
Python 데이터 분석 모듈 Numpy 슬라이싱, 인덱싱 및 브로드캐스팅에 대한 자세한 설명

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-10 14:56:322164검색
Numpy 슬라이싱 및 인덱싱
ndarray 객체의 내용은 Python의 목록 슬라이싱 작업과 마찬가지로 인덱싱 또는 슬라이싱을 통해 액세스하고 수정할 수 있습니다.
ndarray 배열은 0 ~ n-1의 첨자를 기반으로 인덱싱할 수 있습니다. 슬라이스 개체는 내장된 슬라이스 함수와 시작, 중지 및 단계 매개변수 설정을 통해 원래 배열에서 새 배열을 잘라낼 수 있습니다. .
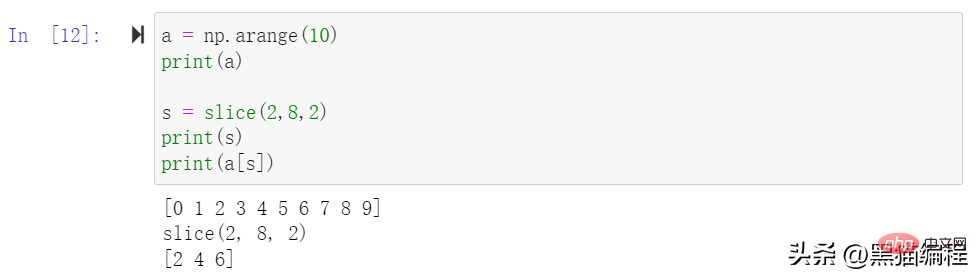

슬라이스에는 선택 튜플의 길이를 배열의 크기와 동일하게 만들기 위해 타원을 포함할 수도 있습니다. 줄임표가 행 위치에 사용되면 행의 요소를 포함하는 ndarray를 반환합니다.
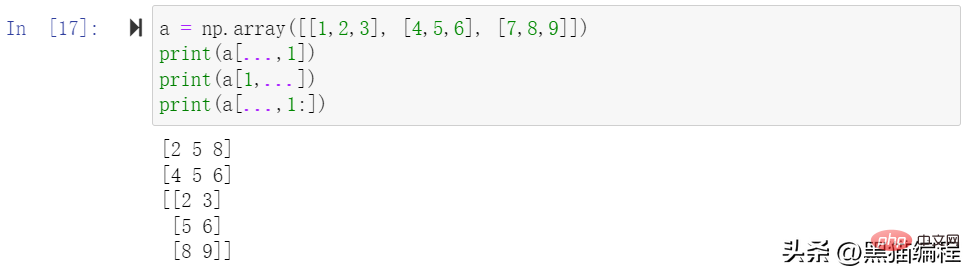
고급 인덱싱
정수 배열 인덱스
다음 예에서는 (0,0), (1,1) 및 (2,0) 위치에 있는 요소를 가져옵니다. 정렬. 반환된 결과는 각 모서리 요소를 포함하는 ndarray 객체입니다.
슬라이스를 사용하여 인덱스 배열과 결합할 수 있습니다. 또는 ... . 다음 예와 같이: 
a = np.array([[0,1,2], [3,4,5], [6,7,8], [9,10,11]])
print(a)
print('-' * 20)
rows = np.array([[0,0], [3,3]])
cols = np.array([[0,2], [0,2]])
b = a[rows, cols]
print(b)
print('-' * 20)
rows = np.array([[0,1], [2,3]])
cols = np.array([[0,2], [0,2]])
c = a[rows, cols]
print(c)
print('-' * 20)
rows = np.array([[0,1,2], [1,2,3], [1,2,3]])
cols = np.array([[0,1,2], [0,1,2], [0,1,2]])
d = a[rows, cols]
print(d)[[ 012] [ 345] [ 678] [ 9 10 11]] -------------------- [[ 02] [ 9 11]] -------------------- [[ 05] [ 6 11]] -------------------- [[ 048] [ 37 11] [ 37 11]]Boolean indexing
Boolean 배열을 통해 대상 배열을 인덱싱할 수 있습니다.
부울 인덱싱은 부울 연산(예: 비교 연산자)을 사용하여 지정된 조건을 충족하는 요소 배열을 얻습니다.
다음 예제에서는 5보다 큰 요소를 가져옵니다.
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(a)
print('-' * 20)
b = a[1:3, 1:3]
print(b)
print('-' * 20)
c = a[1:3, [0,2]]
print(c)
print('-' * 20)
d = a[..., 1:]
print(d)[[1 2 3]
[4 5 6]
[7 8 9]]
--------------------
[[5 6]
[8 9]]
--------------------
[[4 6]
[7 9]]
--------------------
[[2 3]
[5 6]
[8 9]]
다음 예제에서는 ~(보완 연산자)를 사용하여 NaN을 필터링합니다.
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(a)
print('-' * 20)
print(a[a > 5])[[1 2 3] [4 5 6] [7 8 9]] -------------------- [6 7 8 9]
다음 예에서는 배열에서 복잡하지 않은 요소를 필터링하는 방법을 보여줍니다.
a = np.array([np.nan, 1, 2, np.nan, 3, 4, 5])
print(a)
print('-' * 20)
print(a[~np.isnan(a)])[nan1.2. nan3.4.5.] -------------------- [1. 2. 3. 4. 5.]
팬시 인덱싱
팬시 인덱싱은 인덱싱에 정수 배열을 사용하는 것을 의미합니다.
팬시 인덱스는 인덱스 배열의 값을 기준으로 하는 값을 대상 배열 축의 첨자로 취합니다.
1차원 정수 배열을 인덱스로 사용하는 경우 대상이 1차원 배열이면 인덱스 결과는 해당 위치에 있는 요소입니다. 아래 첨자에 해당하는 행.
팬시 인덱싱은 슬라이싱과 다르며 항상 데이터를 새 배열에 복사합니다.
1차원 배열
a = np.array([1, 3+4j, 5, 6+7j])
print(a)
print('-' * 20)
print(a[np.iscomplex(a)])[1.+0.j 3.+4.j 5.+0.j 6.+7.j]
--------------------
[3.+4.j 6.+7.j]
2차원 배열
1. 순차 인덱스 배열을 전달합니다
a = np.arange(2, 10)
print(a)
print('-' * 20)
b = a[[0,6]]
print(b)[2 3 4 5 6 7 8 9] -------------------- [2 8]
2.
a = np.arange(32).reshape(8, 4)
print(a)
print('-' * 20)
print(a[[4, 2, 1, 7]])rrree3 , 여러 인덱스 배열을 전달합니다(np.ix_를 사용해야 합니다).
np.ix_ 함수는 두 개의 배열을 입력하고 데카르트 곱 매핑 관계를 생성하는 것입니다.
데카르트 곱은 수학에서 두 집합 X와 Y의 데카르트 곱(Cartesian product)을 말하며 직접 곱이라고도 하며
X×Y로 표현되며, 첫 번째 객체는 의 멤버입니다. 두 번째 객체는 하나입니다. Y의 가능한 모든 순서쌍의 구성원입니다.
예를 들어 A={a,b}, B={0,1,2}이면 다음과 같습니다.[[ 0123]
[ 4567]
[ 89 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
--------------------
[[16 17 18 19]
[ 89 10 11]
[ 4567]
[28 29 30 31]]
a = np.arange(32).reshape(8, 4)
print(a[[-4, -2, -1, -7]])
[[16 17 18 19]
[24 25 26 27]
[28 29 30 31]
[ 4567]]
Broadcast(Broadcast)는 다양한 모양의 numpy 배열입니다( 모양) 수치 계산이 수행되는 방식으로, 배열에 대한 산술 연산은 일반적으로 해당 요소에 대해 수행됩니다.
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
a = np.arange(1, 5) b = np.arange(1, 5) c = a * b print(c)
[ 149 16]
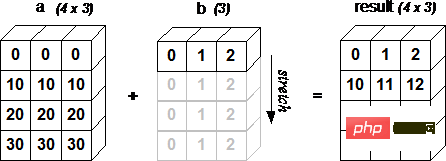
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。如:
a = np.array([ [0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30] ]) b = np.array([0, 1, 2]) print(a + b)
[[ 012] [10 11 12] [20 21 22] [30 31 32]]
下面的图片展示了数组 b 如何通过广播来与数组 a 兼容。
tile扩展数组
a = np.array([1, 2])
b = np.tile(a, (6, 1))
print(b)
print('-' * 20)
c = np.tile(a, (2, 3))
print(c)[[1 2] [1 2] [1 2] [1 2] [1 2] [1 2]] -------------------- [[1 2 1 2 1 2] [1 2 1 2 1 2]]
4x3 的二维数组与长为 3 的一维数组相加,等效于把数组 b 在二维上重复 4 次再运算:
a = np.array([ [0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30] ]) b = np.array([0, 1, 2]) bb = np.tile(b, (4, 1)) print(a + bb)
[[ 012] [10 11 12] [20 21 22] [30 31 32]]
广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 维补齐。
- 输出数组的形状是输入数组形状的各个维度上的最大值。
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
- 数组拥有相同形状。
- 当前维度的值相等。
- 当前维度的值有一个是 1。
若条件不满足,抛出 "ValueError: frames are not aligned" 异常。
위 내용은 Python 데이터 분석 모듈 Numpy 슬라이싱, 인덱싱 및 브로드캐스팅에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!