
Xishanju AI 기술 전문가 Huang Hongbo: 강화 학습과 행동 트리를 게임에 실질적으로 통합

- 王林앞으로
- 2023-04-09 14:31:091927검색
2022년 8월 6~7일,AISummit 글로벌 인공지능 기술 컨퍼런스가 예정대로 개최됩니다. 지난 7일 오후 열린 '인공지능 프론티어 탐구' 서브 포럼에서 시산주의 AI 기술 전문가 황홍보(Huang Hongbo)는 '게임에서 강화학습과 행동트리의 실제적 결합'이라는 주제를 공유하며, 이에 대해 자세히 공유했다. 강화학습이 게임 분야에 미치는 영향.
황홍보는 강화학습 기술의 구현은 알고리즘을 개선하는 데 있는 것이 아니라 강화학습 기술을 딥러닝 및 게임 기획과 결합하여 완전한 솔루션을 구성하고 구현하는 데 있다고 말했습니다.
강화 학습은 게임을 더 스마트하게 만듭니다
게임에 강화 학습을 구현하면 게임을 더 스마트하고 플레이하기 쉽게 만들 수 있습니다. 이것이 게임에서 강화 학습을 사용하는 주요 목적입니다.
"강화 학습은 일련의 결정을 내릴 수 있도록 에이전트의 전략을 훈련하는 기계 학습 패러다임입니다." 황홍보는 에이전트의 목적이 환경 관찰을 기반으로 행동을 출력하는 것이라고 말했습니다. 이러한 행동은 더 많은 관찰과 보상으로 이어질 것입니다. 훈련에는 에이전트가 환경과 상호작용하면서 많은 시행착오가 수반되며 정책은 반복될 때마다 개선될 수 있습니다.
게임에서 행동을 취하거나 행위를 수행하는 에이전트가 게임 에이전트입니다. 게임 속의 캐릭터나 로봇을 생각해 보면 게임의 상태, 플레이어가 있는 위치를 이해해야 하며, 이러한 관찰을 바탕으로 게임의 상황에 따라 결정을 내려야 합니다. 강화 학습에서 의사결정은 보상에 의해 이루어지며, 보상은 게임에서 높은 점수로 제공되거나 특정 목표를 달성하기 위해 새로운 레벨에 도달할 때 제공될 수 있습니다.
황홍보는 게임 상황에서 가장 멋진 점은 게임의 압박 속에서 에이전트의 전략이 훈련된다는 점이라고 말했습니다. 예를 들어, 공격을 처리하는 방법이나 특정 목표를 달성하기 위해 행동하는 방법을 배울 수 있습니다.
게임에서 행동 트리의 역할
행동 트리는 논리 노드와 행동 노드를 포함하는 트리 구조입니다. 일반적으로 각 상황을 노드 유형으로 추상화하고 사양에 따라 노드를 작성한 다음 이러한 노드를 트리로 연결할 수 있습니다. 사용자가 동작을 찾을 때마다 트리의 루트 노드에서 시작하여 각 노드의 현재 데이터와 일치하는 동작을 찾습니다.
간단히 말해서, 각 AI 모듈의 결합도가 높고 세분성이 큰 경우 변경 사항에 많은 수정이 필요한 경우가 많으며, 대량의 중복 코드가 나타나기 쉽습니다. 행동 트리의 출현은 게임 개발자에게 "정방형 노트북"을 제공하여 AI 개발자가 재사용 가능하고 확장 및 유지 관리가 쉬운 AI 프레임워크 세트를 보다 편리하게 구축할 수 있도록 했습니다. 강화학습은 훈련을 통해 이루어진다고 할 수 있고, 행동트리는 여러 else문과 if문을 조합한 것이라고 할 수 있습니다.
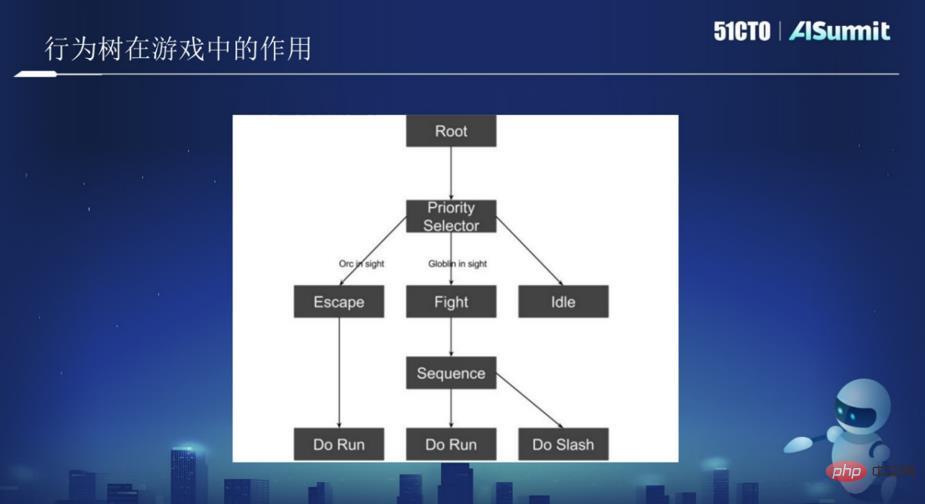
위 그림과 같이 그림에는 루트 노드가 있고, 아래에는 트리 노드가 있습니다. 트리 노드에는 탈출, 공격, 방황 등이 있습니다. 위의 그림을 AI나 로봇으로 생각하고 정글을 순찰하게 해보세요. AI가 ORC 오크를 보고 ORC를 물리칠 수 없다고 판단한 경우, 이 조건이 발동되면 AI는 도망가며 탈출 시 Run 액션을 실행하게 됩니다. 전투가 더 쉽다고 판단되면 전투 작전을 수행하게 됩니다.
위 그림에는 두 개의 노드가 있습니다. 하나는 루트 노드인 루트이고 다른 하나는 논리 노드인 선택기 노드입니다. 모든 노드는 왼쪽에서 오른쪽으로 특정 순서로 실행됩니다. 따라서 AI가 일부 관련 작업을 수행할 수 있도록 각 노드에 해당 로직을 작성하기만 하면 됩니다. 여러 행동 트리가 마침내 게임을 형성합니다.
강화 학습과 행동 트리의 조합으로 게임이 더욱 풍부해집니다
강화 학습과 행동 트리의 조합을 사용하여 게임을 더욱 풍부하게 만드는 방법은 무엇인가요? 이것은 많은 게임에서 논의되어야 할 어려운 응용 프로그램입니다.
그 전에 언제 강화 학습을 사용하는 것이 더 좋은지, 어떤 상황에서 행동 트리를 사용하는 것이 더 좋은지에 대해 논의해 보겠습니다. 황홍보는 행동 트리를 이용해 목표를 달성할 방법이 없다면 강화학습을 활용할 수 있다고 말했다. 예를 들어 FPS(1인칭 슈팅 게임)에서는 화력을 얼마나 써야 하는지, 누구에게 발사해야 하는지, 어떤 종류로 쏘아야 하는지 등이다. 무기 등을 사용해야 합니다. 행동 트리를 통해 결정을 내리는 것이 더 어렵습니다. 일반적으로 강화 학습을 사용하는 것이 좋습니다.
언제 행동 트리를 사용하나요? 예를 들어, 게임에서 장애물을 만나 뛰어넘어야 하는 경우 강화 학습을 사용하거나 행동 트리를 사용하도록 선택할 수 있습니다. 하지만 강화 학습을 사용하여 이를 수행한다면 훈련은 매우 번거로울 것입니다. 이 상황에서는 건너뛰는 옵션이 하나뿐이므로 행동 트리를 사용하는 것이 더 간단합니다.
강화 학습과 행동 트리를 결합하여 게임에 사용하면 더 나은 솔루션이라는 것을 찾는 것은 어렵지 않습니다. Huang Hongbo는 강화 학습과 행동 트리를 결합하는 비교적 큰 두 가지 구현 방법이 있다고 말했습니다. 하나는 강화 학습을 기반으로 하고 행동 트리로 보완되는 것이고, 다른 하나는 행동 트리를 기반으로 하고 강화 학습으로 보완되는 것입니다.
행동 트리 측면: 행동 트리를 주요 AI 이동 방법으로 사용하여 행동 트리는 게임 클라이언트로부터 obs 입력을 받고 행동 트리의 각 행동에서 자체 대상 상황에 따라 obs에 해당하는 행동 트리 동작을 작성합니다. , 결정을 내리기 위해 강화 학습이 필요한 일부 노드는 강화 학습으로 넘겨집니다. 그런 다음 여기에서는 일부 특정 시나리오에 대한 해당 훈련을 수행하기 위해 강화 학습이 필요합니다.
강화 학습 측면: 전체 전략은 여러 모델을 훈련하는 것이며, 각 모델은 전략을 실행한 다음 이를 행동 트리에 포함시킵니다.
황홍보는 이 두 가지 구현 방법 중 어느 것이 더 나은지 다양한 상황, 다양한 애플리케이션, 다양한 게임에 따라 서로 다른 고려 사항이 필요하므로 일반화할 수 없다고 말했습니다.
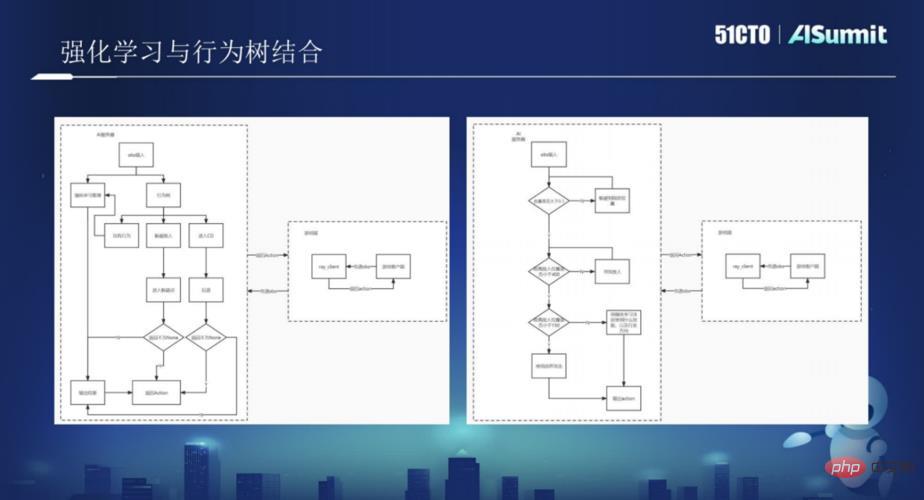
다음 시간에는 Huang Hongbo가 Xishanju에서 강화 학습과 행동 트리에 채택한 기술 프레임워크를 자세히 소개하고 수많은 게임 사례와 결합하여 행동 트리와 강화 학습이 어떻게 사용되는지 자세히 소개했습니다. 게임을 결합하여 게임을 더욱 풍부하게 만드세요. 사례 실습에 관심이 있는 사용자는 AISummit 글로벌 인공지능 기술 컨퍼런스의 멋진 공유 영상에 주목해 보세요. (https://www.php.cn/link/53253027fef2ab5162a602f2acfed431)
위 내용은 Xishanju AI 기술 전문가 Huang Hongbo: 강화 학습과 행동 트리를 게임에 실질적으로 통합의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!