
자연어 사전 훈련 기술의 진화에 대한 예비 탐색

- 王林앞으로
- 2023-04-11 22:04:041287검색
3가지 수준의 인공 지능:
컴퓨팅 기능: 데이터 저장 및 계산 기능, 기계는 인간보다 훨씬 뛰어납니다.
지각 기능: 시각, 청각 및 기타 능력 기계는 음성 인식 및 이미지 인식 분야에서 이미 인간과 비슷합니다.
인지 지능: 자연어 처리, 상식 모델링 및 추론과 같은 작업에서 기계는 아직 갈 길이 멀습니다.
자연어 처리는 인지 지능의 범주에 속합니다. 자연어는 추상화, 조합, 모호함, 지식, 진화의 특성을 갖고 있기 때문에 자연어 처리를 인공 지능의 보석이라고 부르는 사람도 있습니다. 지능. 최근에는 BERT로 대표되는 사전 훈련된 언어 모델이 등장하여 자연어 처리를 새로운 시대로 이끌었습니다. 사전 훈련된 언어 모델 + 특정 작업에 대한 미세 조정. 이 글은 모든 사람과 소통하고 학습한다는 관점에서 자연어 사전 훈련 기술의 진화를 정리하려고 시도합니다. 우리는 단점과 오류에 대한 비판과 수정을 환영합니다.
1. 고대 - 단어 표현
1.1 One-hot Encoding
은 단어 목록 크기 벡터를 사용하여 단어를 표현하는데, 단어의 해당 위치 값은 1이고 나머지 위치는 0입니다. 단점:
- 고차원 희소성
- 의미적 유사성을 표현할 수 없음: 두 동의어의 원-핫 벡터 유사성은 0
1.2 분산 표현
분산 의미 가정: 비슷한 단어는 유사한 문맥을 갖는다. 단어는 문맥으로 표현될 수 있다. 이 아이디어를 바탕으로 각 단어의 문맥 분포를 사용하여 단어를 나타낼 수 있습니다.
1.2.1 단어 빈도 표현
코퍼스를 기반으로 단어의 문맥을 사용하여 단어 테이블의 각 행은 단어의 벡터 표현을 나타냅니다. 예를 들어, 문장 내 단어 주변의 고정 창에 있는 단어를 컨텍스트로 사용하면 해당 단어의 더 많은 로컬 정보, 즉 어휘 및 구문 정보가 캡처됩니다. document가 문맥으로 사용되며, 단어가 나타내는 주제 정보를 더 많이 캡처합니다. 단점:
- 빈도가 높은 단어 문제.
- 고차 관계를 반영할 수 없습니다: (A, B) (B, C) (C, D) !=> (A, D).
- 아직 희소성 문제가 있습니다.
1.2.2 TF-IDF 표현
단어 빈도 표현의 값을 TF-IDF로 대체합니다. 이는 주로 단어 빈도 표현에서 빈도가 높은 단어의 문제를 완화합니다.
1.2.3 점 상호 정보 표현
은 또한 단어 빈도 표현의 고주파 단어 문제를 완화합니다. 단어 빈도 표현의 값은 단어의 점 상호 정보로 대체됩니다.

1.2.4 LSA
단어 빈도를 비교하여 행렬에 SVD(Singular Value Decomposition)를 적용하여 각 단어에 대한 저차원, 연속 및 조밀한 벡터 표현을 얻습니다. 이는 단어의 잠재적인 의미를 나타내는 것으로 간주할 수 있습니다. 이 방법은 잠재 의미 분석(Latent Semantic Analysis, LSA)이라고도 합니다.

LSA는 빈도가 높은 단어, 고차 관계, 희소성 등과 같은 문제를 완화하며 기존 기계 학습 알고리즘에서는 여전히 그 효과가 좋지만 몇 가지 단점도 있습니다.
- 어휘를 크기가 크면 SVD 속도가 상대적으로 느립니다.
- 코퍼스가 변경되거나 새로운 코퍼스가 추가되면 따라잡을 수 없습니다.
2. 현대 - 정적 단어 벡터
텍스트의 질서와 단어 간의 동시 발생 관계는 자연어 처리를 위한 자연스러운 자기 지도 학습 신호를 제공하여 시스템이 추가 수동 주석 없이 이를 수행할 수 있도록 합니다. .
2.1 Word2Vec
2.1.1 CBOW
CBOW(Continous Bag-of-Words)는 문맥(창)을 사용하여 대상 단어를 예측하고 문맥 단어의 단어 벡터의 산술 평균을 구한 후 예측합니다. 목표 단어의 확률.

2.1.2 Skip-gram
Skip-gram은 단어별로 문맥을 예측합니다.

2.2 GloVe
GloVe(Global Vector for Word Representation)는 단어 벡터를 사용하여 단어의 동시 발생 행렬을 예측하고 암시적 행렬 분해를 구현합니다. 먼저, 단어의 문맥 창을 기반으로 거리 가중 동시 발생 행렬 X를 구성한 다음, 단어와 문맥의 벡터를 사용하여 동시 발생 행렬 X에 맞춥니다.

손실 함수는 다음과 같습니다.

2.3 요약
단어 벡터의 학습은 말뭉치 내 단어 간의 동시 발생 정보를 활용하며 기본 아이디어는 분산 의미 가설입니다. 지역적 맥락을 기반으로 한 Word2Vec이든, 명시적 전역 동시출현 정보를 기반으로 한 GloVe이든, 전체 말뭉치에 있는 단어의 동시출생 문맥 정보를 단어의 벡터 표현으로 집계하여 좋은 결과를 얻는 것이 핵심입니다. . 훈련 속도도 매우 빠르지만 단점의 벡터는 정적입니다. 즉, 상황 변화에 따라 변화하는 능력이 없습니다.
3. 현대 - 사전 훈련된 언어 모델
자동회귀 언어 모델: 시퀀스 기록을 기반으로 현재 순간의 단어에 대한 조건부 확률을 계산합니다.

자동 인코딩 언어 모델: 문맥을 통해 마스크된 단어를 재구성합니다.

마스크된 시퀀스를 나타냅니다.
3.1 Cornerstone - Transformer

3.1.1 Attention 모델
Attention 모델은 벡터 시퀀스에 가중치를 부여하고 가중치를 계산하는 메커니즘으로 이해될 수 있습니다.

3.1.2 Multi-Head Self-Attention
Transformer에서 사용되는 Attention 모델은 다음과 같이 표현할 수 있습니다.

Q, K, V가 동일한 벡터 시퀀스에서 나올 때 self-Attention이 됩니다. 주목모델.
Multi-head self-attention: 여러 그룹의 self-attention 모델을 설정하고 해당 출력 벡터를 연결한 후 선형 매핑을 통해 이를 Transformer 숨겨진 레이어의 차원 크기에 매핑합니다. Multi-head self-attention 모델은 여러 self-attention 모델의 앙상블로 이해될 수 있습니다.


3.1.3 위치 인코딩
Self-Attention 모델은 입력 벡터의 위치 정보를 고려하지 않기 때문에 위치 정보는 시퀀스 모델링에 매우 중요합니다. 위치 정보는 위치 임베딩이나 위치 인코딩을 통해 도입될 수 있습니다. Transformer는 위치 인코딩을 사용합니다.

3.1.4 기타
또한 Transformer 블록에는 Residual Connection, Layer Normalization 및 기타 기술도 사용됩니다.
3.1.5 장점과 단점
장점:
- RNN과 비교하여 Attention 메커니즘은 단어 사이의 거리를 1로 줄여 긴 시퀀스 데이터를 모델링할 수 있습니다.
- RNN과 비교하여 GPU의 병렬 컴퓨팅 성능을 더 잘 활용할 수 있습니다.
- 표현력이 뛰어납니다.
단점:
- RNN에 비해 매개변수가 더 크기 때문에 훈련의 난이도가 높아지고 더 많은 훈련 데이터가 필요합니다.
3.2 자동회귀 언어 모델
3.2.1 ELMo
ELMo: Embeddings from Language Models
Input layer
단어 임베딩을 직접 사용할 수도 있고, CNN 또는 기타 방법을 사용하여 문자를 임베딩할 수도 있습니다. 모델의 순서입니다.

모델 구조

ELMo는 LSTM을 통해 순방향 및 역방향 언어 모델을 독립적으로 모델링합니다. 순방향 언어 모델:

역방향 언어 모델:

최적화 목표
최대화:

다운스트림 애플리케이션
ELMo가 학습된 후 다운스트림 작업에 사용하기 위해 다음 벡터를 얻을 수 있습니다.

은 입력 레이어에서 얻은 단어 임베딩이며 순방향 및 역방향 LSTM 출력을 연결한 결과입니다.
다운스트림 작업에 사용되는 경우 각 레이어의 벡터에 가중치를 부여하여 ELMo의 벡터 표현을 얻을 수 있으며, 가중치를 사용하여 ELMo 벡터의 크기를 조정할 수 있습니다.

다양한 수준의 숨겨진 레이어 벡터에는 다양한 수준 또는 세분성의 텍스트 정보가 포함됩니다.
- 상위 레이어는 더 많은 의미 정보를 인코딩합니다.
- 하위 레이어는 더 많은 어휘 및 구문 정보를 인코딩합니다
3.2 2 GPT 시리즈
GPT-1
모델 구조
GPT-1(Generative Pre-Training)에서는 12개의 변환기 블록 구조를 디코더로 사용하는 단방향 언어 모델이며, 각 변환기 블록은 다중 헤드 자체입니다. -attention 메커니즘을 적용한 후, Full Connection을 통해 출력의 확률 분포를 구합니다.


- U: 단어의 원-핫 벡터
- We: 단어 벡터 행렬
- Wp: 위치 벡터 행렬
최적화 목표
최대화:

다운스트림 애플리케이션
다운스트림 작업에서 레이블이 지정된 데이터 세트의 경우 각 인스턴스에는 레이블로 구성된 입력 토큰이 있습니다. 먼저, 이러한 토큰은 훈련된 사전 훈련 모델에 입력되어 최종 특징 벡터를 얻습니다. 그런 다음 완전 연결 레이어를 통해 예측 결과를 얻습니다.

다운스트림 감독 작업의 목표는 최대화하는 것입니다.

재앙적인 망각 문제를 방지하기 위해 특정 가중치의 예측을 추가할 수 있습니다. 미세 조정 손실, 일반적으로 사전 훈련 손실.


GPT-2
GPT-2의 핵심 아이디어는 다음과 같이 요약할 수 있습니다. 모든 지도 작업은 모델의 용량이 매우 크고 데이터 양이 충분히 풍부할 때입니다. 다른 지도 학습 작업을 완료하면 간단히 언어 모델을 학습할 수 있습니다. 따라서 GPT-2는 GPT-1 네트워크에서 너무 많은 구조적 혁신과 설계를 수행하지 않았으며 더 많은 네트워크 매개 변수와 더 큰 데이터 세트를 사용하여 더 강력한 일반화 능력을 갖춘 단어 벡터를 훈련하는 것이 었습니다.
8가지 언어 모델 작업 중 GPT-2에서는 제로샷 학습만으로 당시의 최첨단 방법을 능가한 작업이 7개 있습니다(물론 일부 작업은 여전히 지도 모델만큼 좋지 않습니다). GPT-2의 가장 큰 기여는 대규모 데이터와 수많은 매개변수로 훈련된 단어 벡터 모델이 추가 훈련 없이 다른 작업 범주로 이전될 수 있음을 검증한 것입니다.
동시에 GPT-2는 모델 용량과 훈련 데이터 양(품질)이 증가함에 따라 잠재력이 더욱 발전할 여지가 있음을 보여주었습니다. 이러한 아이디어를 바탕으로 GPT-3가 탄생했습니다.
GPT-3
모델 구조는 그대로인데, 모델 용량, 훈련 데이터 양, 품질이 엄청나게 높아졌다고 알려져 있고, 효과도 매우 좋습니다.
Summary

GPT-1에서 GPT-3으로, 모델 용량과 훈련 데이터의 양이 증가함에 따라 모델이 학습하는 언어 지식이 풍부해지고 자연어 처리의 패러다임도 " 사전 학습 모델 + 미세 조정'은 점차 '사전 학습 모델 + 제로샷/퓨샷 학습'으로 변환됩니다. GPT의 단점은 단방향 언어 모델을 사용한다는 것입니다. BERT는 양방향 언어 모델이 모델 효과를 향상시킬 수 있음을 입증했습니다.
3.2.3 XLNet
XLNet은 특수 태그를 도입하지 않고 순열 언어 모델을 통해 양방향 상황 정보를 도입하여 사전 훈련 및 미세 조정 단계에서 일관되지 않은 토큰 배포 문제를 방지합니다. 동시에 Transformer-XL은 모델의 주요 구조로 사용되어 긴 텍스트에 더 나은 효과를 줍니다.
순열 언어 모델
순열 언어 모델의 목표는 다음과 같습니다.

은 텍스트 시퀀스의 가능한 모든 순열 집합입니다.
2스트림 Self-attention 메커니즘
- 2스트림 Self-attention 메커니즘(2스트림 Self-attention)의 목적은 일반 텍스트 시퀀스를 입력할 때 Transformer를 변환하여 순열 언어 모델을 달성하는 것입니다.
- 내용 표현: 포함된 정보
- 질의어 표현: 포함된 정보만


이 방법은 예측 단어의 위치 정보를 사용합니다.
다운스트림 애플리케이션
다운스트림 작업을 적용할 때 쿼리 표현이 필요하지 않으며 마스크도 필요하지 않습니다.
3.3 자동 인코딩 언어 모델
3.3.1 BERT
마스크된 언어 모델
마스크된 언어 모델(MLM)은 일부 단어를 무작위로 마스크한 다음 문맥 정보를 사용하여 예측합니다. MLM에는 문제가 있습니다. 사전 훈련과 미세 조정 사이에 불일치가 있습니다. 미세 조정 중에 [MASK] 토큰이 전혀 표시되지 않기 때문입니다. 이 문제를 해결하기 위해 BERT는 항상 "마스크된" 단어 조각 토큰을 실제 [MASK] 토큰으로 대체하지 않습니다. 훈련 데이터 생성기는 토큰의 15%를 무작위로 선택한 다음:
- 80% 확률: 이를 [MASK] 토큰으로 대체합니다.
- 10% 확률: 어휘 목록에서 무작위 토큰으로 대체합니다.
- 10% 확률: 토큰은 변경되지 않습니다.
토큰은 네이티브 BERT에서 마스킹되며, 전체 단어나 구문(N-Gram)이 마스킹될 수 있습니다.
다음 문장 예측
다음 문장 예측(NSP): 문장 A와 B가 사전 훈련 샘플로 선택되면 B가 A의 다음 문장이 될 확률은 50%, 무작위 문장이 될 확률은 50%입니다. 말뭉치의 문장.
입력 레이어

모델 구조

전통적인 "사전 훈련된 모델 + 미세 조정" 패러다임인 테마 구조는 적층형 다층 변환기입니다.
3.3.2 RoBERTa
RoBERTa(Robustly Optimized BERT Pretraining Approach)는 BERT를 획기적으로 개선하지 않고, BERT의 개선 여지를 찾기 위해 BERT의 모든 설계 세부 사항에 대해 상세한 실험만 수행합니다.
- 동적 마스크: 원래 방법은 데이터 세트를 구성할 때 마스크를 설정하고 수정하는 것입니다. 개선된 방법은 각 학습 라운드에서 모델에 데이터를 입력할 때 데이터를 무작위로 마스크하는 것입니다. 자료.
- NSP 작업 포기: NSP 작업을 사용하지 않으면 대부분의 작업 성능이 향상될 수 있다는 것이 실험을 통해 입증되었습니다.
- 더 많은 훈련 데이터, 더 큰 배치, 더 긴 사전 훈련 단계.
- 더 큰 어휘: WordPiece의 문자 수준 BPE 어휘 대신 SentencePiece와 같은 바이트 수준 BPE 어휘를 사용하면 미등록 단어가 거의 없습니다.
3.3.3 ALBERT
BERT는 비교적 많은 수의 매개변수를 가지고 있습니다. ALBERT(A Lite BERT)의 주요 목표는 매개변수를 줄이는 것입니다.
- BERT의 단어 벡터 차원은 숨겨진 레이어 차원과 동일합니다. 단어 벡터는 컨텍스트가 없는 반면 BERT Transformer 레이어는 충분한 컨텍스트 정보가 필요하고 학습할 수 있으므로 숨겨진 레이어 벡터 차원은 단어 벡터 차원보다 훨씬 커야 합니다. 성능 향상을 위해 크기를 늘릴 경우 단어 벡터 공간이 삽입해야 하는 정보량에 충분할 수 있으므로 더 크게 만들 필요가 없습니다.
- Scheme: 단어 벡터는 완전 연결 레이어를 통해 H 차원으로 변환됩니다.
- 인수화된 임베딩 매개변수화.
- 교차 레이어 매개변수 공유: 서로 다른 레이어의 변압기 블록이 매개변수를 공유합니다.
- SOP(문장 순서 예측), 미묘한 의미 차이와 담화 일관성을 학습합니다.
3.4 생성적 대결 - ELECTRA
ELECTRA(Efficiently Learning an Encoder that Classifying Token replacements Accurately)는 생성자와 판별자 모델을 도입하고 생성적 마스크 언어 모델(MLM) 사전 학습 작업을 판별자 A 대체 토큰 감지로 변경합니다. (RTD) 현재 토큰이 언어 모델로 대체되었는지 확인하는 작업으로, 이는 GAN의 아이디어와 유사합니다.

생성기는 입력 텍스트의 마스크 위치에 있는 토큰을 예측합니다.


판별기의 입력은 생성기의 출력이고, 판별기는 각 위치의 단어가 마스크 위치에 있는지 예측합니다. 교체됨:

또한 일부 최적화가 이루어졌습니다.
- 생성기와 판별자는 각각 BERT이고 생성기 BERT 매개변수는 크기가 조정되었습니다.
- 단어 벡터 매개변수 분해.
- 생성기 및 판별기 매개변수 공유: 단어 벡터 행렬 및 위치 벡터 행렬을 포함한 입력 레이어 매개변수가 공유됩니다.
다운스트림 작업에서는 판별자만 사용하고 생성자는 사용하지 마세요.
3.5 긴 텍스트 처리 - Transformer-XL
Transformer 긴 텍스트를 처리하는 일반적인 전략은 텍스트를 고정 길이 청크로 분할하고 청크 간 정보 상호 작용 없이 각 청크를 독립적으로 인코딩하는 것입니다.

긴 텍스트의 모델링을 최적화하기 위해 Transformer-XL은 상태 재사용을 통한 세그먼트 수준 반복 및 상대 위치 인코딩이라는 두 가지 기술을 사용합니다.
3.5.1 상태 재사용의 블록 수준 루프
Transformer-XL도 훈련 중에 고정 길이 세그먼트 형태로 입력됩니다. 차이점은 Transformer-XL의 이전 세그먼트 상태가 캐시된 다음이라는 점입니다. 현재 세그먼트를 계산할 때 이전 시간 조각의 숨겨진 상태를 재사용하면 Transformer-XL이 장기적인 종속성을 모델링할 수 있습니다.
길이 L과 2개의 연속 세그먼트. 은닉층 노드의 상태는 다음과 같이 표현됩니다. 여기서 d는 은닉층 노드의 차원입니다. 히든 레이어 노드의 상태 계산 프로세스는 다음과 같습니다.

조각 재귀의 또 다른 이점은 추론 속도가 향상된다는 것입니다. 한 번에 하나의 타임 슬라이스만 진행할 수 있는 Transformer의 자동 회귀 아키텍처와 비교할 때 Transformer-XL의 추론 프로세스는 처음부터 계산하는 대신 이전 조각의 표현을 직접 재사용합니다. , 이는 추론 프로세스를 단편 추론으로 향상시킵니다.

3.5.2 상대 위치 인코딩
Transformer에서 self-attention 모델은 다음과 같이 표현될 수 있습니다.

완전한 표현은 다음과 같습니다.


조각의 위치 인코딩 이는 동일하며 Transformer의 위치 인코딩은 조각을 기준으로 한 절대 위치 인코딩이며 원본 문장에서 현재 콘텐츠의 상대 위치와는 아무런 관련이 없음을 의미합니다.
Transfomer-XL은 위의 수식을 바탕으로 여러 가지 변경을 하여 다음과 같은 계산 방법을 얻었습니다.

- Change 1: 에서는 실제 합으로 분할되는데, 이는 입력 시퀀스와 위치 인코딩이 더 이상 공유 가중치가 아닙니다.
- 변경 2: 절대 위치 인코딩이 상대 위치 인코딩으로 대체됩니다.
- 변경 3: Transformer의 쿼리 벡터를 대체하기 위해 두 개의 새로운 학습 가능한 매개변수가 도입되었습니다. 해당 쿼리 위치 벡터가 모든 쿼리 위치에 대해 동일함을 나타냅니다. 즉, 쿼리 위치에 관계없이 다양한 단어에 대한 주의 편향은 일관되게 유지됩니다.
- 개선 후 각 부분의 의미:
- 콘텐츠 기반 관련성(): 쿼리 내용과 키 간의 상관 정보 계산
- 콘텐츠 관련 위치 오프셋(): 쿼리 내용과 키 계산 위치 코드 간의 연관 정보
- Global content offset(): 쿼리의 위치 코드와 키의 내용 간의 연관 정보 계산
- Global position offset(): 쿼리 및 키의 위치 코드 계산 관련 정보
3.6 Distillation 및 압축 - DistillBert
지식 증류 기술(KD): 일반적으로 교사 모델과 학생 모델로 구성되어 학생 모델이 교사 모델에 최대한 가깝도록 교사 모델의 지식을 전달합니다. , 실제 적용에서는 학생 모델이 교사 모델보다 작아야 하고 기본적으로 원래 모델의 효과를 유지해야 하는 경우가 많습니다.
DistillBert의 학생 모델:
- 6층 BERT, 토큰 유형 임베딩(세그먼트 임베딩)을 제거했습니다.
- 교사 모델의 처음 6개 레이어를 초기화에 사용하세요.
- 훈련에는 마스크된 언어 모델만 사용하고 NSP 작업은 사용하지 않습니다.
Teacher 모델: BERT-base:
손실 함수:
감독된 MLM 손실: 마스크된 언어 모델로 훈련하여 얻은 교차 엔트로피 손실:
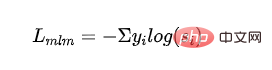
- 은 번째 범주의 레이블을 나타냅니다. 는 학생 모델 범주의 출력 확률을 나타냅니다.
- 증류된 MLM 손실: 교사 모델의 확률을 지침 신호로 사용하고 학생 모델의 확률로 교차 엔트로피 손실을 계산합니다.
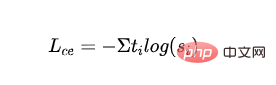
- 은 교사 모델 카테고리의 레이블을 나타냅니다. .
- 워드 벡터 코사인 손실: Teacher 모델과 Student 모델의 히든 레이어 벡터 방향을 정렬하고, 히든 레이어 차원에서 Teacher 모델과 Student 모델 간의 거리를 단축:
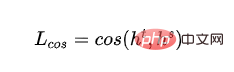
- 교사 모델과 학생 모델의 마지막 레이어의 숨겨진 레이어 출력을 각각 나타냅니다.
- 최종 손실:
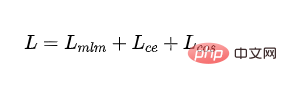
4. 참조
https://www.php.cn/link/6e2290dbf1e11f39d246e7ce5ac50a1e
https://www.php. cn/link/664c7298d2b73b3c7fe2d1e8d1781c06
https://www.php.cn/link/67b878df6cd42d142f2924f3ace85c78
https:// www.php. cn/link/f6a673f09493afcd8b129a0bcf1cd5bc
https://www.php.cn/link/82599a4ec94aca066873c99b4c741ed8
https://www.php.cn/link/2e64da0bae6a7533021c760d4ba5d621
https :/ /www.php.cn/link/56d33021e640f5d64a611a71b5dc30a3
https://www.php.cn/link/4e38d30e656da5ae9d3a425109ce9e04
https://www.php.cn /링크 /c055dcc749c2632fd4dd806301f05ba6
https://www.php.cn/link/a749e38f556d5eb1dc13b9221d1f994f
https://www.php.cn /link/ 8ab9bb97ce35080338be74dc6375e0ed
https://www.php.cn/link/4f0bf7b7b1aca9ad15317a0b4efdca14
https://www.php.cn/link/b81132591828d622fc335860bffec150
https://www. php.cn/link/fca758e52635df5a640f7063ddb9cdcb
https://www.php.cn/link/5112277ea658f7138694f079042cc3bb
https://www. php.cn/link/ 257deb66f5366aab34a23d5fd0571da4
https://www.php.cn/link/b18e8fb514012229891cf024b6436526
https://www.php.cn/link /836a0dcbf5d22652569dc3a708274c 16
https ://www.php.cn/link/a3de03cb426b5e36f5c7167b21395323
https://www.php.cn/link/831b342d8a83408e5960e9b0c5f31f0c
https://www.php .cn /link/6b27e88fdd7269394bca4968b48d8df4
https://www.php.cn/link/682e0e796084e163c5ca053dd8573b0c
https://www.php .cn /link/9739efc4f01292e764c86caa59af353e
https://www.php.cn/link/b93e78c67fd4ae3ee626d8ec0c412dec
https://www.php.cn/link/c8cc6e90ccbff44c9cee23611711cdc4
위 내용은 자연어 사전 훈련 기술의 진화에 대한 예비 탐색의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!