
'위치 임베딩': Transformer의 비밀

- 王林앞으로
- 2023-04-10 10:01:031096검색
Translator | Cui Hao
Reviewer | Sun Shujuan
Contents
- 소개
- Transformers에 위치 삽입에 필요함
- 다양함 초기 시행 및 오류 실험의 유형 주파수 기반 위치 임베딩
- summary references introduction 딥 러닝 분야에서 변압기 아키텍처의 도입은 의심 할 여지없이 침묵합니다. 혁명은 특히 NLP 분야에 길을 열었습니다. Transformer 아키텍처에서 가장 필수적인 부분은 신경망에 긴 문장의 단어 순서와 단어 간의 종속성을 이해할 수 있는 기능을 제공하는 "위치 임베딩"입니다. Transformer 이전에 소개된 RNN과 LSTM은 위치 임베딩을 사용하지 않고도 단어의 순서를 이해할 수 있는 능력이 있다는 것을 알고 있습니다. 그러면 왜 이 개념이 Transformer에 도입되었고 이 개념의 장점이 그렇게 강조되는지에 대한 명확한 질문이 생길 것입니다. 이 기사에서는 이러한 원인과 결과를 설명합니다.
- NLP의 임베딩 개념
- 임베딩은 원시 텍스트를 수학적 벡터로 변환하는 데 사용되는 자연어 처리 프로세스입니다. 머신러닝 모델이 텍스트 형식을 직접 처리하고 다양한 내부 컴퓨팅 프로세스에 사용할 수 없기 때문입니다.
Word2vec 및 Glove와 같은 알고리즘의 임베딩 프로세스를 워드 임베딩 또는 정적 임베딩이라고 합니다.
이런 방식으로 많은 단어가 포함된 텍스트 코퍼스를 훈련용 모델에 전달할 수 있습니다. 모델은 더 자주 나타나는 단어가 유사하다고 가정하여 각 단어에 해당하는 수학적 값을 할당합니다. 이 프로세스 후에 결과 수학적 값은 추가 계산에 사용됩니다.
예를 들어, 텍스트 코퍼스에는 다음과 같은 3개의 문장이 있다고 가정해 보세요.
영국 정부는 행정부에 대한 어느 정도 통제권을 주장하면서 매년 팔레르모의 왕과 여왕에게 막대한 보조금을 지급합니다.
왕과 왕비 외에도 왕실 가족에는 딸 마리-테레사 샬롯(마담 로얄), 왕의 누이 엘리자베스, 발레단 클라리 등이 포함됩니다.
이것은 모드레드의 배신 소식으로 중단되었고, 랜슬롯은 마지막 치명적인 갈등에 관여하지 않았으며 왕과 왕비, 그리고 원탁의 몰락에서 살아남았습니다.
여기서
"King"과 "Queen"이라는 단어가 자주 등장하는 것을 볼 수 있습니다. 따라서 모델은 이러한 단어 간에 유사성이 있을 수 있다고 가정합니다. 이 단어- 가 수학적 값으로 변환되면 다차원 공간에서 표현될 때 작은 거리에 배치됩니다.
- 이미지 출처: Illustrations powered by theauthor
- 다른 단어 "road"가 있다고 가정하면 논리적으로 이 단어는 큰 텍스트 코퍼스에서 "king" 및 "queen"만큼 자주 나타나지 않습니다. . 그러므로 그 단어는 '왕'과 '여왕'과는 거리가 멀고, 우주의 다른 어딘가에 멀리 위치하게 될 것이다.
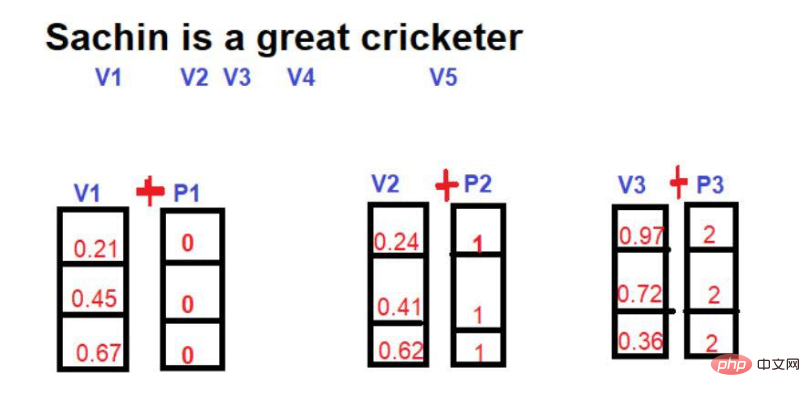
이미지 출처: 일러스트레이션 제공: 저자수학에서 벡터는 일련의 숫자로 표현되며, 각 숫자는 특정 차원에서 단어의 크기를 나타냅니다. 예를 들어 여기에
를 넣었습니다. 따라서 "왕"은 3차원 공간에서 [0.21, 0.45, 0.67]의 형태로 표현됩니다.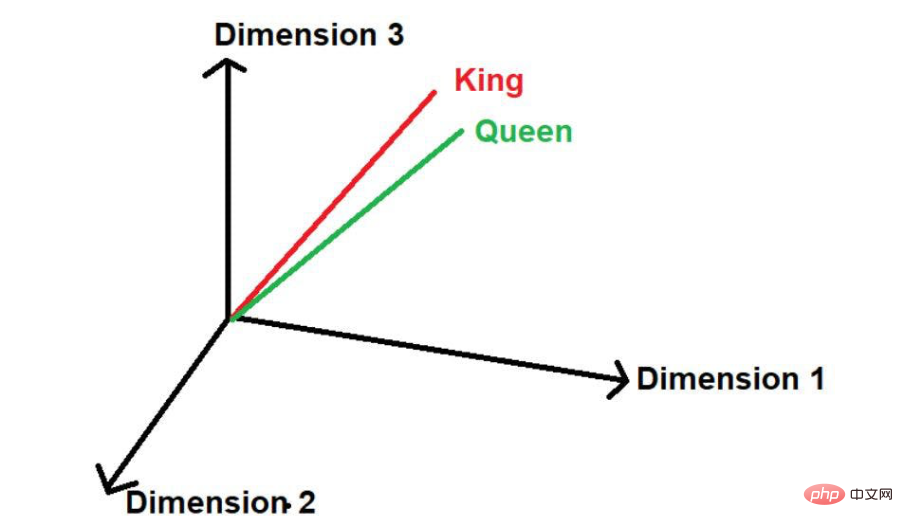 "Queen"이라는 단어는 [0.24,0.41,0.62]로 표현할 수 있습니다.
"Queen"이라는 단어는 [0.24,0.41,0.62]로 표현할 수 있습니다.
'도로'라는 단어는 [0.97,0.72,0.36]으로 표현할 수 있습니다. Transformer에서 위치 임베딩이 필요합니다
소개 섹션에서 논의한 것처럼 위치 임베딩의 필요성은 신경망이 문장의 순서와 위치 종속성을 이해하는 것입니다.
예를 들어 다음 문장을 고려해 보겠습니다. 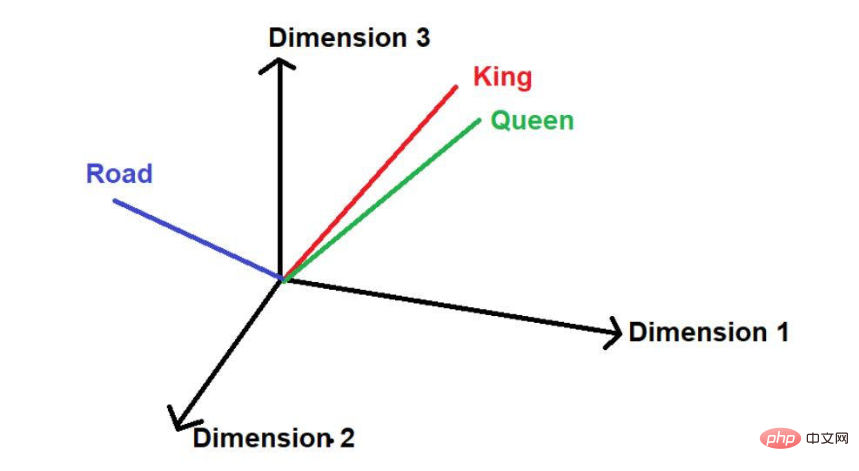
따라서 NLP 프로젝트에서는 위치 정보를 이해하는 것이 매우 중요합니다. 모델이 단순히 다차원 공간에서 숫자를 사용하고 맥락을 잘못 이해하는 경우 이는 특히 예측 모델에서 심각한 결과를 초래할 수 있습니다.
이 문제를 극복하기 위해 RNN(Recurrent Neural Network) 및 LSTM(Long Term Short Term Memory)과 같은 신경망 아키텍처가 도입되었습니다. 어느 정도 이러한 아키텍처는 위치 정보를 이해하는 데 매우 성공적입니다. 그들의 성공 비결은 단어의 순서를 유지하면서 긴 문장을 학습하는 것입니다. 이 외에도 '관심 단어'에 가까운 단어와 '관심 단어'와는 거리가 먼 단어에 대한 정보도 갖고 있다.
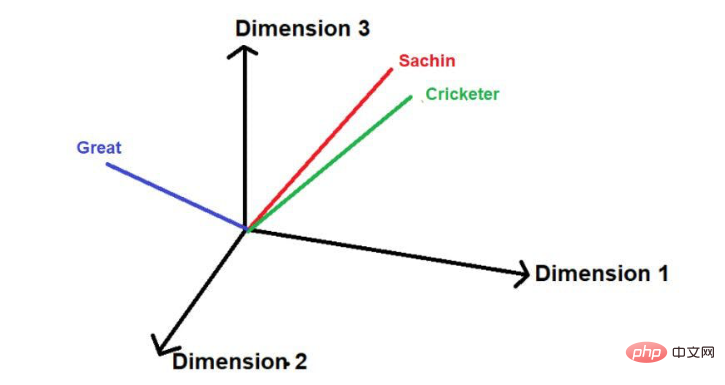
예를 들어 다음 문장을 생각해 보세요.
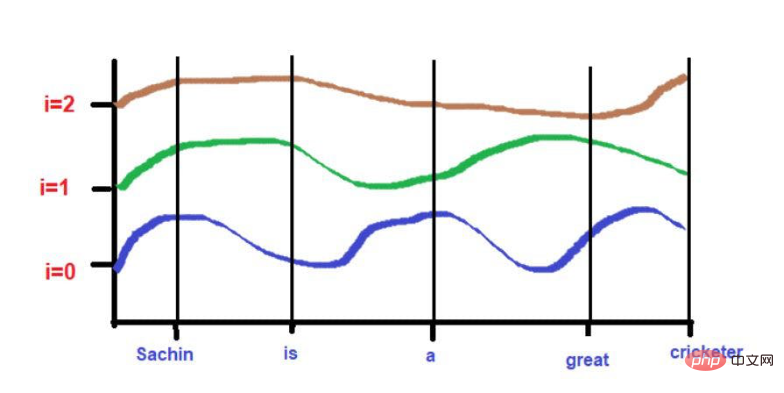
"Sachin은 역대 최고의 크리켓 선수입니다."

이미지 출처 : 일러스트 제공 작가
빨간색 밑줄 친 단어가 바로 이겁니다. 여기서는 "관심 단어"가 원문의 순서대로 순회되는 것을 볼 수 있습니다.
게다가

이미지 출처: Illustrations powered by theauthor
그러나 RNN/LSTM은 이러한 기법을 통해 큰 텍스트 말뭉치의 위치 정보도 이해할 수 있습니다. 그러나 실제 문제는 대규모 텍스트 모음에서 단어를 순차적으로 탐색하는 것입니다. 100만 단어로 구성된 매우 큰 텍스트 코퍼스가 있고 각 단어를 순서대로 처리하는 데 매우 오랜 시간이 걸린다고 상상해 보세요. 때로는 모델 교육에 너무 많은 계산 시간을 투자하는 것이 불가능할 때도 있습니다.
이 문제를 극복하기 위해 새로운 고급 아키텍처인 "Transformer"가 도입되었습니다.
Transformer 아키텍처의 중요한 특징은 모든 단어를 병렬로 처리하여 텍스트 코퍼스를 학습할 수 있다는 것입니다. 텍스트 코퍼스에 10단어가 포함되어 있든, 100만 단어가 포함되어 있든 Transformer 아키텍처는 상관하지 않습니다.

이미지 출처: 일러스트 제공 작가

이미지 출처: 일러스트 제공 작가
이제 우리는 단어를 병렬로 처리하는 문제에 직면해야 합니다. 모든 단어가 동시에 액세스되므로 단어 간의 종속성에 대한 정보가 손실됩니다. 따라서 모델은 특정 단어의 연관 정보를 기억하지 못하고 정확하게 저장할 수 없습니다. 이 질문은 모델 계산/훈련 시간을 크게 줄임에도 불구하고 상황별 종속성을 보존해야 하는 원래의 과제로 다시 이어집니다.
그러면 위의 문제를 어떻게 해결할 수 있을까요? 해결책은
지속적인 시행착오
입니다. 처음에 이 개념이 도입되었을 때 연구자들은 Transformer 구조에서 위치 정보를 보존할 수 있는 최적화된 방법을 고안하기 위해 매우 열심이었습니다. 시행착오 실험의 일환으로 시도한 첫 번째 방법은
여기서 아이디어는 단어의 인덱스가 포함된 단어 벡터를 사용하면서 새로운 수학적 벡터를 도입하는 것입니다.
이미지 출처: 작가 제공 일러스트레이션
다음 그림은 다차원 공간의 단어 표현이라고 가정
이미지 출처: 작가 제공 일러스트레이션
위치 추가 후 벡터의 크기와 방향은 아래와 같이 각 단어의 위치가 변경될 수 있습니다.
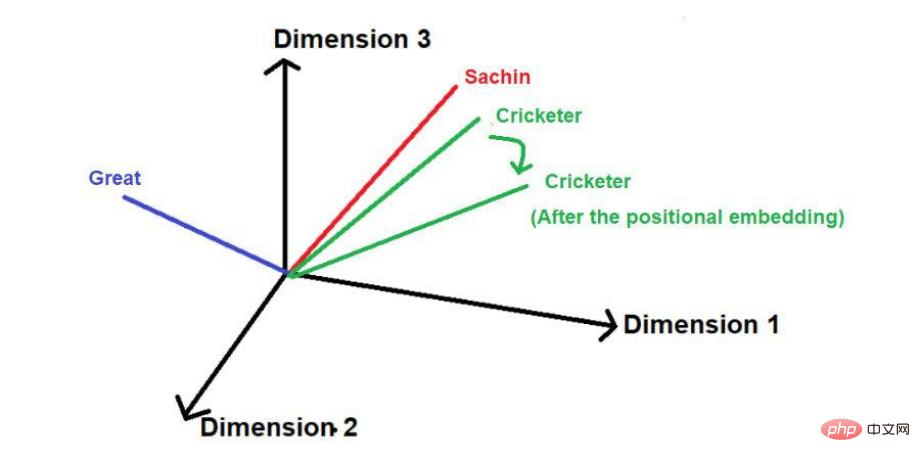
이미지 출처: 일러스트 제공 작가
이 기술의 단점은 문장이 특히 길면 비례하여 위치 벡터가 증가한다는 것입니다. 문장에 25개의 단어가 있다고 가정하면 첫 번째 단어에는 크기 0이 추가된 위치 벡터가 있고 마지막 단어에는 크기 24가 추가된 위치 벡터가 있습니다. 이러한 엄청난 불확실성은 이러한 값을 더 높은 차원에 투영할 때 문제를 일으킬 수 있습니다.
위치 벡터를 줄이는 데 사용되는 또 다른 기술은
여기서 문장 길이에 대한 각 단어의 분수 값을 위치 벡터의 크기로 계산합니다.
점수 값 계산 공식은
Value=1/N-1
이며, 여기서 "N"은 특정 단어의 위치입니다.
예를 들어 아래 예를 살펴보겠습니다. -
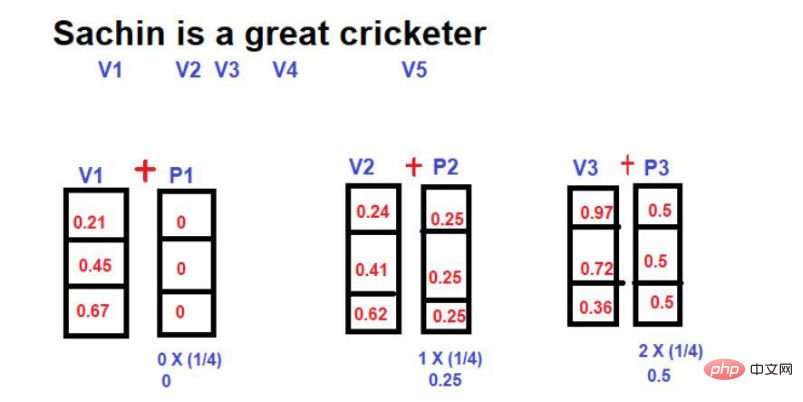
이미지 출처: Illustration 제공: 작성자
이 기술에서는 위치 벡터의 최대 크기를 문장 길이에 관계없이 1로 제한할 수 있습니다. 그러나 큰 허점이 있습니다. 길이가 다른 두 문장을 비교하면 특정 위치에 있는 단어의 임베딩 값이 달라집니다. 특정 단어나 해당 위치는 해당 문맥을 쉽게 이해할 수 있도록 텍스트 코퍼스 전체에서 동일한 임베딩 값을 가져야 합니다. 서로 다른 문장의 동일한 단어가 서로 다른 임베딩 값을 갖는 경우 다차원 공간에서 텍스트 코퍼스 정보를 표현하는 것은 매우 복잡한 작업이 됩니다. 이처럼 복잡한 공간을 구현하더라도 과도한 정보 왜곡으로 인해 어느 시점에서는 모델이 붕괴될 가능성이 매우 높다. 따라서 이 기술은 Transformer 위치 임베딩 개발에서 제외되었습니다.
마지막으로 연구원들은 Transformer 아키텍처를 제안하고 유명한 백서 "Attention is all you need"에서 언급했습니다. ... "는 문장에서 특정 단어의 위치 또는 인덱스 값입니다.
"d"는 문장에서 특정 단어를 나타내는 벡터의 최대 길이/치수입니다.
"i"는 각 위치의 임베딩 차원 인덱스를 나타냅니다. 빈도를 의미하기도 합니다. i=0일 때 가장 높은 주파수로 간주되며, 후속 값의 경우 주파수는 크기가 감소하는 것으로 간주됩니다.
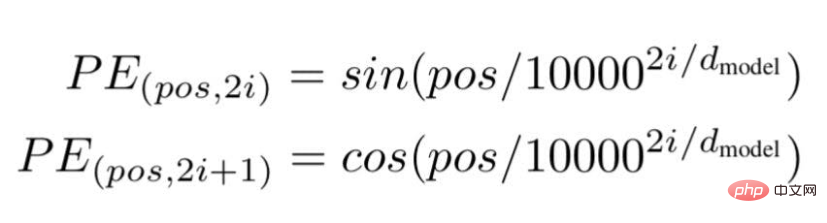
이미지 출처: 작가 제공 일러스트
이미지 출처: 일러스트 제공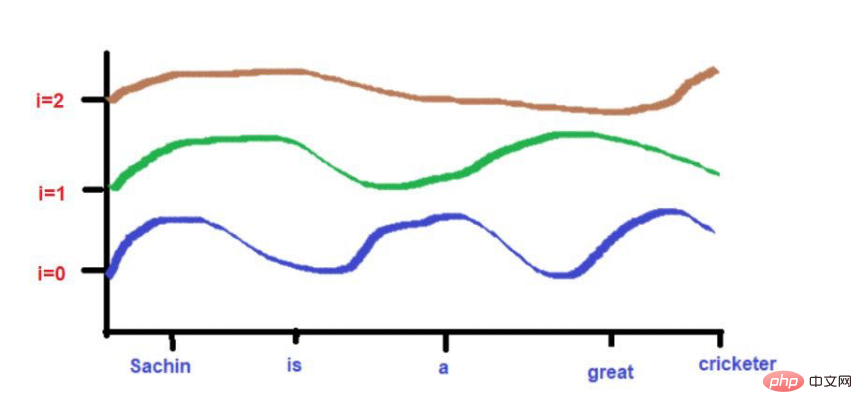
 예제 텍스트를 기반으로 합니다. "Sachin은 훌륭한 크리켓 선수입니다."
예제 텍스트를 기반으로 합니다. "Sachin은 훌륭한 크리켓 선수입니다."
For
pos = 0 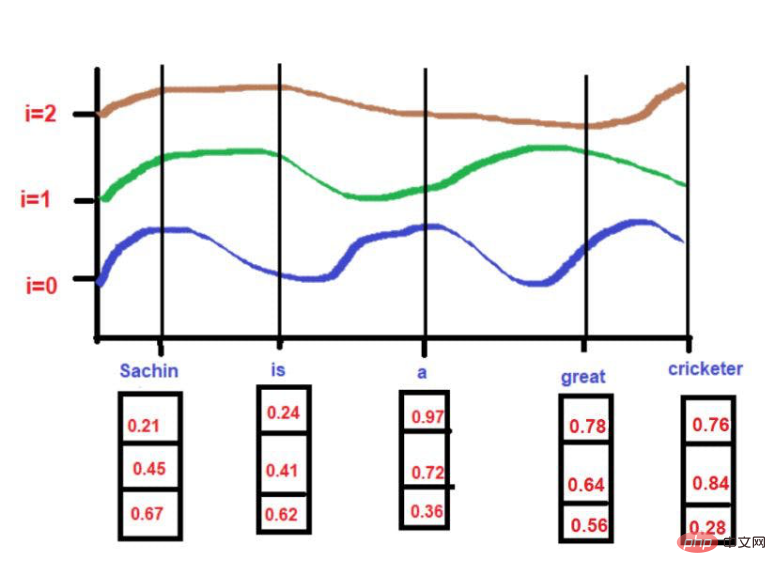
이미지 출처: 작가 제공 일러스트
i =0일 때,
PE(0,0) = sin(0/10000^2(0)/3)
PE(0,0) = sin(0)
PE(0,0) = 0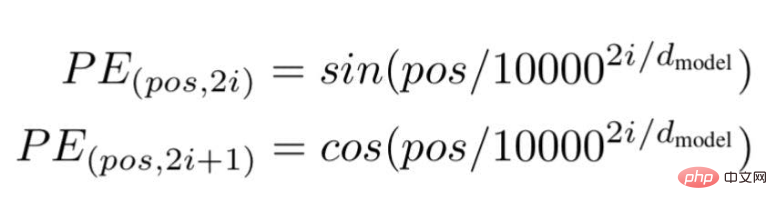
이미지 출처: 작가 제공 일러스트
i =0일 때,
PE(3,0) = sin(3/10000^2(0)/3)
PE(3,0) = sin(3/1)
PE(3,0) = 0.05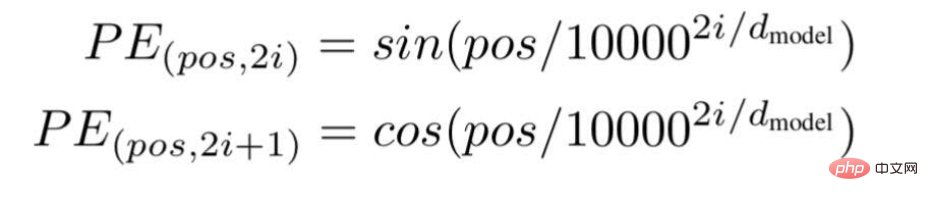
PE(3,2) = sin(3/1.4)PE(3,2) = 0.03
이미지 출처 : 일러스트 제공 작가
여기서 최대값은 1로 제한됩니다. (sin/cos 함수를 사용하고 있기 때문입니다.) 따라서 이전 기술에서는 크기가 큰 위치 벡터에 문제가 없습니다.
또한 서로 매우 가까운 단어는 낮은 빈도에서는 비슷한 높이에 떨어질 수 있지만 높은 빈도에서는 높이가 약간 다를 수 있습니다.
단어가 서로 매우 가까우면 낮은 주파수에서도 높이가 매우 다르며 빈도에 따라 높이 차이도 커집니다.
예를 들어, "왕과 왕비가 길을 걷고 있었다"라는 문장을 생각해 보세요.
'King'과 'Road'라는 단어가 더 멀리 배치되었습니다.
파동주파수 공식을 적용한 것을 고려하면 두 단어의 높이가 대략 비슷합니다. 더 높은 주파수(예: 0)에 도달하면 높이가 더욱 달라집니다.
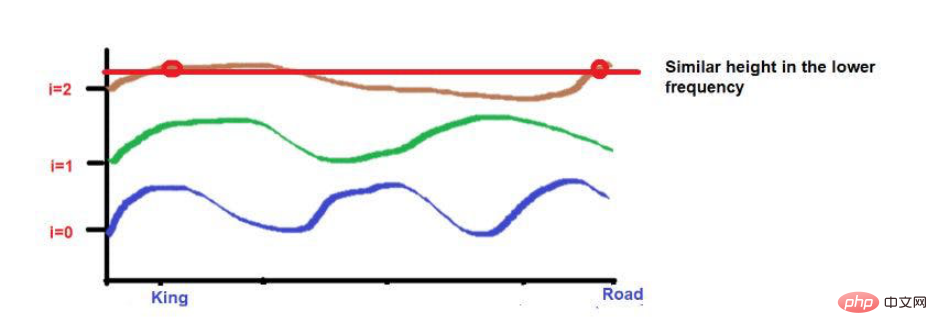
사진 출처 : 작가 제공 일러스트
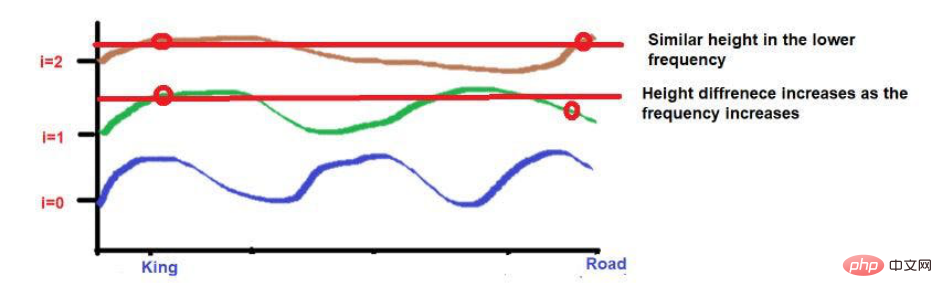
사진 출처 : 작가 제공 일러스트
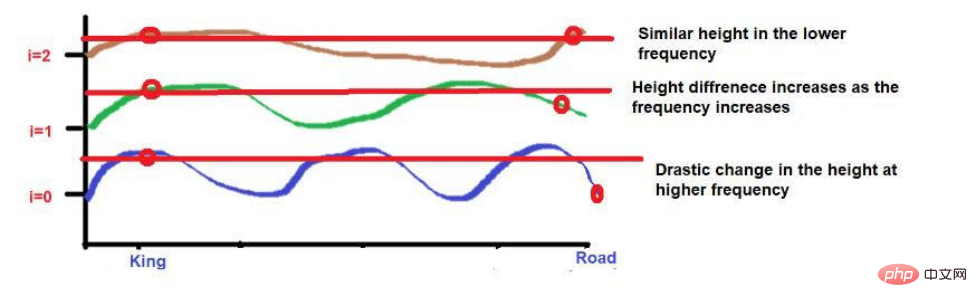
사진 출처 : 작가 제공 일러스트
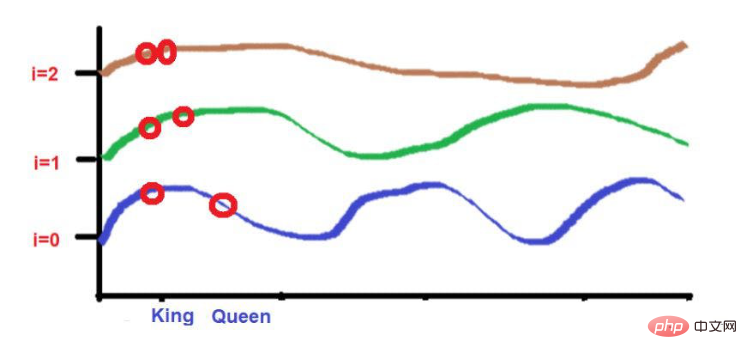
그리고 "King"과 " 퀸'을 더 가까이 배치하세요.
이 2개의 단어는 더 낮은 빈도에서 비슷한 높이에 배치됩니다(여기서는 2와 같습니다). 더 높은 주파수(예: 0)에 도달하면 높이 차이가 약간 증가하여 구별할 수 있습니다.
이미지 출처: 일러스트 제공 작가
그러나 우리가 주목해야 할 점은 이 단어들의 근접도가 낮으면 고주파수로 발전할 때 높이가 매우 달라진다는 것입니다. 단어가 서로 매우 가까우면 더 높은 주파수로 이동할 때 높이에 약간의 차이만 있을 것입니다.
요약
이 글을 통해 머신러닝의 위치 임베딩 이면에 숨어 있는 복잡한 수학적 계산을 직관적으로 이해하시길 바랍니다. 간단히 말해서, 우리는 특정 목표를 달성해야 할 필요성에 대해 논의했습니다.
"자연어 처리"에 관심이 있는 기술 애호가들에게 이 내용은 복잡한 컴퓨팅 방법을 이해하는 데 도움이 된다고 생각합니다. 자세한 내용은 유명한 연구 논문인 "Attention is All You Need"를 참조하세요.
번역가 소개
Cui Hao, 51CTO 커뮤니티 편집자, 선임 설계자는 18년의 소프트웨어 개발 및 아키텍처 경험과 10년의 분산 아키텍처 경험을 보유하고 있습니다.
원제: 위치 임베딩: 변환기 신경망의 정확성 뒤에 숨겨진 비밀, 저자: Sanjay Kumar
위 내용은 '위치 임베딩': Transformer의 비밀의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!