
Python 프로그래밍: 네임드 튜플 사용의 핵심 사항에 대한 자세한 설명

- PHPz앞으로
- 2023-04-11 21:22:163778검색
머리말
이 글에서는 계속해서 Python 컬렉션 모듈을 소개합니다. 이번에는 그 안에 있는 네임드 튜플, 즉 네임드 튜플(namedtuple)의 사용법을 주로 간략하게 소개합니다. 더 이상 고민할 필요 없이 시작하겠습니다. 좋아요, 팔로우 및 전달을 기억하세요~ ^_^
네임드 튜플 만들기
파이썬 컬렉션의 네임드 튜플 클래스는 튜플의 각 위치에 의미를 부여하고 코드 가독성과 설명성을 향상시킵니다. 일반 튜플이 사용되는 모든 곳에서 사용할 수 있으며 위치 인덱스가 아닌 이름으로 필드에 액세스하는 기능을 추가합니다. 이는 Python 내장 모듈 컬렉션에서 나옵니다. 사용되는 일반 구문은 다음과 같습니다.
import collections XxNamedTuple = collections.namedtuple(typename, field_names):
import collections as cAlias, from collections import namestuple, from collections import namestuple as NamedTuple 등과 같이 가져오기 방법이 다른 경우 우리가 만드는 네임드 튜플 하위 클래스의 형식이 해당될 수 있습니다. to :
XxNamedTuple = cAlias.namedtuple(……) XxNamedTuple = namedtuple(……) XxNamedTuple = NamedTuple(……)
Where:
매개변수 typename: 반환된 새 튜플 하위 클래스 XxNamedTuple에 대한 문자열 클래스 이름을 지정합니다. 속성 조회, 위치 인덱싱 및 반복을 통해 액세스할 수 있는 관련 필드가 있는 튜플형 객체를 생성하기 위한 새로운 서브클래스입니다. 서브클래스의 인스턴스에는 유용한 독스트링(도움말 문서와 동일, typename 및 field_names 포함)과 이름=값 형식으로 튜플 내용을 나열하는 유용한 __repr__() 메서드가 있습니다.
매개변수 field_names: 일반적으로 ['x', 'y']와 같은 일련의 문자열입니다. 선택적으로 field_names는 ' x y ' 또는 ' x, y '와 같이 공백 및/또는 쉼표로 구분된 해당 필드 이름을 포함하는 문자열일 수 있습니다.
모든 유효한 Python 식별자를 명명된 필드 이름으로 사용할 수 있지만 밑줄(_)로 시작할 수는 없습니다. 유효한 식별자에는 문자, 숫자, 밑줄이 포함되지만 숫자나 밑줄로 시작하면 안 되며, class, return, global, pass, raise 등의 키워드는 사용할 수 없습니다.
NamedTuple의 작동 방식을 이해하기 위해 ID, 이름 및 연령 속성이 있는 Employee 개체가 있다고 가정해 보겠습니다. 코드 샘플 목록을 참조하세요.

프로그램 실행의 출력 결과는 다음과 유사합니다.
Employee(, name='Solo Cui ', age='18') 按索引方式访问Employee的名子为 : Solo Cui Employee(, name='Annie Kent', age='26') 按键(字段名)访问Employee的名子为 : Annie Kent
또한 명명된 튜플을 생성하는 함수의 다른 매개 변수는 거의 사용되지 않습니다. 간략한 소개:
매개변수 이름 바꾸기: 이름 바꾸기가 true인 경우 유효하지 않은 필드 이름은 자동으로 위치 이름으로 대체됩니다. 예를 들어, ['abc', 'def', 'ghi', 'abc']는 ['abc', '_1', 'ghi', '_3']로 변환되어 def 키워드와 중복된 필드 이름 abc를 제거합니다. .
매개변수 기본값: None이거나 기본값이 있는 반복 가능한 객체일 수 있습니다. 기본값이 있는 필드는 기본값이 없는 필드 뒤에 나타나야 하므로 기본값은 가장 오른쪽 매개변수에 왼쪽부터 순차적으로 적용됩니다. 예를 들어, 필드 이름이 ['x', 'y', 'z']이고 기본값이 (1,2)인 경우 x는 필수 매개변수가 되고, y는 기본값이 1로, z는 기본값이 됩니다. 2.
매개변수 모듈: 모듈이 정의된 경우 명명된 튜플의 __module__ 속성이 이 값으로 설정됩니다.
네임드 튜플 인스턴스는 각 인스턴스에 대해 별도의 사전을 사용하지 않으므로 가볍고 일반 튜플보다 더 많은 메모리를 필요로 하지 않습니다.
네임드 튜플 특정 메서드
네임드 튜플은 튜플에서 상속된 메서드 외에도 세 가지 추가 메서드와 두 가지 속성을 지원합니다. 필드 이름과의 충돌을 방지하기 위해 메서드 및 속성 이름은 밑줄로 시작합니다.
1) _make(iterable):
기존 시퀀스나 반복 가능한 객체에서 새 인스턴스를 생성하는 클래스 메서드입니다. 코드 예제는 다음과 같습니다.

출력 결과는 다음과 유사합니다.
Employee(, name='Batman', age='28')
2) _asdict ():
필드 이름을 해당 값에 매핑하는 새 사전을 반환합니다. 샘플 코드는 다음과 같습니다.

출력은 다음과 유사합니다.
{'id': '333', 'name': 'Batman', 'age': '28'}
3)_replace (**kwargs):
지정된 필드를 다음으로 대체하여 명명된 튜플의 새 인스턴스를 반환합니다. 새로운 가치. 코드 예제는 다음과 같습니다.

출력 결과는 다음과 같습니다.
Employee(, name='Batman', age='34')
4) _fields:
필드 이름을 문자열 튜플로 나열합니다. 기존 명명된 튜플에서 새로운 명명된 튜플 유형을 자체 조사하고 생성하는 데 사용됩니다. 샘플 코드는 다음과 같습니다.

출력 결과는 다음과 같습니다.
('id', 'name', 'age')我们可以使用_fields属性从现有的命名元组中创建新的命名元组。示例如下:
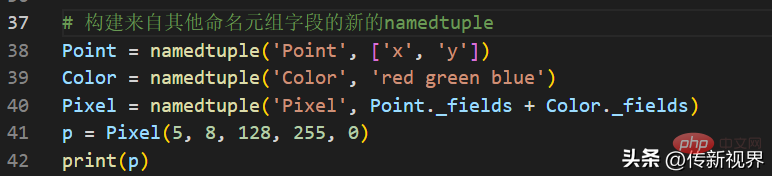
输出结果类似如下:
Pixel(x=5, y=8, red=128, green=255, blue=0)
结果的实体性赋值
这里所说的实体,类似Java中的数据实体对象——只有简单的属性字段。而命名元组在为csv或sqlite3模块操作而返回的元组结果分配给对应字段名而装配成简单实体时特别有用,自动进行字段的对应赋值。比如在当前Python程序位置有个employees.csv,其包含内容如下:
张三,26,工程师,开发部,中级 李四,32,项目经理,项目部,高级
通过示例,我们来完成Employee实体的命名元组的自动装配,代码示例如下:
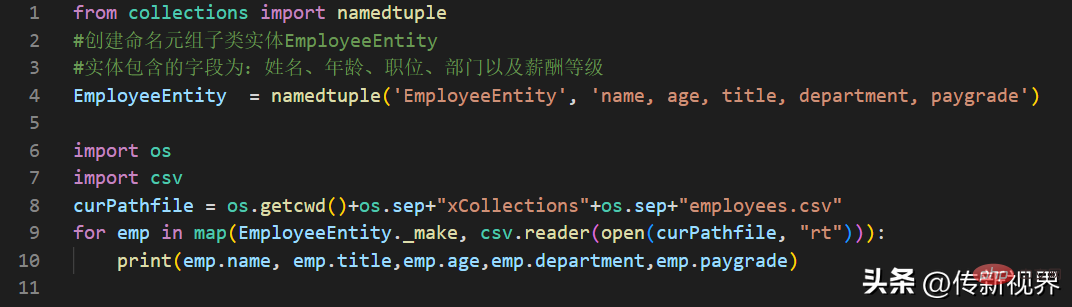
输出结果类似如下:
张三 工程师 26 开发部 中级 李四 项目经理 32 项目部 高级
再简单地来个数据库操作和装配实体的示例,代码清单如下:
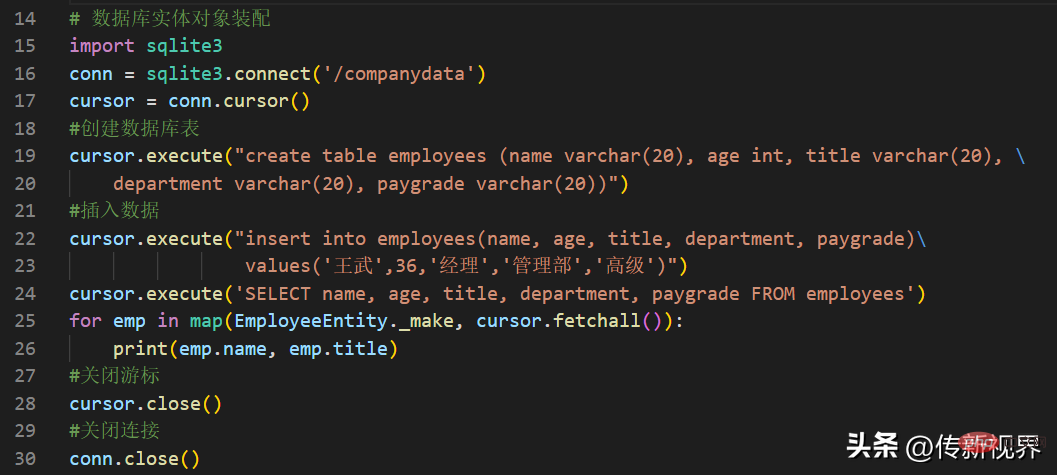
我这里只是简单的创建了数据库并创建表,然后插入一条数据,再查询并完成命名元组的实体化装配和结果输出。
运行输出结果如下:
王武 经理
本文小结
本文主要介绍了Python自带集合模块中的命名元组(namedtuple)的使用,即可以当做一般的元组使用,由可基于字段名的方式访问元组值,并介绍了命名元组内部扩展的几个方法和和属性的应用示例。最后还介绍了基于命名元组的实体化封装应用。基于代码示例进行介绍,这样便于你动手实践,以便更好地掌握和理解。
위 내용은 Python 프로그래밍: 네임드 튜플 사용의 핵심 사항에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!