
Volcano Voice의 최신 초자연적 대화 음성 합성 기술을 사용하여 데이터 양의 1/4만 사용하여 실제 음성의 100% 세부 사항을 복원합니다!

- PHPz앞으로
- 2023-04-08 15:21:101662검색
별을 헤아리고 달을 바라며 6년 동안 기다려온 수천 명의 Jay 팬들이 얼마 전, 드디어 주걸륜이 새 앨범을 발매했습니다! 온라인에 공개되자 인터넷 전반에 걸쳐 토론이 촉발되었습니다.
모두가 그 무성했던 시절의 아름다운 추억에 잠겨 있는 동안, 바이럴 오디오를 게시한 친구는 다음과 같이 말했습니다. 이 대화는 실제로 음성 합성이었습니다!
"음성 합성"에 관해 다음과 같은 생각이 떠오를 수 있습니다.
• "앞서 교차로에서 좌회전" 톤
• 전화를 받을 때 , 상대방이 "안녕하세요 xx신용카드센터입니다"라고 서투르게 감정을 표현했는데, 이 남자 이름은 샤오슈아이입니다…이제 음성합성 기술은 이미 많은 사람들의 고정관념을 직접적으로 뒤집었습니다. 위의 오디오와 동일하게 완벽하고 자연스러운 효과입니다. 이 오디오의 게시자 -
Volcano Voice, ByteDanceAI Lab Speech & Audio 지능형 음성 및 오디오 팀
은 대중에게 콘텐츠를 더 잘 해독하기 위해 두 가지 오디오를 사용했습니다. . 이 문장의 입력 텍스트는 정확히 동일합니다. 즉, "남부 요리는 디핑 소스를 선호합니다. 예를 들어 저는 상하이에서 처음으로 바베큐에 야채도 디핑 소스와 함께 제공되어야 한다는 것을 배웠습니다. ." 그러나 합성된 오디오 효과는 분명히 다릅니다. 즉, 두 번째 오디오는 이번에 Volcano Voice Team이 출시한 새로운 초자연적 대화 음성 합성 기술에서 나온 것입니다. 사람들의 일상적인 표현 상태를 기억해 보세요. 뇌는 정보를 처리하는 데 사고 시간이 필요합니다. 언어에 있어서 사람들은 자신도 모르게 머뭇거리고, 발음하고, 도치하고, 심지어 문장 중간에 단어를 바꾸고, 말을 더듬고, 반복하기도 합니다. 또한 표현하려는 핵심 정보를 강조하기 위해 의도적으로 발음을 강조하기도 합니다. 이로 인해 관찰하기 어려운 미묘한 표현이 많이 발생합니다. 이러한 현상은 기존 TTS에서는 포착하고 복원하기가 어렵습니다. 이러한 미묘함을 완벽하게 재현하는 것이 소리의 진위 여부를 구별하기 어렵게 만드는 미스터리의 원천이자, 위에서 언급한 오디오의 미스터리이기도 하다.
구체적으로볼케이노 보이스팀에서 선보이는 최신 초자연적 대화 음성 합성 기술
은 기존 TTS보다 더 현실적이고 자연스럽습니다. 발음 연장 기능이 완벽하게 통합되어기존 사운드 라이브러리의 1/4의 데이터만으로 실제 사람이 말하는 미묘한 리듬 특성과 발음 습관을 완벽하게 복원하여 합성 효과를 더욱 현실감 있게 만들어줍니다. 전문적인 평가 결과, Huoshan Voice의 신기술은 기본적으로 실제 녹음과 차이가 없으며, 리뷰어가 이를 구별하기 어려운 것으로 나타났습니다. 또한 이 기술은 비디오 더빙, 전화 고객 서비스 등 다양한 시나리오에 활용되고 있으며 가까운 시일 내에 Volcano Engine Voice Technology 공식 웹사이트에 출시될 예정입니다.
대체 어떻게 이런 강력한 기술이 탄생한 걸까요? 위에서 언급한 헐떡거림, 삼키기, 생각할 때 단어 발음의 무의식적인 연장, 실제 의사소통에서 자주 발생하는 낮은 웃음 등의 증상을 파라언어 현상(paralangicia)
이라고 부른다고 합니다. 그러나 전통적인 음성 합성 기술 프레임워크는 희박하게 분산된 준언어적 현상을 효과적으로 모델링할 수 없기 때문에 말할 때 운율 복원 성능이 제한적이고 너무 "정확"합니다.위의 어려움을 바탕으로 Huoshan Voice의 초자연적인 음성 합성 기술은 텍스트
및음성 모델링의 두 가지 수준에서 획기적인 발전을 이루었습니다. 특히
•텍스트 수준에서 Huoshan Voice는 The 생성 스타일 전송 모델은 실제 사람들이 말하는 방식을 모방하고 텍스트의 제어 가능한 구어체 전사를 수행하여 텍스트가 구어체를 더 잘 수용하고 최종 효과가 너무 많이 쓰여지는 것을 방지할 수 있습니다. 음성 수준에서 팀은 모델의 혁신을 분석하고 TTS의 입력 측에 추가 언어 예측을 추가하여 사람의 발음 특성을 모방하여 자연스러운 자발적인 음성 효과를 얻습니다. 팀이 비지도 기능을 갖춘 TTS 모델링 솔루션을 사용하여 모델의 안정성과 표현력을 효과적으로 향상했다는 점은 언급할 가치가 있습니다. 기존 사운드 라이브러리의 변화하는 리듬 효과가 훌륭하죠? 텍스트는 음성 합성 기술의 입력입니다. 스타일이 실제 사람의 표현에 가까운지 여부입니다. 그러나 뿌리 깊은 글쓰기 습관으로 인해 대부분의 사전 합성된 텍스트는 충분히 자연스럽지 않거나 많은 노력과 지속적인 조정이 필요하므로 시간이 많이 걸리고 노동 집약적입니다. . 이러한 문제를 해결하기 위해 Huoshan Voice 팀은 2단계 솔루션을 채택하여 좋은 결과를 얻었습니다. • 1단계: 자기 지도 방법 사용, 의사 데이터를 사용하여 구어 사전 훈련 모델, 감소 데이터 볼륨에 대한 수요가 감소되는 동시에 포인터 네트워크 구조가 모델에 도입되어 텍스트 제어 가능성이 향상됩니다. • 2단계: 소량의 고품질 수동 주석 데이터를 사용하여 사전 훈련된 구어체 모델을 미세 조정하고 최종적으로 제어 가능하고 자연스러운 구어체 텍스트 효과를 얻습니다. 원본 텍스트 자동 예측 텍스트 남부 요리는 디핑 소스를 선호합니다. 저는 상하이에서 처음으로 바베큐에 야채도 디핑 소스와 함께 제공되어야 한다는 것을 배웠습니다 글쎄, 남부 요리 그렇다면 저는 정말 디핑 소스를 선호합니다 등등 , 예를 들어 처음 어, 처음 상하이에 갔는데, 이 바베큐에 야채도 들어 있다는 걸 깨달았어요 디핑소스도 곁들여야해요 양배추 사러 거리에 나갈 때처럼 남부 사람들은 양배추 반을 원한다고 하고 북부 사람들은 양배추 반 카트를 원한다고 뭐, 이건 양배추 사러 나갈 때 랑 비슷해요, 남부 사람들은 양배추 반을 원한다고 하고, 북부 사람들은 반을 원한다고 합니다. 양배추 사실 남도요리는 양념의 맛을 더 중시하는데, 즉 셰프가 조미료를 사용하여 솜씨를 뽐낸다는 것입니다 네, 사실 남도요리는 더 중시합니다 양념의 맛에 대해, 즉, 셰프가 양념을 활용해 솜씨를 뽐낸다는 것 실제 인물을 더 잘 복원하기 위해 Huoshan Voice는 파라언어 모델링과 운율 다양성을 가지고 있습니다. 도 심도있게 연구되었습니다. 준언어 모델링 측면에서, 팀이 도입한 합성 기술은 자연스러운 표현에서 나타나는 흡입, 웃음, 머뭇거림, 교정 등 다양한 준언어 현상을 음향 모델에서 모델링하고 이를 텍스트의 의미 정보와 결합할 수 있도록 한다. 준언어 현상을 자동으로 삽입하려면 . 삽입 과정에서 합리성과 무작위성을 모두 고려하면 퍼포먼스가 더욱 자연스럽고 현실감 있게 표현됩니다.
숨을 들이마시는 >은 실제로 몸에 아주 좋습니다. C.wav Extension>저는 기본적으로 아침을 잘 안 먹어요. D.wav Katon>두유와 튀김 반죽 스틱 빵입니다. 미끄러짐 교정 ParalangTest_is_000008_npy_01_new2.wav 사본 Huoshan Voice, ByteDance AI Lab 음성 및 오디오 지능형 음성 및 오디오 팀은 오랫동안 Douyin, Jianying, Tomato Novels, Feishu 및 기타 비즈니스 솔루션에 선도적인 AI 음성 기술 기능과 풀 스택 음성 제품을 제공해 왔습니다. Volcano Engine을 통해 외부 기업에 기술 서비스를 제공합니다. 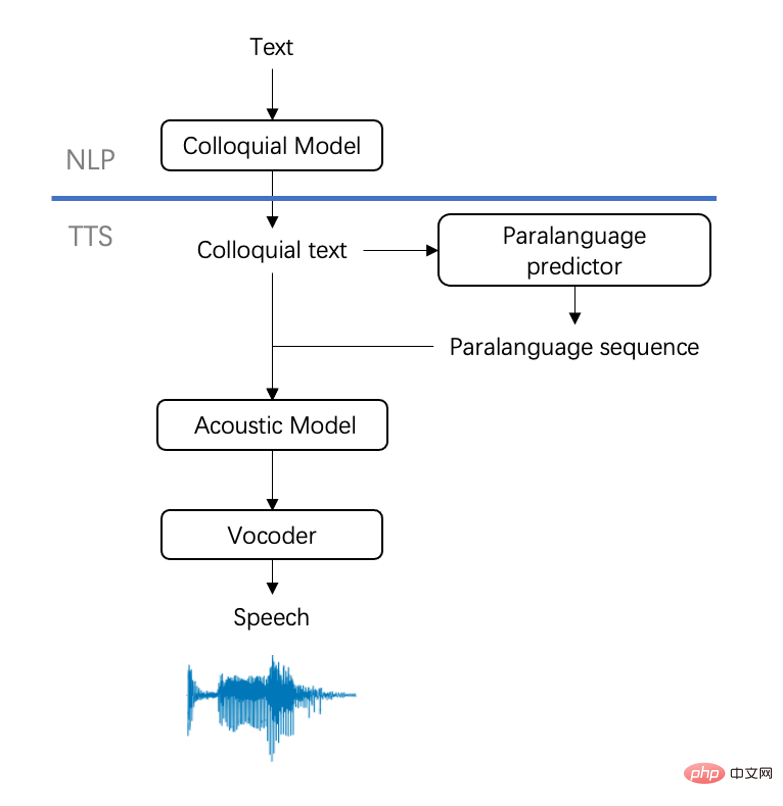
종이에 "실제 사람의 표현"을 생생하게 만들기 위해 텍스트 구어체에 전념
파라언어 모델링 + 운율 다양성이 놀랍습니다. 음성 사실성이 완전히 업그레이드되었습니다.
text
Supernatural
이런 느낌
아침에 우리 지금 뭐하는지 보세요
기본적으로 우리의 아침을 좋아해요
고기 정말 먹고 싶어요.
"리듬적 다양성을 탐구하며 우리는 하나가 되었습니다. 비지도 표현 학습 기술을 통해 발음, 리듬, 음색의 분리를 통해 표현력이 뛰어난 음향 모델 프레임워크를 독립적으로 개발했습니다. 이를 통해 필요한 데이터 양을 줄일 뿐만 아니라 극저주파 발음 현상에 대한 효율적인 모델링을 달성합니다. 동시에 비지도 표현 기능을 음소 수준의 기본 주파수, 에너지 정보 등과 결합하여 운율의 자연스러운 변화를 달성하고 고품질 대화 음성 생성을 촉진합니다."라고 Huoshan Speech Team은 결론지었습니다.
위 내용은 Volcano Voice의 최신 초자연적 대화 음성 합성 기술을 사용하여 데이터 양의 1/4만 사용하여 실제 음성의 100% 세부 사항을 복원합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!