
집 >운영 및 유지보수 >리눅스 운영 및 유지 관리 >리눅스에서 프로세스 번호 0은 무엇입니까?
리눅스에서 프로세스 번호 0은 무엇입니까?

- 青灯夜游원래의
- 2023-03-15 19:31:193858검색
Linux에서 프로세스 번호 0은 Linux가 시작한 첫 번째 프로세스인 유휴 프로세스를 의미합니다. task_struct의 통신 필드는 "swapper"이므로 swpper 프로세스라고도 합니다. 0번 프로세스는 init_task가 정적 변수(초기화된 전역 변수)이고, 다른 프로세스의 PCB는 메모리를 동적으로 적용하는 fork 또는 kernel_thread에 의해 생성되므로 fork 또는 kernel_thread를 통해 생성되지 않는 유일한 프로세스입니다.

이 튜토리얼의 운영 환경: linux7.3 시스템, Dell G3 컴퓨터.
1. 프로세스 번호 0
프로세스 번호 0은 일반적으로 유휴 프로세스 또는 스왑퍼 프로세스라고도 합니다.
각 프로세스에는 프로세스 제어 블록 PCB(Process Control Block)가 있습니다. PCB의 데이터 구조 유형은 struct task_struct입니다. 유휴 프로세스에 해당하는 PCB는 struct task_struct init_task입니다.
유휴 프로세스는 init_task가 정적 변수(초기화된 전역 변수)이고 다른 프로세스의 PCB는 메모리를 동적으로 적용하는 fork 또는 kernel_thread에 의해 생성되기 때문에 fork 또는 kernel_thread를 통해 생성되지 않는 유일한 프로세스입니다.
각 프로세스에는 해당 함수가 있습니다. 유휴 프로세스의 함수는 start_kernel()입니다. 왜냐하면 이 함수에 들어가기 전에 스택 포인터 SP가 이미 init_task 스택의 최상위를 가리켰기 때문입니다. 스택 SP 포인트를 가리킵니다.
프로세스 0번은 Linux에서 시작한 첫 번째 프로세스입니다. task_struct의 comm 필드는 "swapper"이므로 swpper 프로세스라고도 합니다.
#define INIT_TASK_COMM "swapper"
시스템의 모든 프로세스가 가동되면 0번 프로세스가 유휴 프로세스로 변질됩니다. 코어에서 실행할 작업이 없으면 유휴 프로세스가 실행됩니다. 유휴 프로세스가 실행되면 코어는 ARM의 WFI인 저전력 모드로 들어갈 수 있습니다.
이 섹션에서는 프로세스 0이 시작되는 방법에 중점을 둡니다. Linux 커널에서는 init_task라고 하는 프로세스 번호 0에 대해 정적 task_struct 구조가 특별히 정의되어 있습니다.
/*
* Set up the first task table, touch at your own risk!. Base=0,
* limit=0x1fffff (=2MB)
*/
struct task_struct init_task
= {
#ifdef CONFIG_THREAD_INFO_IN_TASK
.thread_info = INIT_THREAD_INFO(init_task),
.stack_refcount = ATOMIC_INIT(1),
#endif
.state = 0,
.stack = init_stack,
.usage = ATOMIC_INIT(2),
.flags = PF_KTHREAD,
.prio = MAX_PRIO - 20,
.static_prio = MAX_PRIO - 20,
.normal_prio = MAX_PRIO - 20,
.policy = SCHED_NORMAL,
.cpus_allowed = CPU_MASK_ALL,
.nr_cpus_allowed= NR_CPUS,
.mm = NULL,
.active_mm = &init_mm,
.tasks = LIST_HEAD_INIT(init_task.tasks),
.ptraced = LIST_HEAD_INIT(init_task.ptraced),
.ptrace_entry = LIST_HEAD_INIT(init_task.ptrace_entry),
.real_parent = &init_task,
.parent = &init_task,
.children = LIST_HEAD_INIT(init_task.children),
.sibling = LIST_HEAD_INIT(init_task.sibling),
.group_leader = &init_task,
RCU_POINTER_INITIALIZER(real_cred, &init_cred),
RCU_POINTER_INITIALIZER(cred, &init_cred),
.comm = INIT_TASK_COMM,
.thread = INIT_THREAD,
.fs = &init_fs,
.files = &init_files,
.signal = &init_signals,
.sighand = &init_sighand,
.blocked = {{0}},
.alloc_lock = __SPIN_LOCK_UNLOCKED(init_task.alloc_lock),
.journal_info = NULL,
INIT_CPU_TIMERS(init_task)
.pi_lock = __RAW_SPIN_LOCK_UNLOCKED(init_task.pi_lock),
.timer_slack_ns = 50000, /* 50 usec default slack */
.thread_pid = &init_struct_pid,
.thread_group = LIST_HEAD_INIT(init_task.thread_group),
.thread_node = LIST_HEAD_INIT(init_signals.thread_head),
};
EXPORT_SYMBOL(init_task);이 구조의 멤버는 모두 정적으로 정의되어 있으며 간단한 설명을 위해 이 구조는 단순히 삭제되었습니다. 동시에, 우리는 이 구조에서 다음 필드에만 주의를 기울이고 다른 필드에는 주의를 기울이지 않습니다.
.thread_info = INIT_THREAD_INFO(init_task), 이 구조는 thread_info와 커널 스택 사이의 관계에서 자세히 설명됩니다
.stack = init_stack, init_stack은 커널 스택
의 정적 정의입니다. comm = INIT_TASK_COMM, 프로세스 0의 이름입니다.
thread_info와 stack은 모두 Init_stack을 포함하므로 먼저 init_stack이 설정된 위치를 살펴보세요.
드디어 init_task가 링커 스크립트에 정의되어 있음을 발견했습니다.
#define INIT_TASK_DATA(align) \
. = ALIGN(align); \
__start_init_task = .; \
init_thread_union = .; \
init_stack = .; \
KEEP(*(.data..init_task)) \
KEEP(*(.data..init_thread_info)) \
. = __start_init_task + THREAD_SIZE; \
__end_init_task = .;는 링크 스크립트에 INIT_TASK_DATA 매크로를 정의합니다.
그 중 __start_init_task는 0번 프로세스의 커널 스택의 기본 주소입니다. 물론 init_thread_union=init_task=__start_init_task입니다.
프로세스 0의 커널 스택 끝 주소는 __start_init_task + THREAD_SIZE와 같습니다. THREAD_SIZE의 크기는 일반적으로 ARM64에서 16K 또는 32K입니다. 그러면 __end_init_task는 0번 프로세스의 커널 스택 끝 주소입니다.
유휴 프로세스는 시스템에 의해 자동으로 생성되고 커널 상태에서 실행됩니다. 유휴 프로세스는 pid=0입니다. 그 이전 프로세스는 시스템에서 생성된 첫 번째 프로세스이며 fork 또는 kernel_thread를 통해 생성되지 않는 유일한 프로세스입니다. 시스템을 로딩한 후 프로세스 스케줄링 및 교환으로 진화합니다.
2. Linux 커널 시작하기
Linux 커널에 익숙한 친구들은 부트로더가 일반적으로 Linux 커널 로딩을 완료하는 데 사용된다는 것을 알고 있습니다. 부트로더는 일부 하드웨어 초기화를 수행한 다음 Linux 커널로 점프합니다. .실행 주소로 올라갑니다.
ARM 아키텍처에 익숙하신 분들이라면 ARM64 아키텍처가 EL0, EL1, EL2, EL3으로 나누어져 있다는 것도 아실 겁니다. 일반 시작은 일반적으로 높은 권한 모드에서 낮은 권한 모드로 시작됩니다. 일반적으로 ARM64는 EL3을 먼저 실행한 다음 EL2를 실행하고 EL2에서 Linux 커널인 EL1로 트랩합니다.
리눅스 커널 시작을 위한 코드를 살펴보겠습니다.
코드 경로: arch/arm64/kernel/head.S 파일
/*
* Kernel startup entry point.
* ---------------------------
*
* The requirements are:
* MMU = off, D-cache = off, I-cache = on or off,
* x0 = physical address to the FDT blob.
*
* This code is mostly position independent so you call this at
* __pa(PAGE_OFFSET + TEXT_OFFSET).
*
* Note that the callee-saved registers are used for storing variables
* that are useful before the MMU is enabled. The allocations are described
* in the entry routines.
*/
/*
* The following callee saved general purpose registers are used on the
* primary lowlevel boot path:
*
* Register Scope Purpose
* x21 stext() .. start_kernel() FDT pointer passed at boot in x0
* x23 stext() .. start_kernel() physical misalignment/KASLR offset
* x28 __create_page_tables() callee preserved temp register
* x19/x20 __primary_switch() callee preserved temp registers
*/
ENTRY(stext)
bl preserve_boot_args
bl el2_setup // Drop to EL1, w0=cpu_boot_mode
adrp x23, __PHYS_OFFSET
and x23, x23, MIN_KIMG_ALIGN - 1 // KASLR offset, defaults to 0
bl set_cpu_boot_mode_flag
bl __create_page_tables
/*
* The following calls CPU setup code, see arch/arm64/mm/proc.S for
* details.
* On return, the CPU will be ready for the MMU to be turned on and
* the TCR will have been set.
*/
bl __cpu_setup // initialise processor
b __primary_switch
ENDPROC(stext)위는 start_kernel을 호출하기 전에 커널이 수행하는 주요 작업입니다.
preserve_boot_args는 ARM
el2_setup의 일반적인 dtb 주소와 같이 부트로더가 전달한 매개변수를 보존하는 데 사용됩니다. 주석에서 EL1을 트랩하는 데 사용되어 이를 실행하기 전에 여전히 EL2에 있음을 나타냅니다. command
__create_page_tables: 사용 페이지 테이블을 생성하려면 Linux에는 물리적 메모리를 관리하는 페이지만 있습니다. 가상 주소를 사용하기 전에 페이지를 설정한 후 MMU를 열어야 합니다. 실제 주소에서 여전히 실행 중입니다
__primary_switch: 주요 작업은 MMU
__primary_switch:
adrp x1, init_pg_dir
bl __enable_mmu
ldr x8, =__primary_switched
adrp x0, __PHYS_OFFSET
br x8
ENDPROC(__primary_switch)主要是调用__enable_mmu来打开mmu,之后我们访问的就是虚拟地址了
调用__primary_switched来设置0号进程的运行内核栈,然后调用start_kernel函数
/* * The following fragment of code is executed with the MMU enabled. * * x0 = __PHYS_OFFSET */ __primary_switched: adrp x4, init_thread_union add sp, x4, #THREAD_SIZE adr_l x5, init_task msr sp_el0, x5 // Save thread_info adr_l x8, vectors // load VBAR_EL1 with virtual msr vbar_el1, x8 // vector table address isb stp xzr, x30, [sp, #-16]! mov x29, sp str_l x21, __fdt_pointer, x5 // Save FDT pointer ldr_l x4, kimage_vaddr // Save the offset between sub x4, x4, x0 // the kernel virtual and str_l x4, kimage_voffset, x5 // physical mappings // Clear BSS adr_l x0, __bss_start mov x1, xzr adr_l x2, __bss_stop sub x2, x2, x0 bl __pi_memset dsb ishst // Make zero page visible to PTW add sp, sp, #16 mov x29, #0 mov x30, #0 b start_kernel ENDPROC(__primary_switched)
init_thread_union就是我们在链接脚本中定义的,也就是0号进程的内核栈的栈底
add sp, x4, #THREAD_SIZE: 设置堆栈指针SP的值,就是内核栈的栈底+THREAD_SIZE的大小。现在SP指到了内核栈的顶端
最终通过b start_kernel就跳转到我们熟悉的linux内核入口处了。 至此0号进程就已经运行起来了。
三、1号进程
3.1 1号进程的创建
当一条b start_kernel指令运行后,内核就开始的内核的全面初始化操作。
asmlinkage __visible void __init start_kernel(void)
{
char *command_line;
char *after_dashes;
set_task_stack_end_magic(&init_task);
smp_setup_processor_id();
debug_objects_early_init();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them.
*/
boot_cpu_init();
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
/*
* Set up the the initial canary and entropy after arch
* and after adding latent and command line entropy.
*/
add_latent_entropy();
add_device_randomness(command_line, strlen(command_line));
boot_init_stack_canary();
mm_init_cpumask(&init_mm);
setup_command_line(command_line);
setup_nr_cpu_ids();
setup_per_cpu_areas();
smp_prepare_boot_cpu(); /* arch-specific boot-cpu hooks */
boot_cpu_hotplug_init();
build_all_zonelists(NULL);
page_alloc_init();
。。。。。。。
acpi_subsystem_init();
arch_post_acpi_subsys_init();
sfi_init_late();
/* Do the rest non-__init'ed, we're now alive */
arch_call_rest_init();
}
void __init __weak arch_call_rest_init(void)
{
rest_init();
}start_kernel函数就是内核各个重要子系统的初始化,比如mm, cpu, sched, irq等等。最后会调用一个rest_init剩余部分初始化,start_kernel在其最后一个函数rest_init的调用中,会通过kernel_thread来生成一个内核进程,后者则会在新进程环境下调 用kernel_init函数,kernel_init一个让人感兴趣的地方在于它会调用run_init_process来执行根文件系统下的 /sbin/init等程序。
noinline void __ref rest_init(void)
{
struct task_struct *tsk;
int pid;
rcu_scheduler_starting();
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
pid = kernel_thread(kernel_init, NULL, CLONE_FS);
/*
* Pin init on the boot CPU. Task migration is not properly working
* until sched_init_smp() has been run. It will set the allowed
* CPUs for init to the non isolated CPUs.
*/
rcu_read_lock();
tsk = find_task_by_pid_ns(pid, &init_pid_ns);
set_cpus_allowed_ptr(tsk, cpumask_of(smp_processor_id()));
rcu_read_unlock();
numa_default_policy();
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
/*
* Enable might_sleep() and smp_processor_id() checks.
* They cannot be enabled earlier because with CONFIG_PREEMPT=y
* kernel_thread() would trigger might_sleep() splats. With
* CONFIG_PREEMPT_VOLUNTARY=y the init task might have scheduled
* already, but it's stuck on the kthreadd_done completion.
*/
system_state = SYSTEM_SCHEDULING;
complete(&kthreadd_done);
}在这个rest_init函数中我们只关系两点:
pid = kernel_thread(kernel_init, NULL, CLONE_FS);
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
/*
* Create a kernel thread.
*/
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
return _do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn,
(unsigned long)arg, NULL, NULL, 0);
}很明显这是创建了两个内核线程,而kernel_thread最终会调用do_fork根据参数的不同来创建一个进程或者内核线程。关系do_fork的实现我们在后面会做详细的介绍。当内核线程创建成功后就会调用设置的回调函数。
当kernel_thread(kernel_init)成功返回后,就会调用kernel_init内核线程,其实这时候1号进程已经产生了。1号进程的执行函数就是kernel_init, 这个函数被定义init/main.c中,接下来看下kernel_init主要做什么事情。
static int __ref kernel_init(void *unused)
{
int ret;
kernel_init_freeable();
/* need to finish all async __init code before freeing the memory */
async_synchronize_full();
ftrace_free_init_mem();
free_initmem();
mark_readonly();
/*
* Kernel mappings are now finalized - update the userspace page-table
* to finalize PTI.
*/
pti_finalize();
system_state = SYSTEM_RUNNING;
numa_default_policy();
rcu_end_inkernel_boot();
if (ramdisk_execute_command) {
ret = run_init_process(ramdisk_execute_command);
if (!ret)
return 0;
pr_err("Failed to execute %s (error %d)\n",
ramdisk_execute_command, ret);
}
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");
}kernel_init_freeable函数中就会做各种外设驱动的初始化。
最主要的工作就是通过execve执行/init可以执行文件。它按照配置文件/etc/initab的要求,完成系统启动工作,创建编号为1号、2号...的若干终端注册进程getty。每个getty进程设置其进程组标识号,并监视配置到系统终端的接口线路。当检测到来自终端的连接信号时,getty进程将通过函数execve()执行注册程序login,此时用户就可输入注册名和密码进入登录过程,如果成功,由login程序再通过函数execv()执行shell,该shell进程接收getty进程的pid,取代原来的getty进程。再由shell直接或间接地产生其他进程。
我们通常将init称为1号进程,其实在刚才kernel_init的时候1号线程已经创建成功,也可以理解kernel_init是1号进程的内核态,而我们所熟知的init进程是用户态的,调用execve函数之前属于内核态,调用之后就属于用户态了,执行的代码段与0号进程不在一样。
1号内核线程负责执行内核的部分初始化工作及进行系统配置,并创建若干个用于高速缓存和虚拟主存管理的内核线程。
至此1号进程就完美的创建成功了,而且也成功执行了init可执行文件。
3.2 init进程
随后,1号进程调用do_execve运行可执行程序init,并演变成用户态1号进程,即init进程。
init进程是linux内核启动的第一个用户级进程。init有许多很重要的任务,比如像启动getty(用于用户登录)、实现运行级别、以及处理孤立进程。
它按照配置文件/etc/initab的要求,完成系统启动工作,创建编号为1号、2号…的若干终端注册进程getty。
每个getty进程设置其进程组标识号,并监视配置到系统终端的接口线路。当检测到来自终端的连接信号时,getty进程将通过函数do_execve()执行注册程序login,此时用户就可输入注册名和密码进入登录过程,如果成功,由login程序再通过函数execv()执行shell,该shell进程接收getty进程的pid,取代原来的getty进程。再由shell直接或间接地产生其他进程。
上述过程可描述为:0号进程->1号内核进程->1号用户进程(init进程)->getty进程->shell进程
注意,上述过程描述中提到:1号内核进程调用执行init函数并演变成1号用户态进程(init进程),这里前者是init是函数,后者是进程。两者容易混淆,区别如下:
kernel_init函数在内核态运行,是内核代码
init进程是内核启动并运行的第一个用户进程,运行在用户态下。
一号内核进程调用execve()从文件/etc/inittab中加载可执行程序init并执行,这个过程并没有使用调用do_fork(),因此两个进程都是1号进程。
当内核启动了自己之后(已被装入内存、已经开始运行、已经初始化了所有的设备驱动程序和数据结构等等),通过启动用户级程序init来完成引导进程的内核部分。因此,init总是第一个进程(它的进程号总是1)。
当init开始运行,它通过执行一些管理任务来结束引导进程,例如检查文件系统、清理/tmp、启动各种服务以及为每个终端和虚拟控制台启动getty,在这些地方用户将登录系统。
시스템이 완전히 가동된 후 init는 사용자가 로그아웃한 각 터미널에 대해 getty를 다시 시작합니다(다음 사용자가 로그인할 수 있도록). init는 또한 고아 프로세스를 수집합니다. 프로세스가 자식 프로세스를 시작하고 자식 프로세스보다 먼저 종료되면 자식 프로세스는 즉시 init의 자식 프로세스가 됩니다. 이는 다양한 기술적인 이유로 중요하지만 프로세스 목록과 프로세스 트리 다이어그램을 더 쉽게 이해할 수 있으므로 이를 아는 것이 좋습니다. init의 변형은 거의 없습니다. 대부분의 Linux 배포판은 System V의 init 디자인을 기반으로 하는 sysinit(Miguel van Smoorenburg 작성)를 사용합니다. UNIX의 BSD 버전에는 다른 초기화가 있습니다. 가장 큰 차이점은 런레벨입니다. System V에는 런레벨이 있고 BSD에는 (적어도 전통적으로) 없습니다. 이 구별은 기본이 아닙니다. 여기서는 sysvinit에 대해서만 논의합니다. getty를 시작하도록 init를 구성하십시오: /etc/inittab 파일.
3.3 init 프로그램
프로세스 1번은 execve를 통해 init 프로그램을 실행하여 사용자 공간에 들어가서 init 프로세스가 됩니다.
커널은 여러 위치에서 init를 검색합니다. 위치는 이전에 init를 배치하는 데 일반적으로 사용되었지만 (Linux 시스템에서) init에 가장 적합한 위치는 /sbin/init입니다. 커널이 init를 찾지 못하면 /bin/sh를 실행하려고 시도합니다. 그래도 실패하면 시스템 시작이 실패합니다.
그러므로 init 프로그램은 사용자가 작성할 수 있는 프로세스입니다. init 프로그램의 소스코드를 보고 싶다면 참고하시면 됩니다.
| init package | Instructions |
| sysvinit | 일부 이전 버전에서 사용된 초기화 프로세스 도구는 이제 Linux 기록 단계에서 점차 사라지고 있습니다. 이름에서 알 수 있듯이 시스템 V 스타일 초기화 시스템입니다. 이는 System V 시리즈 UNIX에서 유래되었음을 시사합니다. BSD 스타일의 init 시스템보다 더 큰 유연성을 제공합니다. 이는 수십 년 동안 널리 사용되어 왔으며 다양한 Linux 배포판에서 사용되어 온 UNIX 초기화 시스템입니다. |
| upstart | debian, Ubuntu 및 기타 시스템에서는 initdaemon을 사용합니다 |
| systemd | Systemd는 Linux 시스템의 최신 초기화 시스템(init)입니다. 주요 설계 목표는 sysvinit의 고유한 단점을 극복하고 개선하는 것입니다. 시스템 시작 속도 |
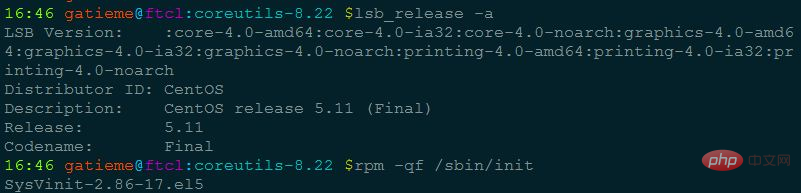
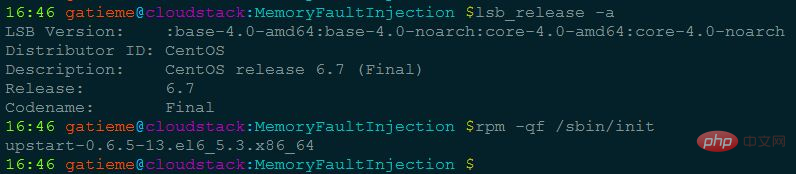
Ubuntu等使用deb包的系统可以通过dpkg -S查看程序所在的包

CentOS等使用rpm包的系统可以通过rpm -qf查看系统程序所在的包
四、2号进程
2号进程,也是由0号进程创建的。而且2号进程是所有内核线程父进程。
2号进程就是刚才rest_init中创建的另外一个内核线程。kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
当kernel_thread(kthreadd)返回时,2号进程已经创建成功了。而且会回调kthreadd函数。
int kthreadd(void *unused)
{
struct task_struct *tsk = current;
/* Setup a clean context for our children to inherit. */
set_task_comm(tsk, "kthreadd");
ignore_signals(tsk);
set_cpus_allowed_ptr(tsk, cpu_all_mask);
set_mems_allowed(node_states[N_MEMORY]);
current->flags |= PF_NOFREEZE;
cgroup_init_kthreadd();
for (;;) {
set_current_state(TASK_INTERRUPTIBLE);
if (list_empty(&kthread_create_list))
schedule();
__set_current_state(TASK_RUNNING);
spin_lock(&kthread_create_lock);
while (!list_empty(&kthread_create_list)) {
struct kthread_create_info *create;
create = list_entry(kthread_create_list.next,
struct kthread_create_info, list);
list_del_init(&create->list);
spin_unlock(&kthread_create_lock);
create_kthread(create);
spin_lock(&kthread_create_lock);
}
spin_unlock(&kthread_create_lock);
}
return 0;
}这段代码大概的意思也很简单明显;
- 设置当前进程的名字为"kthreadd",也就是task_struct的comm字段
- 然后就是while循环,设置当前的进程的状态是TASK_INTERRUPTIBLE是可以中断的
- 判断kthread_create_list链表是不是空,如果是空则就调度出去,让出cpu
- 如果不是空,则从链表中取出一个,然后调用kthread_create去创建一个内核线程。
- 所以说所有的内核线程的父进程都是2号进程,也就是kthreadd。
五、总结
linux启动的第一个进程是0号进程,是静态创建的,称为idle进程或者swapper进程。
在0号进程启动后会接连创建两个进程,分别是1号进程和2和进程。
1号进程最终会使用execve函数去调用可init可执行文件,init进程最终会去创建所有的应用进程,所以被称为inti进程。
2号进程会在内核中负责创建所有的内核线程,被称为kthreadd进程。
所以说0号进程是1号和2号进程的父进程;1号进程是所有用户态进程的父进程;2号进程是所有内核线程的父进程。
我们通过ps命令就可以详细的观察到这一现象。
root@ubuntu:zhuxl$ ps -eF UID PID PPID C SZ RSS PSR STIME TTY TIME CMD root 1 0 0 56317 5936 2 Feb16 ? 00:00:04 /sbin/init root 2 0 0 0 0 1 Feb16 ? 00:00:00 [kthreadd]
上面很清晰的显示:PID=1的进程是init,PID=2的进程是kthreadd。而他们俩的父进程PPID=0,也就是0号进程。
UID PID PPID C SZ RSS PSR STIME TTY TIME CMD root 4 2 0 0 0 0 Feb16 ? 00:00:00 [kworker/0:0H] root 6 2 0 0 0 0 Feb16 ? 00:00:00 [mm_percpu_wq] root 7 2 0 0 0 0 Feb16 ? 00:00:10 [ksoftirqd/0] root 8 2 0 0 0 1 Feb16 ? 00:02:11 [rcu_sched] root 9 2 0 0 0 0 Feb16 ? 00:00:00 [rcu_bh] root 10 2 0 0 0 0 Feb16 ? 00:00:00 [migration/0] root 11 2 0 0 0 0 Feb16 ? 00:00:00 [watchdog/0] root 12 2 0 0 0 0 Feb16 ? 00:00:00 [cpuhp/0] root 13 2 0 0 0 1 Feb16 ? 00:00:00 [cpuhp/1] root 14 2 0 0 0 1 Feb16 ? 00:00:00 [watchdog/1] root 15 2 0 0 0 1 Feb16 ? 00:00:00 [migration/1] root 16 2 0 0 0 1 Feb16 ? 00:00:11 [ksoftirqd/1] root 18 2 0 0 0 1 Feb16 ? 00:00:00 [kworker/1:0H] root 19 2 0 0 0 2 Feb16 ? 00:00:00 [cpuhp/2] root 20 2 0 0 0 2 Feb16 ? 00:00:00 [watchdog/2] root 21 2 0 0 0 2 Feb16 ? 00:00:00 [migration/2] root 22 2 0 0 0 2 Feb16 ? 00:00:11 [ksoftirqd/2] root 24 2 0 0 0 2 Feb16 ? 00:00:00 [kworker/2:0H]
再来看下,所有内核线性的PPI=2, 也就是所有内核线性的父进程都是kthreadd进程。
UID PID PPID C SZ RSS PSR STIME TTY TIME CMD root 362 1 0 21574 6136 2 Feb16 ? 00:00:03 /lib/systemd/systemd-journald root 375 1 0 11906 2760 3 Feb16 ? 00:00:01 /lib/systemd/systemd-udevd systemd+ 417 1 0 17807 2116 3 Feb16 ? 00:00:02 /lib/systemd/systemd-resolved systemd+ 420 1 0 35997 788 3 Feb16 ? 00:00:00 /lib/systemd/systemd-timesyncd root 487 1 0 43072 6060 0 Feb16 ? 00:00:00 /usr/bin/python3 /usr/bin/networkd-dispatcher --run-startup-triggers root 489 1 0 8268 2036 2 Feb16 ? 00:00:00 /usr/sbin/cron -f root 490 1 0 1138 548 0 Feb16 ? 00:00:01 /usr/sbin/acpid root 491 1 0 106816 3284 1 Feb16 ? 00:00:00 /usr/sbin/ModemManager root 506 1 0 27628 2132 2 Feb16 ? 00:00:01 /usr/sbin/irqbalance --foreground
所有用户态的进程的父进程PPID=1,也就是1号进程都是他们的父进程。
相关推荐:《Linux视频教程》
위 내용은 리눅스에서 프로세스 번호 0은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!