
한 기사로 Python 크롤러 이해하기

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-01-25 06:30:013555검색
이 기사는 Python에 대한 관련 지식을 제공하며 주로 크롤러에 대한 관련 지식을 소개합니다. 간단히 말해서 크롤러는 인터넷에서 데이터를 얻기 위해 프로그램을 사용하는 과정의 이름입니다. 모두에게 도움이 되기를 바랍니다. .

크롤러란 무엇인가요?
크롤러는 단순히 인터넷에서 데이터를 얻기 위해 프로그램을 사용하는 프로세스에 대한 이름입니다.
크롤러의 원리
인터넷에서 데이터를 얻으려면 크롤러에게 웹사이트 주소(보통 프로그램에서는 URL이라고 함)를 제공해야 합니다. 크롤러는 대상 웹페이지의 서버로 HTTP 요청을 보냅니다. 서버가 클라이언트(즉, 크롤러)에 데이터를 반환하면 크롤러는 데이터 구문 분석 및 저장과 같은 일련의 작업을 수행합니다.
Process
크롤러를 사용하면 시간을 절약할 수 있습니다. 예를 들어 상위 250개 Douban 영화를 가져오려면 크롤러를 사용하지 않는 경우 먼저 브라우저에 Douban 영화의 URL을 입력해야 하며 클라이언트에는 (브라우저)는 영화 웹 서버의 IP 주소를 분석하여 Douban을 찾아 연결합니다. 브라우저는 HTTP 요청을 생성하여 서버가 요청을 받은 후 이를 추출합니다. 데이터베이스에서 Top250 목록을 가져와 HTTP 응답으로 캡슐화한 다음 응답 결과가 브라우저에 반환되고 브라우저는 응답 콘텐츠를 표시하며 우리는 데이터를 봅니다. 우리 크롤러도 이 과정을 기반으로 하지만 코드 형태로 변경되었습니다.
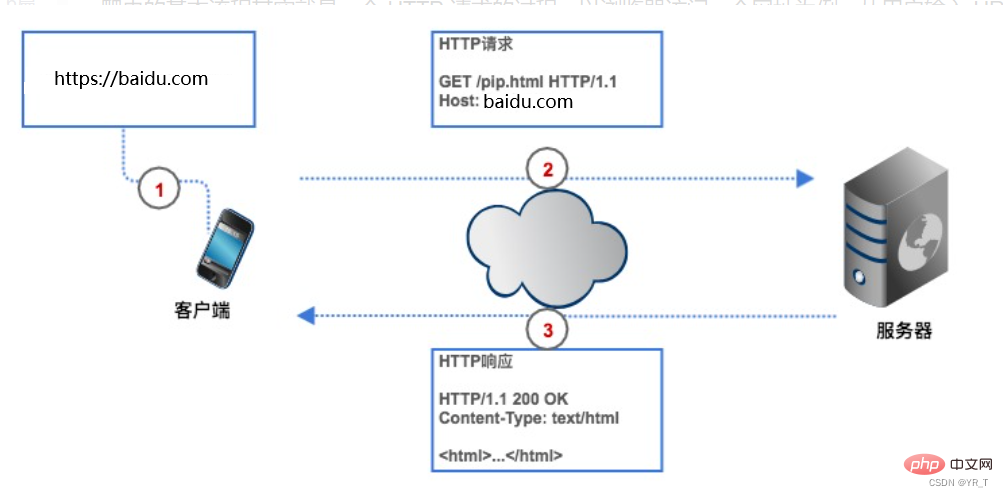
HTTP 요청
HTTP 요청은 요청 라인, 요청 헤더, 빈 라인, 요청 본문으로 구성됩니다.

요청 라인은 다음 세 부분으로 구성됩니다.
1. 요청 방법, 일반적인 요청 방법은 GET, POST, PUT, DELETE, HEAD입니다.
2. 클라이언트가 얻고자 하는 리소스 경로
3. 사용하는 방법 클라이언트 HTTP 프로토콜 버전 번호
요청 헤더는 방문자의 신원과 같이 클라이언트가 서버에 보낸 요청에 대한 보충 설명이며 이에 대해서는 아래에서 설명합니다.
요청 본문은 사용자가 로그인할 때 늘려야 하는 계정 및 비밀번호 정보와 같이 클라이언트가 서버에 제출한 데이터입니다. 요청 헤더와 요청 본문은 빈 줄로 구분됩니다. 요청 본문은 모든 요청에 포함되지 않습니다. 예를 들어 일반 GET에는 요청 본문이 없습니다.
위 사진은 브라우저가 Douban에 로그인할 때 서버로 전송되는 HTTP POST 요청입니다. 사용자 이름과 비밀번호는 요청 본문에 지정됩니다.
HTTP 응답
HTTP 응답 형식은 요청 형식과 매우 유사하며 응답 줄, 응답 헤더, 빈 줄 및 응답 본문으로 구성됩니다.

응답 줄에는 서버의 HTTP 버전 번호, 응답 상태 코드, 상태 설명의 세 부분도 포함되어 있습니다.
여기에는 각 상태 코드의 의미에 해당하는 상태 코드 표가 있습니다.



두 번째 부분은 응답 헤더에 해당하며, 일부 추가 항목입니다. 응답 내용의 형식은 무엇인지, 응답 내용의 길이는 얼마인지, 언제 클라이언트에 반환되는지, 심지어 일부 쿠키 정보도 응답 헤더에 배치되는지와 같은 응답에 대한 서버의 지침입니다.
세 번째 부분은 실제 응답 데이터인 응답 본문입니다. 이 데이터는 실제로 웹페이지의 HTML 소스 코드입니다.
크롤러 코드 작성 방법
크롤러는 Python, C++ 등 다양한 언어를 사용할 수 있지만, 저는 Python이 가장 간단하다고 생각합니다.
Python에는 거의 완벽하게 패키징된 기성 라이브러리가 있기 때문에,
C++에도 기성 라이브러리가 있지만 크롤러는 여전히 상대적으로 틈새 시장에 있습니다. 그들이 가지고 있는 유일한 라이브러리는 충분히 간단하지 않으며 코드는 다양한 컴파일러 또는 동일한 컴파일러의 다른 버전과도 잘 호환되지 않습니다. , 그래서 특별히 좋지는 않습니다. 그래서 오늘은 주로 Python 크롤러를 소개하겠습니다.
설치 요청 라이브러리
cmd run: pip install 요청을 설치하도록 요청합니다.
그런 다음 IDLE 또는 컴파일러(개인적으로 VS Code 또는 Pycharm 권장)에
import 요청을 입력하여 실행하면 오류가 보고되지 않으면 설치가 성공한 것입니다.
대부분의 라이브러리를 설치하는 방법은 다음과 같습니다: pip install xxx (라이브러리 이름)
요청 메소드
| requests.request() | 요청을 구성하고 각 메소드의 기본 메소드 지원 |
| requests.get() | HTTP의 GET에 해당하는 HTML 웹 페이지를 얻는 주요 메소드 |
requests.head() |
HTTP |
| requests.post()의 HEAD에 해당하는 HTML 웹페이지의 헤더 정보를 얻는 메소드 | POST를 제출하는 메소드 HTTP POST |
| requests.put()에 해당하는 HTML 웹페이지에 대한 요청 | HTTP의 PUT |
| requests.patch()에 해당하는 HTML 웹페이지에 PUT 요청 제출 | 부분 수정 요청 제출 HTTP PATCT |
| requests.delete()에 해당하는 HTML 웹페이지에 | 삭제 요청을 HTTP의 DELETE |
가장 일반적으로 사용되는 get 메소드
r = 요청에 해당하는 HTML 웹페이지에 제출합니다. get(url)
에는 두 가지 중요한 개체가 포함되어 있습니다.
서버에서 리소스를 요청하는 요청 개체를 구성합니다. 서버 리소스가 포함된 응답 개체를 반환합니다.
| r.status_code | HTTP 요청의 반환 상태, 200 연결 성공을 의미하고, 404는 실패를 의미합니다 |
| r.text | HTTP 응답 콘텐츠의 문자열 형식, 즉 url |
| r.encoding에 해당하는 페이지 콘텐츠 | 응답 콘텐츠 인코딩 HTTP 헤더에서 추측한 메서드(헤더에 문자 집합이 없으면 ISO-8859-1 인코딩 고려) |
| r.apparent_encoding | 콘텐츠에서 분석된 응답 콘텐츠 인코딩 방법(대체 인코딩 방법) |
| r.content | HTTP 응답 콘텐츠의 바이너리 형식 |
| requests.ConnectionError | DNS 쿼리 실패, 연결 거부 등과 같은 네트워크 연결 오류 예외 |
| 요청. HTTPError | HTTP 오류 예외 |
| requests.URLRequired | URL 누락 예외 |
| requests.TooManyRedirects | 최대 리디렉션 수를 초과하여 리디렉션 예외가 발생했습니다. |
| requests.Connect 시간 초과 | 다음에 연결하는 중 원격 서버 시간 초과 예외 |
| requests.Timeout | 요청 URL 시간이 초과되어 시간 초과 예외가 발생했습니다. |
Crawler small 데모
requests는 가장 기본적인 크롤러 라이브러리이지만 간단한 번역을 할 수 있습니다.
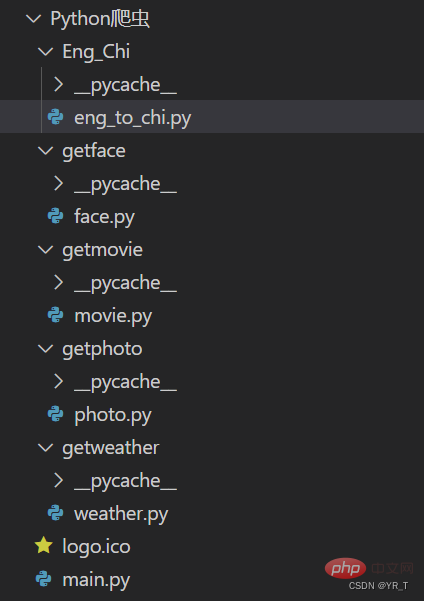
먼저 제가 만든 작은 크롤러 프로젝트의 프로젝트 구조를 올려보겠습니다. 전체 소스 코드는 저와의 비공개 채팅을 통해 다운로드할 수 있습니다.
다음은 번역 부분의 소스 코드입니다.
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])
상세 코드 설명:
요청 모듈을 가져오고 url을 바이두 번역 웹 페이지의 URL로 설정합니다.
그런 다음 post 방식으로 요청을 보낸 다음 반환된 결과를 dic(사전)에 입력했는데 이번에 인쇄해 보니 이렇게 되어 있었습니다.

이것은 사전 안의 목록 안에 있는 사전의 모습입니다. 아마도 다음과 같습니다.
{ xx:xx , xx:[ {xx:xx} , {xx:xx} , {xx: xx } , {xx:xx} ] }
빨간색으로 표시한 곳이 우리에게 필요한 정보입니다.
파란색으로 표시된 목록에 n개의 사전이 있다고 가정하면 len() 함수를 통해 n 값을 얻을 수 있고
for 루프를 사용하여 순회하여 결과를 얻을 수 있습니다.
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])
드디어
오늘의 나눔은 여기까지입니다 안녕~
안녕? 한 가지를 잊어버렸습니다. 날씨를 크롤링할 수 있는 다른 코드를 알려드리겠습니다!
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')
【관련 추천: Python3 비디오 튜토리얼】
위 내용은 한 기사로 Python 크롤러 이해하기의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!