
다중 모드 융합 BEV 표적 탐지 방법 AutoAlign V1 및 V2

- PHPz앞으로
- 2023-04-08 14:41:151347검색
자율 주행에서는 RGB 이미지 또는 LiDAR 포인트 클라우드를 통한 표적 탐지가 널리 연구되었습니다. 그러나 이 두 데이터 소스를 상호 보완적이고 유익하게 만드는 방법은 여전히 과제로 남아 있습니다. AutoAlignV1 및 AutoAlignV2는 주로 중국 과학 기술 대학교, 하얼빈 공과 대학 및 SenseTime(처음에는 홍콩 중문 대학교 및 칭화 대학교 포함)의 작업입니다.
AutoAlignV1은 2022년 4월에 업로드된 arXiv 논문 "AutoAlign: 다중 모드 3D 객체 감지를 위한 픽셀 인스턴스 기능 집계"에서 가져온 것입니다.

Abstract
본 논문에서는 3D 타겟 탐지를 위한 자동 특징 융합 전략 AutoAlign V1을 제안합니다. 카메라 투영 행렬과 결정론적 대응을 설정하는 대신 학습 가능한 정렬 맵을 사용하여 이미지와 포인트 클라우드 간의 매핑 관계를 모델링합니다. 이 그래프를 사용하면 모델이 동형 및 데이터 기반 방식으로 비동형 특징을 자동으로 정렬할 수 있습니다. 특히, 교차 주의 특징 정렬 모듈은 각 복셀의 픽셀 수준 이미지 특징을 적응적으로 집계하도록 설계되었습니다. 특징 정렬 과정에서 의미론적 일관성을 높이기 위해 모델이 인스턴스 수준 특징에 따라 특징 집계를 학습할 수 있는 자체 지도형 크로스 모달 특징 상호 작용 모듈도 설계되었습니다.
배경 소개
다중 모드 3D 객체 감지기는 크게 결정 수준 융합과 기능 수준 융합의 두 가지 범주로 나눌 수 있습니다. 전자는 해당 모드에서 객체를 감지한 다음 경계 상자를 3D 공간에 함께 가져옵니다. 결정 수준 융합과 달리 기능 수준 융합은 다중 모드 기능을 단일 표현으로 결합하여 객체를 감지합니다. 따라서 검출기는 추론 단계에서 다양한 양식의 특징을 최대한 활용할 수 있습니다. 이를 고려하여 최근에는 더 많은 기능 수준의 융합 방법이 개발되었습니다.
작업은 각 점을 이미지 평면에 투영하고 이중선형 보간을 통해 해당 이미지 특징을 얻습니다. 특징 집합이 픽셀 수준에서 세밀하게 이루어지더라도 융합점의 희소성으로 인해 이미지 영역의 조밀한 패턴이 손실됩니다. 즉, 이미지 특징의 의미적 일관성이 파괴됩니다.
또 다른 작업은 3D 검출기가 제공하는 초기 솔루션을 사용하여 다양한 양식의 RoI 특징을 얻고 특징 융합을 위해 함께 연결합니다. 인스턴스 수준의 융합을 수행하여 의미적 일관성을 유지하지만, 초기 제안 생성 단계에서 거친 특징 집합, 2차원 정보 누락 등의 문제가 발생합니다.
이 두 가지 방법을 완전히 활용하기 위해 저자는 AutoAlign이라는 3D 개체 감지를 위한 통합 다중 모드 기능 융합 프레임워크를 제안합니다. 이를 통해 검출기는 적응형 방식으로 교차 모달 특징을 집계할 수 있어 비동형 표현 간의 관계를 모델링하는 데 효과적인 것으로 입증됩니다. 동시에 인스턴스 수준 기능 상호 작용을 통해 의미론적 일관성을 유지하면서 픽셀 수준의 세분화된 기능 집계를 활용합니다.
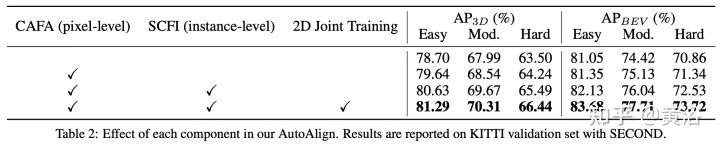
그림에 표시된 대로: 기능 상호 작용은 (i) 픽셀 수준 기능 집계, (ii) 인스턴스 수준 기능 상호 작용의 두 가지 수준에서 작동합니다.
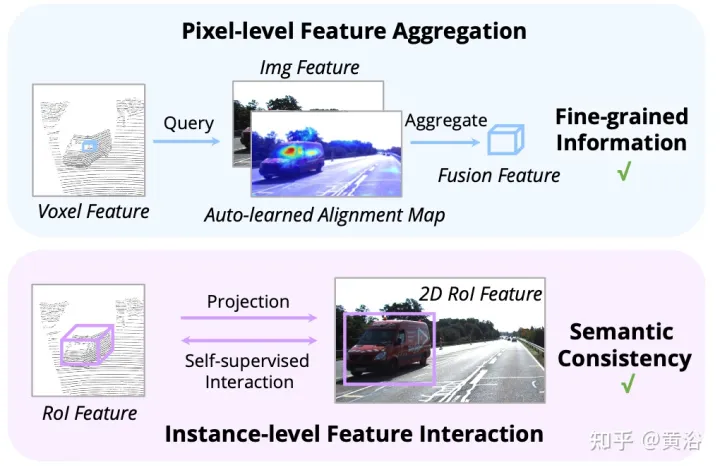
AutoAlign Method
이전 작업에서는 주로 카메라 투영 행렬을 사용하여 이미지와 점 특징을 결정적인 방식으로 정렬했습니다. 이 접근 방식은 효과적이지만 두 가지 잠재적인 문제가 발생할 수 있습니다. 1) 포인트가 이미지 데이터에 대한 더 넓은 시야를 얻을 수 없다는 점, 2) 위치 일관성만 유지되고 의미적 상관 관계가 무시된다는 점입니다. 따라서 AutoAlign은 비동형 표현 간의 기능을 적응적으로 정렬하기 위해 CAFA(Cross Attention Feature Alignment) 모듈을 설계했습니다. CAFA(Cross-Attention Feature Alignment) 이 모듈은 일대일 매칭 모드를 사용하지 않지만 각 복셀이 전체 이미지를 인식하고 학습 가능한 정렬 맵을 기반으로 픽셀 수준 2D 기능에 동적으로 초점을 맞춥니다.
그림에 표시된 대로 AutoAlign은 두 가지 핵심 구성 요소로 구성됩니다. CAFA는 이미지 평면에서 특징 집계를 수행하고 각 복셀 특징의 세밀한 픽셀 수준 정보를 추출합니다. SCFI(Self-supervised Cross-modal Feature Interaction) 모달 간 기능 상호 작용을 수행합니다. 모달 자체 감독은 인스턴스 수준 지침을 사용하여 CAFA 모듈의 의미론적 일관성을 향상합니다.
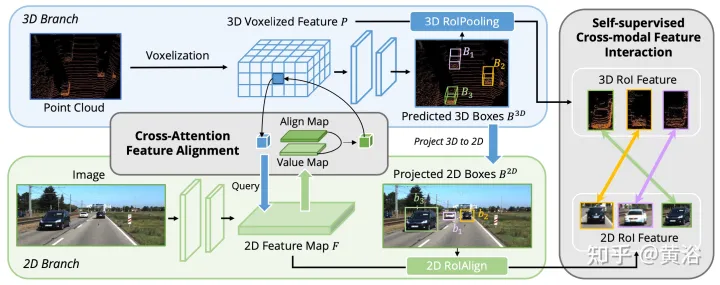
CAFA는 이미지 기능을 집계하기 위한 세분화된 패러다임입니다. 그러나 인스턴스 수준 정보를 캡처할 수는 없습니다. 반면 RoI 기반 특징 융합은 제안 생성 단계에서 거친 특징 집합과 2D 정보 누락으로 어려움을 겪으면서 객체의 무결성을 유지합니다.
픽셀 수준과 인스턴스 수준 융합 간의 격차를 해소하기 위해 CAFA 학습을 안내하기 위해 SCFI(자체 감독 교차 모달 기능 상호 작용) 모듈이 도입되었습니다. 3D 검출기의 최종 예측을 제안으로 직접 활용하고 정확한 제안 생성을 위해 이미지와 포인트 특징을 활용합니다. 또한 추가 경계 상자 최적화를 위해 교차 모달 기능을 함께 연결하는 대신 유사성 제약 조건이 기능 정렬을 위한 인스턴스 수준 지침으로 교차 모달 기능 쌍에 추가됩니다.
2D 특징 맵과 해당 3D 복셀화된 특징이 주어지면 N개의 지역 3D 감지 프레임이 무작위로 샘플링된 다음 카메라 투영 행렬을 사용하여 2D 평면에 투영되어 2D 프레임 쌍 세트를 생성합니다. 쌍을 이루는 상자가 얻어지면 2DRoIAlign 및 3DRoIPooling이 2D 및 3D 특징 공간에서 사용되어 각각의 RoI 특징을 얻습니다.
2D 및 3D RoI 기능의 각 쌍에 대해 이미지 분기의 기능과 포인트 분기의 복셀화된 기능에 대해 자체 감독 교차 모달 기능 상호 작용(SCFI)을 수행합니다. 두 기능 모두 프로젝션 헤드에 공급되어 한 양식의 출력을 다른 양식과 일치하도록 변환합니다. 두 개의 완전히 연결된 레이어가 있는 예측 헤드를 도입합니다. 그림에서 볼 수 있듯이:
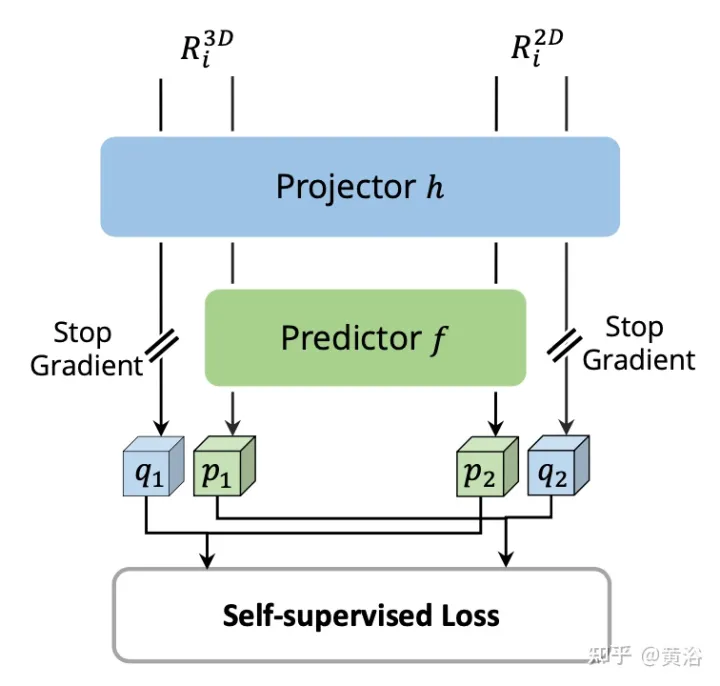
다중 작업 학습이 매우 효과적이지만 이미지 도메인과 포인트 도메인의 결합 감지에 대해 논의한 연구는 거의 없습니다. 대부분의 이전 방법에서는 이미지 백본이 외부 데이터세트의 사전 훈련된 가중치를 사용하여 직접 초기화되었습니다. 훈련 단계에서 유일한 감독은 포인트 분기에서 전파되는 3D 감지 손실입니다. 이미지 백본의 많은 매개변수를 고려할 때 2D 분기는 암시적 감독 하에서 과적합을 달성할 가능성이 더 높습니다. 이미지에서 추출된 표현을 정규화하기 위해 이미지 분기가 Faster R-CNN으로 확장되고 2D 감지 손실로 감독됩니다.
실험 결과
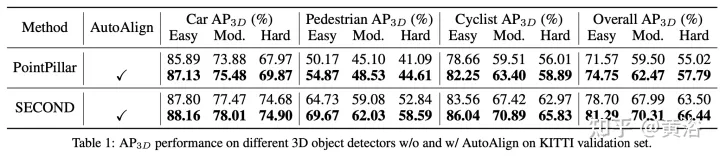
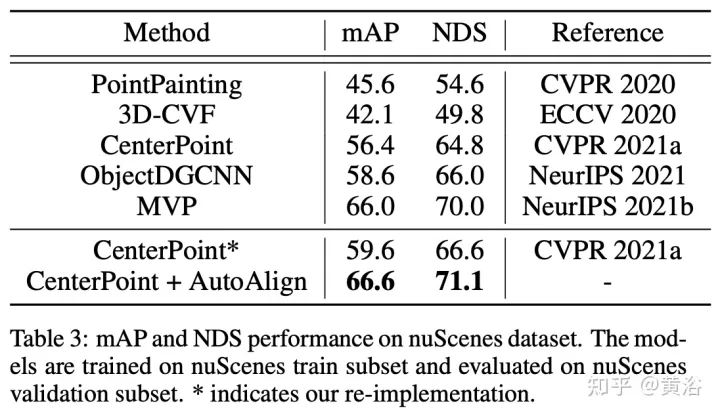
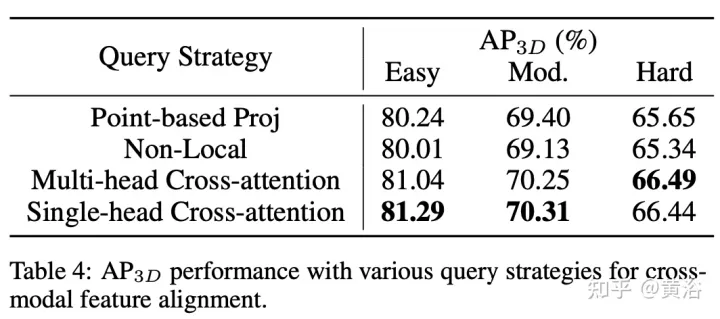
AutoAlignV2는 2022년 7월 업로드된 "AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Protection"에서 가져온 것입니다.

Abstract
AutoAlign은 글로벌 어텐션 메커니즘으로 인해 발생하는 높은 계산 비용으로 인해 어려움을 겪습니다. 이를 위해 저자는 AutoAlign을 기반으로 더 빠르고 강력한 다중 모드 3D 감지 프레임워크인 AutoAlignV2를 제안합니다. 계산 비용 문제를 해결하기 위해 이 기사에서는 Cross-Attention Feature Alignment) 모듈을 제안합니다. 이는 교차 모달 관계 모델을 위한 학습 가능한 희소 샘플링 지점에 중점을 두어 교정 오류에 대한 허용 오차를 향상시키고 양식 전반에 걸쳐 기능 집계 속도를 크게 높입니다. 다중 모드 설정에서 복잡한 GT-AUG를 극복하기 위해 깊이 정보가 제공된 이미지 패치를 기반으로 볼록한 조합을 위한 간단하고 효과적인 교차 모드 향상 전략이 설계되었습니다. 또한 이미지 수준의 드롭아웃 훈련 방식을 통해 모델은 동적 방식으로 추론을 수행할 수 있습니다.
코드는 오픈 소스입니다:https://github.com/zehuichen123/AutoAlignV2.
참고: GT-AUG("SECOND: Sparsely Embedded ConvolutionalDetection". Sensors, 2018 ), 데이터 증강 방법
배경 3D 객체 감지를 위해 LiDAR와 카메라의 이종 표현을 효과적으로 결합하는 방법은 완전히 탐색되지 않았습니다. 현재 교차 모드 탐지기 훈련의 어려움은 두 가지 측면에 기인합니다. 한편, 이미지와 공간정보를 결합한 융합 전략은 여전히 차선책이다. RGB 이미지와 포인트 클라우드 간의 이질적인 표현으로 인해 특징을 함께 클러스터링하기 전에 신중한 정렬이 필요합니다. AutoAlign은 자동 등록을 위한 학습 가능한 전역 정렬 모듈을 제안하고 좋은 성능을 달성합니다. 그러나 점과 이미지 픽셀 간의 내부 위치 일치 관계를 얻으려면 CSFI 모듈의 도움으로 훈련되어야 합니다.또한 스타일의 작업 복잡성은 이미지 크기에 따라 2차이므로 고해상도 기능 맵에 쿼리를 적용하는 것은 비현실적입니다. 이러한 제한으로 인해 이미지 정보가 거칠고 부정확할 뿐만 아니라 FPN으로 인해 계층적 표현이 손실될 수 있습니다. 반면, 데이터 확대, 특히 GT-AUG는 3D 검출기가 경쟁력 있는 결과를 달성하기 위한 핵심 단계입니다. 다중 모드 접근 방식의 측면에서 중요한 문제는 잘라내기 및 붙여넣기 작업을 수행할 때 이미지와 포인트 클라우드 간의 동기화를 유지하는 방법입니다. MoCa는 정확한 이미지 특징을 얻기 위해 2D 영역에서 노동 집약적인 마스크 주석을 사용합니다. 테두리 수준 주석도 적합하지만 정교한 포인트 필터링이 필요합니다.
AutoAlignV2 방법
AutoAlignV2는 이미지 특징을 효율적으로 집계하여 3D 개체 감지기의 성능을 더욱 향상시키는 것을 목표로 합니다. AutoAlign의 기본 아키텍처부터 시작하여 쌍을 이룬 이미지를 경량 백본 네트워크 ResNet에 입력한 다음 FPN에 입력하여 기능 맵을 얻습니다. 그런 다음 관련 이미지 정보는 학습 가능한 정렬 맵을 통해 집계되어 복셀화 단계에서 비어 있지 않은 복셀의 3D 표현을 풍부하게 합니다. 마지막으로 향상된 기능은 후속 3D 탐지 파이프라인에 공급되어 인스턴스 예측을 생성합니다.
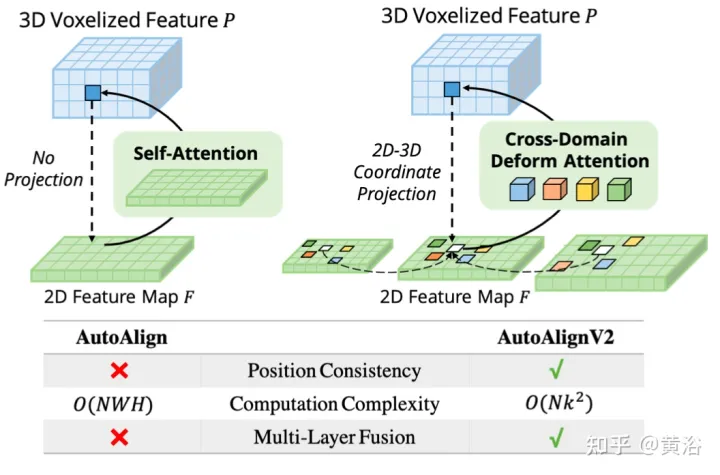
그림은 AutoAlignV1과 AutoAlignV2의 비교를 보여줍니다. AutoAlignV2는 특징 집계 위치를 자동으로 조정하는 기능을 유지하면서 결정론적 투영 행렬에 의해 보장되는 일반 매핑 관계를 가지도록 정렬 모듈을 유도합니다. 가벼운 계산 비용으로 인해 AutoAlignV2는 계층적 이미지 정보의 다중 레이어 기능을 집계할 수 있습니다.
이 패러다임은 데이터 기반 방식으로 이질적인 기능을 집계할 수 있습니다. 그러나 두 가지 주요 병목 현상이 여전히 성능을 방해합니다. 첫 번째는 비효율적인 특성 집계입니다. 글로벌 어텐션 맵은 RGB 이미지와 LiDAR 포인트 간의 특징 정렬을 자동으로 달성하지만 계산 비용이 높습니다. 두 번째는 이미지와 포인트 간의 복잡한 데이터 강화 동기화입니다. GT-AUG는 고성능 3D 객체 감지기의 핵심 단계이지만 훈련 중에 점과 이미지 간의 의미적 일관성을 유지하는 방법은 여전히 복잡한 문제로 남아 있습니다.
그림에 표시된 것처럼 AutoAlignV2는 Cross-domain DeformCAFA모듈과 Depth-aware GT-AUG데이터 향상 전략의 두 부분으로 구성됩니다. 더 역동적인 추론 방법.
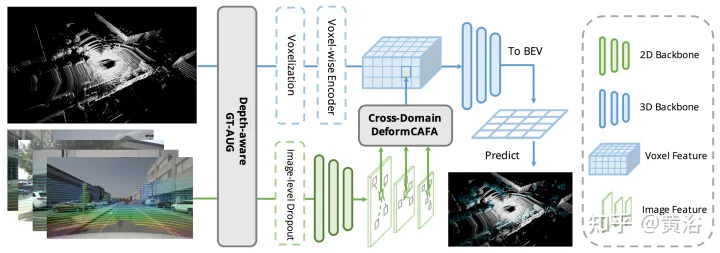
- 변형 특징 집계
CAFA의 병목 현상은 모든 픽셀을 가능한 공간 위치로 처리하는 것입니다. 2D 이미지의 특성상 관련성이 가장 높은 정보는 주로 기하학적으로 인접한 위치에 위치합니다. 따라서 모든 위치를 고려할 필요는 없고 몇 가지 핵심 포인트 영역만 고려할 필요가 있습니다. 그림에 표시된 대로 새로운 교차 도메인 DeformCAFA 작업이 여기에 도입되어 샘플링 후보를 크게 줄이고 각 복셀 쿼리 기능에 대한 이미지 평면의 키포인트 영역을 동적으로 결정합니다.
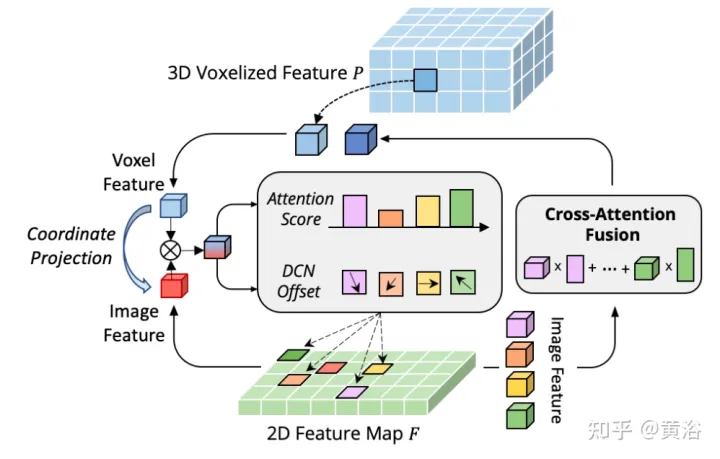
동적으로 생성된 샘플링 오프셋의 도움으로 DeformCAFA는 일반 작업보다 더 빠르게 도메인 간 관계를 모델링할 수 있습니다. 즉, FPN 계층에서 제공하는 계층 정보를 최대한 활용하여 다중 계층 기능 집계를 수행할 수 있습니다. DeformCAFA의 또 다른 장점은 참조점을 얻기 위해 카메라 투영 매트릭스와의 위치 일관성을 명시적으로 유지한다는 것입니다. 따라서 DeformCAFA는 AutoAlign에서 제안하는 CFSI 모듈을 채택하지 않고도 의미상, 위치적으로 일관된 정렬을 생성할 수 있습니다.
일반적인 비로컬 작업과 비교하여 희소 스타일 DeformCAFA는 효율성을 크게 향상시킵니다. 그러나 복셀 특징을 토큰으로 직접 적용하여 주의 가중치와 변형 가능한 오프셋을 생성하는 경우 탐지 성능은 이중선형 보간과 거의 비슷하거나 심지어 더 나쁩니다. 주의 깊게 분석한 결과 토큰 생성 과정에서 도메인 간 지식 번역 문제가 있습니다. 일반적으로 단봉 설정에서 수행되는 원래 변형 작업과 달리 교차 도메인 주의에는 두 양식의 정보가 필요합니다. 그러나 복셀 특징은 공간 영역 표현으로만 구성되어 이미지 영역의 정보를 인식하기 어렵습니다. 따라서 서로 다른 양식 간의 상호 작용을 줄이는 것이 중요합니다.
각 대상의 표현이 도메인별 정보와 인스턴스별 정보라는 두 가지 구성 요소로 명확하게 분해될 수 있다고 가정합니다. 전자는 도메인 특징에 내장된 속성을 포함하여 표현 자체와 관련된 데이터를 의미하고, 후자는 대상이 어떤 도메인에 인코딩되어 있는지에 관계없이 대상에 대한 ID 정보를 나타냅니다.
- Deep-aware GT-AUG
대부분의 딥 러닝 모델에서 데이터 증강은 경쟁력 있는 결과를 달성하는 데 중요한 부분입니다. 그러나 멀티모달 3D 객체 검출 측면에서 데이터 증강에서 포인트 클라우드와 이미지를 결합할 때 주로 객체 폐색이나 시점 변경으로 인해 둘 사이의 동기화를 유지하기가 어렵습니다. 이 문제를 해결하기 위해 깊이 인식 GT-AUG라는 간단하면서도 효과적인 교차 모드 데이터 증대 알고리즘이 설계되었습니다. 이 방법은 복잡한 포인트 클라우드 필터링 프로세스나 이미지 도메인의 미세한 마스크 주석에 대한 요구 사항을 포기합니다. 대신 3D 객체 주석의 깊이 정보가 혼합 이미지 영역에 도입됩니다.
구체적으로 붙여넣을 가상 대상 P가 주어지면 GT-AUG의 동일한 3D 구현을 따릅니다. 이미지 도메인의 경우 먼저 먼 곳에서 가까운 곳으로 정렬됩니다. 붙여넣을 각 대상에 대해 원본 이미지에서 동일한 영역을 잘라내어 혼합 비율 α로 대상 이미지에 결합합니다. 자세한 구현은 아래 알고리즘 1에 나와 있습니다.

깊이 인식 GT-AUG는 3D 영역에서만 증강 전략을 따르지만 동시에 혼합 기반 잘라내기 및 붙여넣기를 통해 이미지 평면을 동기화된 상태로 유지합니다. 중요한 점은 원본 2D 이미지에 향상된 패치를 붙여넣은 후에도 MixUp 기술이 해당 정보를 완전히 제거하지 않는다는 것입니다. 대신, 해당 지점의 특징이 존재하도록 보장하기 위해 깊이에 대한 정보의 압축성을 약화시킵니다. 구체적으로, 대상이 다른 인스턴스에 의해 n번 가려지면 대상 영역의 투명도는 깊이 순서에 따라 (1− α)^n만큼 감소합니다.
그림에 표시된 것처럼 몇 가지 향상된 예가 있습니다.

- 이미지 수준 드롭아웃 훈련 전략
사실 이미지는 일반적으로 모든 3D 감지 시스템이 지원하지 않는 입력 옵션입니다. 따라서 보다 현실적이고 적용 가능한 다중 모드 탐지 솔루션은 동적 융합 접근 방식을 채택해야 합니다. 이미지를 사용할 수 없을 때 모델은 이미지를 사용할 수 있을 때 원본 포인트 클라우드를 기반으로 대상을 탐지하고 특징 융합을 수행합니다. 더 나은 예측을 생성합니다. 이 목표를 달성하기 위해 이미지 수준에서 클러스터링된 이미지 특징을 무작위로 삭제하고 학습 중에 0으로 채우는 이미지 수준 드롭아웃 학습 전략이 제안됩니다. 그림에 표시된 대로: (a) 이미지 융합, (b) 이미지 수준 드롭아웃 융합.
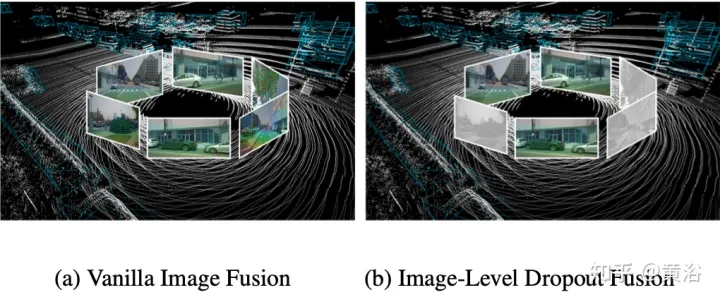
간헐적인 이미지 정보 손실로 인해 모델은 2D 기능을 대체 입력으로 사용하는 방법을 점차적으로 학습해야 합니다.
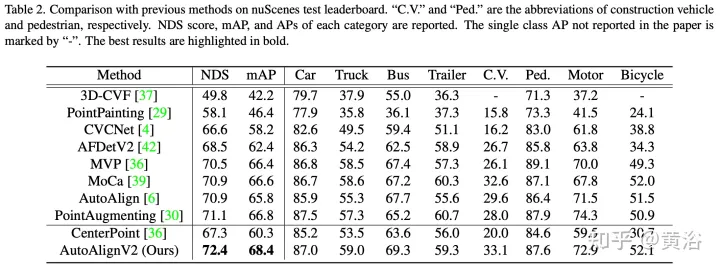
실험 결과



위 내용은 다중 모드 융합 BEV 표적 탐지 방법 AutoAlign V1 및 V2의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!