



11월 28일 NeurIPS 2022가 공식 오픈했습니다.
세계에서 가장 권위 있는 인공지능 행사 중 하나인 NeurIPS는 매년 말마다 컴퓨터 과학 분야의 주목을 받고 있습니다. NeurIPS가 승인한 논문은 현재 최고 수준의 신경과학과 인공지능 연구를 대표하며, 업계 동향의 변화도 반영합니다.
흥미로운 점은 올해 '참가자'들이 조사 결과 '게임'을 특별히 좋아하는 것 같다는 점입니다.
예를 들어, Minecraft 게임 환경을 기반으로 한 Li Feifei 팀의 MineDojo는 최고의 데이터 세트 및 벤치마크 논문 상을 수상했습니다. 게임의 개방성에 의존하여 연구자들은 MineDojo의 다양한 유형의 작업을 통해 에이전트를 훈련할 수 있으며 이를 통해 AI에게 보다 일반적인 기능을 제공할 수 있습니다.

그리고 엄격한 입학률을 통해 게임 분야에 포함되는 또 다른 논문이기도 하며, 이는 많은 게임 플레이어에게 관련이 있을 수 있습니다.
왕중왕을 플레이하지 않은 사람이 어디 있겠어요?

논문 "Arena: A Generalization Environment for Competitive Reinforcement Learning"
주소: https://openreview.net/pdf?id=7e6W6LEOBg3
본문 중 연구진은 MOBA 게임 '아너 오브 킹스'를 기반으로 테스트 환경을 제안했다. 목적은 실제로 AI를 훈련시키는 MineDojo와 유사합니다.
MOBA 게임 환경이 왜 그렇게 인기가 있나요?
DeepMind가 AlphaGo를 출시한 이후, 게임은 높은 자유도와 높은 복잡성을 지닌 시뮬레이션 환경으로서 오랫동안 AI 연구와 실험에 중요한 선택이 되었습니다.
그러나 개방형 작업을 통해 지속적으로 학습할 수 있는 인간에 비해 복잡성이 낮은 게임에서 훈련된 에이전트는 특정 작업 이상으로 자신의 능력을 일반화할 수 없습니다. 간단히 말해서, 이러한 AI는 체스나 고대 Atari 게임만 할 수 있습니다.
보다 "범용"이 가능한 AI를 개발하기 위해 학술 연구의 초점은 점차 보드 게임에서 불완전한 정보 게임(예: 포커)과 전략 게임(예: MOBA 및 RTS 게임 등).
동시에 Li Feifei 팀이 수상 논문에서 말했듯이 에이전트가 더 많은 작업을 일반화하려면 훈련 환경에서 충분한 작업을 제공해야 합니다.

AlphaGo와 그 파생물인 AlphaZero를 사용하여 바둑계의 무적 플레이어를 모두 물리친 DeepMind는 이를 빠르게 깨달았습니다.
2016년 DeepMind는 Blizzard와 협력하여 공간 복잡도가 10의 1685승인 "StarCraft II"를 기반으로 하는 "StarCraft II 학습 환경"(SC2LE)을 출시하여 연구원들에게 다음과 같은 액션 및 보상 사양을 제공했습니다. 에이전트는 물론 게임 엔진과 통신하기 위한 오픈 소스 Python 인터페이스도 제공됩니다.

중국에도 우수한 자격을 갖춘 "AI 훈련장"이 있습니다.
잘 알려진 MOBA 게임으로 "Honor of Kings"에서 플레이어의 액션 상태 공간이 10에 달합니다. 20,000의 제곱은 바둑이나 다른 게임보다 훨씬 크고, 전체 우주의 원자 수(10의 80승)보다 훨씬 더 많습니다.
DeepMind와 마찬가지로 Tencent의 AI Lab도 'Honor of Kings'와 협력하여 AI 연구에 더 적합한 'Honor of Kings AI 개방형 연구 환경'을 공동 개발했습니다.

현재 "왕의 명예 AI 개방형 연구 환경"에는 1v1 전투 환경과 기본 알고리즘 모델이 포함되어 있으며, 영웅 20명의 미러 전투 임무와 비미러 전투 임무를 지원합니다.
구체적으로 "Glory of Kings AI 개방형 연구 환경"은 양측의 영웅 선택만을 고려할 때 20×20=400 전투 하위 작업을 지원할 수 있습니다. 소환사 스킬까지 포함하면 시드퀘스트가 4만개가 됩니다.
"Honor of Kings AI 개방형 연구 환경"에서 에이전트가 수용하는 일반화 문제를 모든 사람이 더 잘 이해할 수 있도록 하기 위해 논문의 두 가지 테스트를 사용하여 이를 확인할 수 있습니다.

먼저 레벨이 엔트리 레벨 "골드"인 행동 트리 AI(BT)를 만듭니다. 그 반대는 강화학습 알고리즘으로 훈련된 에이전트(RL)입니다.
첫 번째 실험에서는 초선(RL)과 초선(BT)만이 전투를 할 수 있도록 허용했고, 이후 훈련된 RL(초선)을 이용해 다양한 영웅(BT)에 도전했습니다.
98회 테스트 결과는 아래 그림과 같습니다.
상대 영웅이 바뀌면 동일한 훈련 전략의 성능이 급격히 떨어집니다. 상대 영웅의 변화로 인해 테스트 환경이 훈련 환경과 달라지기 때문에 기존 방법으로 학습한 전략은 일반화가 부족합니다.

그림 1 상대 간 일반화 챌린지
두 번째 실험에서는 댜오찬(RL)과 댜오찬(BT)만 경쟁하도록 허용한 후 훈련된 RL 모델을 Control로 사용했습니다. 초선(BT)에 도전할 다른 영웅들.
98회 테스트 결과는 아래 그림과 같습니다.
모델이 제어하는 대상이 초선에서 다른 영웅으로 변경되면 동일한 훈련 전략의 성능이 급격히 떨어집니다. 대상 영웅의 변화로 인해 훈련 환경에서 초선의 행동과 행동의 의미가 달라지기 때문입니다.

그림 2 교차 대상 일반화 챌린지
이 결과의 이유는 간단합니다. 각 영웅은 고유한 운영 기술을 가지고 있습니다. 사용 방법을 모르면 눈을 멀게 할 수 있습니다.
인간 플레이어도 마찬가지입니다. 중간에 "무작위로 죽이기"가 가능한 플레이어는 정글로 변경한 후 좋은 KDA를 달성하지 못할 수도 있습니다.
이것이 실제로 우리가 처음에 제기한 질문으로 돌아가는 것을 보는 것은 어렵지 않습니다. 단순한 환경에서 "보편적" AI를 훈련시키는 것은 어렵습니다. 복잡성이 높은 MOBA 게임은 모델의 일반화를 테스트하는 데 편리한 환경을 제공할 뿐입니다.
물론 AI를 훈련시키는 데 게임을 직접 사용할 수 없기 때문에 특별히 최적화된 "훈련장"이 탄생했습니다.
이와 같이 연구자들은 "스타크래프트 II 학습 환경", "왕의 영광 AI 개방형 연구 환경"과 같은 환경에서 자신의 모델을 테스트하고 훈련할 수 있습니다.
국내 연구자들이 적절한 플랫폼 리소스에 어떻게 접근할 수 있나요?
DeepMind의 발전은 Google의 강력한 지원과 불가분의 관계입니다. Li Feifei 팀이 제안한 MineDojo는 명문 대학인 Stanford의 리소스를 사용할 뿐만 아니라 NVIDIA의 강력한 지원을 받고 있습니다.
현재 국내 인공지능 산업은 인프라 수준에서 아직 충분히 탄탄하지 않으며, 특히 연구개발 자원이 부족한 일반 기업과 대학의 경우 더욱 그렇습니다.
더 많은 연구자들이 참여할 수 있도록 Tencent는 올해 11월 21일 공식적으로 "왕의 명예 AI 공개 연구 환경"을 대중에게 공개했습니다.
사용자는 Enlightenment Platform 공식 웹사이트에 계정을 등록하고, 정보를 제출하고, 플랫폼 검토를 통과하면 무료로 다운로드할 수 있습니다.

웹사이트 링크: https://aiarena.tencent.com/aiarena/zh/open-gamecore
For를 수행하는 학자와 알고리즘 개발자를 더 잘 지원하기 위해 언급할 가치가 있습니다. 연구를 위해 Enlightenment 플랫폼은 사용 편의성을 위해 "Glory of Kings AI 개방형 연구 환경"을 캡슐화할 뿐만 아니라 표준 코드 및 교육 프레임워크도 제공합니다.

다음으로 Enlightenment Platform에서 AI 교육 프로젝트를 시작하는 방법에 대한 "얕은" 경험을 해보겠습니다!
AI가 "왕의 명예"를 "연주"하기를 원하기 때문에 가장 먼저 해야 할 일은 영웅을 제어하는 데 사용되는 "지능형 신체"를 만드는 것입니다.
좀 복잡하게 들리나요? 그러나 "Glory of Kings AI 공개 연구 환경"에서는 이것이 실제로 매우 간단합니다.
먼저 게임 코어 서버를 시작하세요:
cd gamecoregamecore-server.exe server --server-address :23432
hok_env 패키지를 설치하세요:
git clone https://github.com/tencent-ailab/hok_env.gitcd hok_env/hok_env/pip install -e .
그리고 테스트 스크립트를 실행하세요:
cd hok_env/hok_env/hok/unit_test/python test_env.py
이제 hok를 가져오고 hok.HoK1v1.load_game을 호출할 수 있습니다. 환경을 생성하려면 다음과 같습니다:
import hok
env = HoK1v1.load_game(runtime_id=0, game_log_path="./game_log", gamecore_path="~/.hok", config_path="config.dat",config_dicts=[{"hero":"diaochan", "skill":"rage"} for _ in range(2)])다음으로 환경을 재설정하여 에이전트로부터 첫 번째 관찰을 얻습니다.
obs, reward, done, infos = env.reset()
obs는 에이전트의 환경 관찰을 설명하는 NumPy 배열 목록입니다.
reward은 환경으로부터 받는 즉각적인 보상을 설명하는 부동 소수점 스칼라 목록입니다.
done은 게임 상태를 설명하는 부울 목록입니다.
infos 변수는 길이가 에이전트 수인 사전의 튜플입니다.
그런 다음 시간이 다 되거나 에이전트가 죽을 때까지 환경에서 작업을 수행합니다.
여기서는 env.step 메소드를 사용하세요.
done = False while not done: action = env.get_random_action() obs, reward, done, state = env.step(action)
"스타크래프트 II 학습 환경"과 마찬가지로 시각화 도구를 사용하여 "왕의 명예 AI 공개 연구 환경"에서 에이전트의 재생을 볼 수도 있습니다.
이 시점에서 첫 번째 에이전트가 생성되었습니다.
다음으로는 '그녀/그'를 데리고 다양한 훈련을 해볼 수 있어요!

이렇게 말하면 "왕의 영예 AI 개방형 연구 환경"이 단순히 AI를 훈련할 수 있는 환경을 제공하는 것이 아니라, 친숙한 조작과 풍부한 문서를 통해 누구나 알아차리는 것은 어렵지 않을 것입니다. , 전체 프로세스를 간단하고 이해하기 쉽게 만듭니다.
이렇게 하면 AI 분야 진출에 관심이 있는 더 많은 사람들이 쉽게 시작할 수 있습니다.
게임+AI, 또 어떤 가능성이 있나요?
이를 보면 실제로 답이 남아 있지 않은 질문이 있습니다. 기업이 주도하는 연구 플랫폼으로서 Tencent Enlightenment Platform이 대규모 공개를 선택한 이유는 무엇입니까?
올해 8월, 청두 인공 지능 산업 생태 연합과 싱크탱크 Yuqian Consultants가 공동으로 국내 최초의 게임 AI 보고서를 발표했습니다. 게임은 인공지능 발전을 촉진하는 핵심 포인트 중 하나라는 점을 보고서에서 쉽게 알 수 있다. 구체적으로 게임은 세 가지 측면에서 AI 활용을 향상시킬 수 있다.

우선, 게임은 AI를 위한 훌륭한 훈련이자 테스트 장소입니다.
- 빠른 반복: 게임은 실제 비용 없이 마음대로 상호 작용하고 시도하고 만들 수 있습니다. 동시에 알고리즘의 효과를 완전히 보여줄 수 있는 명확한 보상 메커니즘이 있습니다.
- 풍부한 작업: 난이도와 복잡성이 다양한 다양한 유형의 게임이 있습니다. 인공 지능은 이를 처리하기 위해 복잡한 전략을 채택해야 합니다. 다양한 유형의 게임을 정복하는 것은 알고리즘 수준의 향상을 반영합니다.
- 명확한 성공 또는 실패 기준: 게임 점수를 통해 인공 지능의 능력을 보정하여 인공 지능의 추가 최적화를 촉진합니다.
둘째, 게임은 AI의 다양한 능력을 훈련하고 다양한 애플리케이션으로 이어질 수 있습니다.
예를 들어, 체스 게임은 AI를 훈련시켜 순서 결정을 내리고 장기 추론 능력을 얻습니다. 카드 게임은 AI가 동적으로 적응하고 적응성을 얻도록 훈련합니다. 및 다중 에이전트 기능. 협업 능력 및 이동 일관성.
또한 게임은 환경 제약을 깨고 지능적인 의사 결정을 촉진할 수도 있습니다.
예를 들어 게임은 가상 시뮬레이션 실시간 렌더링 및 가상 시뮬레이션 정보 동기화를 촉진하고 가상 시뮬레이션 대화형 터미널을 업그레이드할 수 있습니다.

Enlightenment 플랫폼은 알고리즘, 컴퓨팅 성능, 복잡한 시나리오 등의 측면에서 Tencent AI Lab과 Honor of Kings의 장점을 활용합니다. 개방 후 게임 간의 효과적인 협력을 위한 다리와 링크를 구축할 수 있습니다. 및 AI 개발. 대학 규율 구축, 경쟁 조직 및 산업 인재 육성. 인재 풀이 충분하면 과학 연구의 발전과 상업적인 응용이 비가 내린 뒤 버섯처럼 솟아오를 것입니다.
지난 2년 동안 Kaiwu 플랫폼은 산업, 학계, 연구 분야에서 많은 조치를 취했습니다. "Kaiwu 다중 에이전트 강화 학습 대회"를 개최하여 TOP2 유명 대학 팀을 포함한 최고의 대학 팀을 유치했습니다. Qingbei와 같은 대학이 참여하여 북경 대학교 정보 과학 기술 학교의 인기 선택 과목 "게임 AI 알고리즘"을 설립하고 방과 후 숙제는 Honor of Kings 1V1 환경을 사용하여 실험을 수행하는 것입니다...
미래를 내다보면 다음과 같습니다. 기대: "Enlightenment" 플랫폼의 도움으로 글로벌하게 진출하는 이러한 인재들은 AI 산업의 다양한 분야로 빛을 발하고 플랫폼의 상류 및 하류 생태계의 만개를 실현할 것입니다. .
위 내용은 AI가 왕을 이길 수 있는 방법을 배우게 하면 무슨 소용이 있을까요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Claude vs Gemini : 포괄적 인 비교 - 분석 VidhyaApr 13, 2025 am 09:20 AM
Claude vs Gemini : 포괄적 인 비교 - 분석 VidhyaApr 13, 2025 am 09:20 AM소개 빠르게 변화하는 인공 지능 분야에서 Claude와 Gemini라는 두 가지 언어 모델이 저명한 경쟁자가되었으며, 각각은 독특한 장점과 기술을 제공합니다. 두 모델 모두 마나를 할 수 있습니다
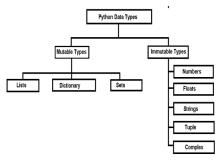 파이썬의 변이성 대 불변 대상 - 분석 VidhyaApr 13, 2025 am 09:15 AM
파이썬의 변이성 대 불변 대상 - 분석 VidhyaApr 13, 2025 am 09:15 AM소개 Python은 객체 지향 프로그래밍 언어 (또는 OPS)입니다. 이전 기사에서는 다재다능한 특성을 탐구했습니다. 이로 인해 Python은 다양한 데이터 유형을 제공하며 광범위하게 M으로 분류 할 수 있습니다.
 11 개의 YouTube 채널을 무료로 배우는 Tableau -Analytics VidhyaApr 13, 2025 am 09:14 AM
11 개의 YouTube 채널을 무료로 배우는 Tableau -Analytics VidhyaApr 13, 2025 am 09:14 AM소개 Tableau는 효율적인 데이터 분석 및 프레젠테이션을 위해 전 세계 회사와 개인이 현재 사용중인 가장 강력한 데이터 시각화 도구 중 하나로 간주됩니다. 사용자 친화적 인 인터페이스와 Exten
 10 생성 AI 코드의 생성 AI 코딩 확장 대 코드를 탐색해야합니다.Apr 13, 2025 am 01:14 AM
10 생성 AI 코드의 생성 AI 코딩 확장 대 코드를 탐색해야합니다.Apr 13, 2025 am 01:14 AM이봐, 코딩 닌자! 하루 동안 어떤 코딩 관련 작업을 계획 했습니까? 이 블로그에 더 자세히 살펴보기 전에, 나는 당신이 당신의 모든 코딩 관련 문제에 대해 생각하기를 원합니다. 완료? - ’
 요리 혁신 요리 : 인공 지능이 식품 서비스를 변화시키는 방법Apr 12, 2025 pm 12:09 PM
요리 혁신 요리 : 인공 지능이 식품 서비스를 변화시키는 방법Apr 12, 2025 pm 12:09 PMAI 식품 준비 여전히 초기 사용 중이지만 AI 시스템은 음식 준비에 점점 더 많이 사용되고 있습니다. AI 구동 로봇은 부엌에서 햄버거를 뒤집기, 피자 만들기 또는 SA 조립과 같은 음식 준비 작업을 자동화하는 데 사용됩니다
 파이썬 네임 스페이스 및 가변 범위에 대한 포괄적 인 안내서Apr 12, 2025 pm 12:00 PM
파이썬 네임 스페이스 및 가변 범위에 대한 포괄적 인 안내서Apr 12, 2025 pm 12:00 PM소개 파이썬 기능에서 변수의 네임 스페이스, 범위 및 동작을 이해하는 것은 효율적으로 작성하고 런타임 오류 또는 예외를 피하는 데 중요합니다. 이 기사에서는 다양한 ASP를 탐구 할 것입니다
 비전 언어 모델 (VLMS)에 대한 포괄적 인 안내서Apr 12, 2025 am 11:58 AM
비전 언어 모델 (VLMS)에 대한 포괄적 인 안내서Apr 12, 2025 am 11:58 AM소개 생생한 그림과 조각으로 둘러싸인 아트 갤러리를 걷는 것을 상상해보십시오. 이제 각 작품에 질문을하고 의미있는 대답을 얻을 수 있다면 어떨까요? “어떤 이야기를하고 있습니까?
 Mediatek은 Kompanio Ultra 및 Dimensity 9400으로 프리미엄 라인업을 향상시킵니다.Apr 12, 2025 am 11:52 AM
Mediatek은 Kompanio Ultra 및 Dimensity 9400으로 프리미엄 라인업을 향상시킵니다.Apr 12, 2025 am 11:52 AM제품 케이던스를 계속하면서 이번 달 Mediatek은 새로운 Kompanio Ultra and Dimensity 9400을 포함한 일련의 발표를했습니다. 이 제품은 스마트 폰 용 칩을 포함하여 Mediatek 비즈니스의 전통적인 부분을 채우고 있습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

PhpStorm 맥 버전
최신(2018.2.1) 전문 PHP 통합 개발 도구

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

