设置一些些与邮件本身相关的内容。
不同种类的邮箱服务器连接地址不一样,大家根据自己平常使用的邮箱设置相应的服务器进行连接。这里博主用网易邮箱展示:
首先需要开启POP3/SMTP/IMAP服务:
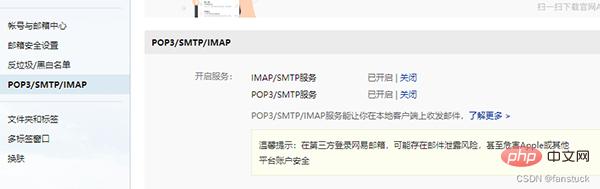
之后便可以根据授权码使用python登入了。
import smtplib
from email import encoders
from email.header import Header
from email.utils import parseaddr,formataddr
from email.mime.application import MIMEApplication
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
#发件人邮箱
asender="fanstuck@163.com"
#收件人邮箱
areceiver="1079944650@qq.com"
#抄送人邮箱
acc="fanstuck@163.com"
#邮箱主题
asubject="谢谢关注"
#发件人地址
from_addr="fanstuck@163.com"
#邮箱授权码
password="####"
#邮件设置
msg=MIMEMultipart()
msg['Subject']=asubject
msg['to']=areceiver
msg['Cc']=acc
msg['from']="fanstuck"
#邮件正文
body="你好,欢迎关注fanstuck,您的关注就是我继续创作的动力!"
msg.attach(MIMEText(body,'plain','utf-8'))
#添加附件
htmlFile = 'C:/Users/10799/problem.html'
html = MIMEApplication(open(htmlFile , 'rb').read())
html.add_header('Content-Disposition', 'attachment', filename='html')
msg.attach(html)
#设置邮箱服务器地址和接口
smtp_server="smtp.163.com"
server = smtplib.SMTP(smtp_server,25)
server.set_debuglevel(1)
#登录邮箱
server.login(from_addr,password)
#发生邮箱
server.sendmail(from_addr,areceiver.split(',')+acc.split(','),msg.as_string())
#断开服务器连接
server.quit()运行测试:
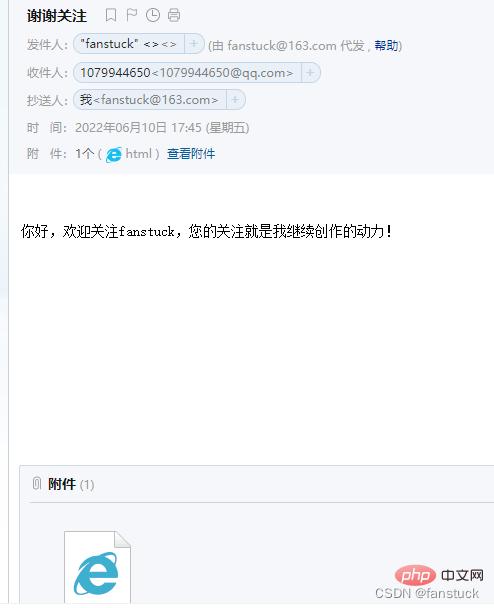
下载文件:
完全没问题!!!
위 내용은 Python 자동화 오피스 애플릿: 보고서 자동화를 실현하고 자동으로 대상 사서함으로 보냅니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!