
Pytorch를 사용하여 자기 지도 사전 학습을 위한 대조 학습 SimCLR 구현

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-04-10 14:11:032088검색
SimCLR(Simple Framework for Contrastive Learning of Representations)은 이미지 표현 학습을 위한 자기 지도 기술입니다. 기존 지도 학습 방법과 달리 SimCLR은 유용한 표현을 학습하기 위해 레이블이 지정된 데이터에 의존하지 않습니다. 이는 대조 학습 프레임워크를 활용하여 레이블이 지정되지 않은 이미지에서 높은 수준의 의미 정보를 캡처할 수 있는 유용한 기능 세트를 학습합니다.
SimCLR은 다양한 이미지 분류 벤치마크에서 최첨단 비지도 학습 방법보다 뛰어난 성능을 보이는 것으로 입증되었습니다. 그리고 학습한 표현은 더 작은 레이블이 지정된 데이터 세트에 대한 미세 조정을 최소화하면서 객체 감지, 의미론적 분할 및 소수 학습과 같은 다운스트림 작업으로 쉽게 전송할 수 있습니다.

SimCLR 주요 아이디어는 향상 모듈 T를 통해 동일한 이미지의 다른 향상된 버전과 비교하여 이미지의 좋은 표현을 학습하는 것입니다. 이는 인코더 네트워크 f(.)를 통해 이미지를 매핑한 다음 이를 투영함으로써 수행됩니다. head g(.)는 학습된 특징을 저차원 공간에 매핑합니다. 그런 다음 동일한 이미지의 유사한 표현과 다른 이미지의 다른 표현을 장려하기 위해 동일한 이미지의 두 가지 향상된 버전 표현 간에 대비 손실이 계산됩니다.
이 기사에서는 SimCLR 프레임워크에 대해 자세히 알아보고 데이터 증대, 대비 손실 함수, 인코더 및 프로젝션을 위한 헤드 아키텍처를 포함한 알고리즘의 주요 구성 요소를 살펴보겠습니다.
여기서는 Kaggle의 가비지 분류 데이터 세트를 사용하여 실험을 수행합니다.
Enhancement module
SimCLR에서 가장 중요한 것은 이미지 변환을 위한 향상 모듈입니다. SimCLR 논문의 저자는 강력한 데이터 증대가 비지도 학습에 유용하다고 제안합니다. 따라서 우리는 논문에서 권장하는 접근 방식을 따를 것입니다.
- 크기 조정을 위한 무작위 자르기
- 50% 확률로 무작위 수평 뒤집기
- 무작위 색상 왜곡(색상 지터 확률 80%, 색상 드롭 확률 20%)
- 무작위 가우시안 블러 확률 50%
def get_complete_transform(output_shape, kernel_size, s=1.0): """ Color distortion transform Args: s: Strength parameter Returns: A color distortion transform """ rnd_crop = RandomResizedCrop(output_shape) rnd_flip = RandomHorizontalFlip(p=0.5) color_jitter = ColorJitter(0.8*s, 0.8*s, 0.8*s, 0.2*s) rnd_color_jitter = RandomApply([color_jitter], p=0.8) rnd_gray = RandomGrayscale(p=0.2) gaussian_blur = GaussianBlur(kernel_size=kernel_size) rnd_gaussian_blur = RandomApply([gaussian_blur], p=0.5) to_tensor = ToTensor() image_transform = Compose([ to_tensor, rnd_crop, rnd_flip, rnd_color_jitter, rnd_gray, rnd_gaussian_blur, ]) return image_transform class ContrastiveLearningViewGenerator(object): """ Take 2 random crops of 1 image as the query and key. """ def __init__(self, base_transform, n_views=2): self.base_transform = base_transform self.n_views = n_views def __call__(self, x): views = [self.base_transform(x) for i in range(self.n_views)] return views
다음 단계는 PyTorch 데이터 세트를 정의하는 것입니다.
class CustomDataset(Dataset): def __init__(self, list_images, transform=None): """ Args: list_images (list): List of all the images transform (callable, optional): Optional transform to be applied on a sample. """ self.list_images = list_images self.transform = transform def __len__(self): return len(self.list_images) def __getitem__(self, idx): if torch.is_tensor(idx): idx = idx.tolist() img_name = self.list_images[idx] image = io.imread(img_name) if self.transform: image = self.transform(image) return image
예를 들어 더 작은 모델 ResNet18을 백본으로 사용하므로 입력은 224x224 이미지입니다. 필요에 따라 일부 매개변수를 설정하고 데이터로더를 생성합니다
out_shape = [224, 224]
kernel_size = [21, 21] # 10% of out_shape
# Custom transform
base_transforms = get_complete_transform(output_shape=out_shape, kernel_size=kernel_size, s=1.0)
custom_transform = ContrastiveLearningViewGenerator(base_transform=base_transforms)
garbage_ds = CustomDataset(
list_images=glob.glob("/kaggle/input/garbage-classification/garbage_classification/*/*.jpg"),
transform=custom_transform
)
BATCH_SZ = 128
# Build DataLoader
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True)
SimCLR
데이터를 준비했습니다. , 모델 재현을 시작합니다. 위의 향상 모듈은 해당 표현을 얻기 위해 인코더를 통해 전달되는 이미지의 두 가지 향상된 보기를 제공합니다. SimCLR의 목표는 모델이 두 개의 서로 다른 증강 보기에서 개체의 일반적인 표현을 학습하도록 장려하여 이러한 서로 다른 학습된 표현 간의 유사성을 최대화하는 것입니다.
인코더 네트워크의 선택은 제한되지 않으며 모든 아키텍처가 될 수 있습니다. 위에서 언급했듯이 간단한 시연을 위해 ResNet18을 사용합니다. 인코더 모델에서 학습된 표현은 유사성 계수를 결정하고, 이러한 표현의 품질을 향상시키기 위해 SimCLR은 프로젝션 헤드를 사용하여 인코딩 벡터를 보다 풍부한 잠재 공간에 투영합니다. 여기서는 ResNet18의 512차원 기능을 256차원 공간에 투영합니다. 매우 복잡해 보이지만 실제로는 relu를 사용하여 mlp를 추가하는 것뿐입니다.
class Identity(nn.Module): def __init__(self): super(Identity, self).__init__() def forward(self, x): return x class SimCLR(nn.Module): def __init__(self, linear_eval=False): super().__init__() self.linear_eval = linear_eval resnet18 = models.resnet18(pretrained=False) resnet18.fc = Identity() self.encoder = resnet18 self.projection = nn.Sequential( nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 256) ) def forward(self, x): if not self.linear_eval: x = torch.cat(x, dim=0) encoding = self.encoder(x) projection = self.projection(encoding) return projection
대비 손실
NT-Xent(정규화된 온도 스케일 교차 엔트로피 손실)라고도 알려진 대비 손실 함수는 모델이 동일한 이미지의 유사한 표현과 차이점을 학습하도록 장려하는 SimCLR의 핵심 구성 요소입니다. 이미지의 다양한 표현.
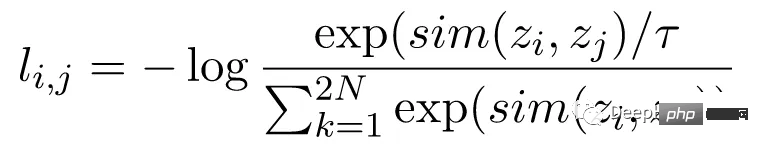
NT-Xent 손실은 해당 표현을 얻기 위해 인코더 네트워크를 통과한 이미지의 한 쌍의 증강 보기를 사용하여 계산됩니다. 대조 손실의 목표는 동일한 이미지에 대한 두 개의 증강 뷰 표현이 유사하도록 장려하는 동시에 서로 다른 이미지의 표현은 서로 다르지 않도록 하는 것입니다.
NT-Xent는 뷰 표현의 쌍별 유사성을 높이기 위해 소프트맥스 기능을 적용합니다. 소프트맥스 함수는 미니 배치 내의 모든 표현 쌍에 적용되어 각 이미지에 대한 유사 확률 분포를 얻습니다. 온도 매개변수는 소프트맥스 함수를 적용하기 전에 쌍별 유사성을 확장하는 데 사용되며, 이는 최적화 중에 더 나은 기울기를 얻는 데 도움이 됩니다.
유사성 확률 분포를 얻은 후, 동일한 이미지의 표현 일치에 대한 로그 가능성을 최대화하고 서로 다른 이미지의 불일치 표현에 대한 로그 가능성을 최소화하여 NT-Xent 손실을 계산합니다.
LABELS = torch.cat([torch.arange(BATCH_SZ) for i in range(2)], dim=0) LABELS = (LABELS.unsqueeze(0) == LABELS.unsqueeze(1)).float() #one-hot representations LABELS = LABELS.to(DEVICE) def ntxent_loss(features, temp): """ NT-Xent Loss. Args: z1: The learned representations from first branch of projection head z2: The learned representations from second branch of projection head Returns: Loss """ similarity_matrix = torch.matmul(features, features.T) mask = torch.eye(LABELS.shape[0], dtype=torch.bool).to(DEVICE) labels = LABELS[~mask].view(LABELS.shape[0], -1) similarity_matrix = similarity_matrix[~mask].view(similarity_matrix.shape[0], -1) positives = similarity_matrix[labels.bool()].view(labels.shape[0], -1) negatives = similarity_matrix[~labels.bool()].view(similarity_matrix.shape[0], -1) logits = torch.cat([positives, negatives], dim=1) labels = torch.zeros(logits.shape[0], dtype=torch.long).to(DEVICE) logits = logits / temp return logits, labels
모든 준비가 완료되었으니 SimCLR을 훈련시키고 효과를 확인해 볼까요!
simclr_model = SimCLR().to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(simclr_model.parameters())
epochs = 10
with tqdm(total=epochs) as pbar:
for epoch in range(epochs):
t0 = time.time()
running_loss = 0.0
for i, views in enumerate(train_dl):
projections = simclr_model([view.to(DEVICE) for view in views])
logits, labels = ntxent_loss(projections, temp=2)
loss = criterion(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print stats
running_loss += loss.item()
if i%10 == 9: # print every 10 mini-batches
print(f"Epoch: {epoch+1} Batch: {i+1} Loss: {(running_loss/100):.4f}")
running_loss = 0.0
pbar.update(1)
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")
위 코드는 10라운드 동안 훈련되었습니다. 사전 훈련 과정을 완료했다고 가정하면 원하는 다운스트림 작업에 사전 훈련된 인코더를 사용할 수 있습니다. 아래 코드를 사용하면 됩니다.
from torchvision.transforms import Resize, CenterCrop
resize = Resize(255)
ccrop = CenterCrop(224)
ttensor = ToTensor()
custom_transform = Compose([
resize,
ccrop,
ttensor,
])
garbage_ds = ImageFolder(
root="/kaggle/input/garbage-classification/garbage_classification/",
transform=custom_transform
)
classes = len(garbage_ds.classes)
BATCH_SZ = 128
train_dl = torch.utils.data.DataLoader(
garbage_ds,
batch_size=BATCH_SZ,
shuffle=True,
drop_last=True,
pin_memory=True,
)
class Identity(nn.Module):
def __init__(self):
super(Identity, self).__init__()
def forward(self, x):
return x
class LinearEvaluation(nn.Module):
def __init__(self, model, classes):
super().__init__()
simclr = model
simclr.linear_eval=True
simclr.projection = Identity()
self.simclr = simclr
for param in self.simclr.parameters():
param.requires_grad = False
self.linear = nn.Linear(512, classes)
def forward(self, x):
encoding = self.simclr(x)
pred = self.linear(encoding)
return pred
eval_model = LinearEvaluation(simclr_model, classes).to(DEVICE)
criterion = nn.CrossEntropyLoss().to(DEVICE)
optimizer = torch.optim.Adam(eval_model.parameters())
preds, labels = [], []
correct, total = 0, 0
with torch.no_grad():
t0 = time.time()
for img, gt in tqdm(train_dl):
image = img.to(DEVICE)
label = gt.to(DEVICE)
pred = eval_model(image)
_, pred = torch.max(pred.data, 1)
total += label.size(0)
correct += (pred == label).float().sum().item()
print(f"Time taken: {((time.time()-t0)/60):.3f} mins")
print(
"Accuracy of the network on the {} Train images: {} %".format(
total, 100 * correct / total
)
)
위 코드의 주요 부분은 방금 훈련된 simclr 모델을 읽은 다음 모든 가중치를 고정한 다음 분류 헤드 self.linear를 만들어 다운스트림 분류 작업을 수행하는 것입니다
요약
이 문서에서는 SimCLR 프레임워크를 소개하고 이를 사용하여 무작위로 초기화된 가중치로 ResNet18을 사전 훈련합니다. 사전 훈련은 대규모 데이터 세트에서 모델을 훈련하고 다른 작업으로 전송할 수 있는 유용한 기능을 학습하기 위해 딥 러닝에 사용되는 강력한 기술입니다. SimCLR 논문에서는 배치 크기가 클수록 성능이 향상된다고 믿습니다. 우리의 구현에서는 128개의 배치 크기만 사용하고 10개의 에포크 동안만 학습합니다. 따라서 이는 모델의 최고 성능이 아닙니다. 성능 비교가 필요한 경우 추가 교육이 필요합니다.
다음 그림은 논문 저자가 제시한 성과 결론입니다.

위 내용은 Pytorch를 사용하여 자기 지도 사전 학습을 위한 대조 학습 SimCLR 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!