
Oracle에서 데이터 중복을 제거하는 방법

- 青灯夜游원래의
- 2023-01-04 14:42:2513810검색
제거 방법: 1. 중복 항목을 제거하려면 고유 키워드를 사용합니다. "SELECT DISTINCT field name FROM table name;" 2. 창 함수 row_number() over()를 사용하여 중복 항목을 제거합니다. 중복 제거의 경우 구문은 "필드 이름별로 테이블 이름 그룹에서 필드 이름 선택"입니다. 4. 의사 열을 중복 제거하려면 rowid를 사용합니다.

이 튜토리얼의 운영 환경: Windows 7 시스템, Oracle 11g 버전, Dell G3 컴퓨터.
비즈니스 시나리오
특정 데이터를 쿼리해야 합니다. 관련 쿼리에는 3개의 테이블이 필요하므로 쿼리 결과는 다음과 같습니다.

원본 SQL 문
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
SELECT DISTINCT를 사용하면 결과 집합에서 중복 행을 필터링하여 SELECT 절에서 반환된 지정된 열의 값이 고유한지 확인할 수 있습니다.
DISTINCT 문의 구문은 다음과 같습니다.
SELECT DISTINCT column_1,
column_2,
...
FROM
table_name;예:
SELECT D.ORDER_NUM AS "申请单号" , D.CREATE_TIME , D.EMP_NAME AS "申请人", (SELECT extractvalue(t1.row_data,'/root/row/FI13_wasteName') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "废料名称", (SELECT extractvalue(t1.row_data,'/root/row/FI13_units') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "单位", (SELECT extractvalue(t1.row_data,'/root/row/FI13_estimate') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "预估数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdPTFLXX' ) AS "累计出库数量", (SELECT extractvalue(t1.row_data,'/root/row/FI13_receivingTime') FROM dat_table_row t1 WHERE d.document_id = t1.document_id AND t1.table_id = 'dynamicRowsIdCGYTX' ) AS "收购方收货时间", (SELECT extractvalue(t2.row_data,'/root/row/FI13_collectionTime') FROM dat_table_row t2 WHERE d.document_id = t2.document_id AND t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) AS "实际收款时间" FROM dat_document d, dat_table_row dtr WHERE d.form_name ='FI14' AND d.document_id =dtr.document_id AND (D.DOCUMENT_STATUS != 'deleted' OR D.DOCUMENT_STATUS IS NULL ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' AND d.order_num = 'FI1420210708002' --FI1420210708002 ORDER BY d.CREATE_TIME DESC;
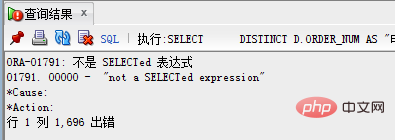
참고: Oracle은 먼저 DISTINCT를 수행하여 중복 항목을 제거한 다음 ORDER BY를 사용하여 정렬해야 합니다. 따라서 ORDER BY로 정렬해야 할 필드가 Distinct 이후의 필드에 없다면 당연히 오류가 발생하게 됩니다.
오류 메시지는 다음과 같습니다.
구문 형식
select * from (select A.*, row_number() over(partition by A.name1 order by A.name12 desc) rn from A) where rn = 1
예
select * from ( select d.order_num as "申请单号" , d.create_time , d.emp_name as "申请人", (select extractvalue(t1.row_data,'/root/row/FI13_wasteName') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "废料名称", (select extractvalue(t1.row_data,'/root/row/FI13_units') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "单位", (select extractvalue(t1.row_data,'/root/row/FI13_estimate') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "预估数量", (select extractvalue(t1.row_data,'/root/row/FI13_stockRemoval') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdPTFLXX' ) as "累计出库数量", (select extractvalue(t1.row_data,'/root/row/FI13_receivingTime') from dat_table_row t1 where d.document_id = t1.document_id and t1.table_id = 'dynamicRowsIdCGYTX' ) as "收购方收货时间", (select extractvalue(t2.row_data,'/root/row/FI13_collectionTime') from dat_table_row t2 where d.document_id = t2.document_id and t2.table_id = 'dynamicRowsIdPTSJSKSJ' ) as "实际收款时间", row_number() over(partition by d.order_num order by d.create_time desc) rn from dat_document d, dat_table_row dtr where d.form_name ='FI14' and d.document_id =dtr.document_id and (d.document_status != 'deleted' or d.document_status is null ) --AND TO_CHAR(d.create_time,'yyyy-MM-dd') BETWEEN '2020-01-01' AND '2021-03-26' and d.order_num = 'FI1420210708002' --FI1420210708002 ) where rn = 1;
쿼리 결과
방법 3 :
select 字段名 from 表名 group by 字段名;
별로 그룹화 방법 4: rowid 사용(의사 열 중복 제거)
select id,name,age from test t1 where t1.rowid in (select min(rowid) from test t2 where t1.name=t2.name and t1.age=t2.age);
권장 튜토리얼: "Oracle Tutorial"
위 내용은 Oracle에서 데이터 중복을 제거하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!