
도구 공유: 프론트엔드 매몰점 자동 관리 구현

- 青灯夜游앞으로
- 2022-12-07 16:14:382298검색

포인트 추적은 항상 H5 프로젝트의 중요한 부분이었으며, 포인트 추적 데이터는 향후 비즈니스 개선 및 기술 최적화를 위한 중요한 기반입니다. [추천 학습 : 웹 프론트엔드, 프로그래밍 교육]
제품이나 사업 분야의 학생들은 일상 업무에서 "지금 이 프로젝트의 숨겨진 포인트는 무엇입니까?", "프로그램의 숨겨진 포인트는 무엇입니까?"라고 자주 묻습니다. 이 프로젝트?" 어디서? "이런 질문은 기본적으로 코드를 한 번만 물어보고 확인하는 것이므로 매우 비효율적입니다.

이것은 매장지 자체의 성격과 관련이 있을 수 있습니다. 묻힌 포인트는 상대적으로 독립적인 기능이므로 반복이 진행됨에 따라 개발자가 묻힌 포인트의 목적을 기억하기가 어렵습니다. 자체 테스트 및 검증을 위해 개발자는 프로젝트에 숨겨진 데이터도 정리해야 합니다. 따라서 현재 시나리오와 결합하여 도구를 구현할 수 있습니다. 즉, 코드를 스캔하고 매립지와 관련된 코드를 분석하고 처리한 후 다른 관리 플랫폼에서 나중에 사용할 수 있도록 특정 데이터로 변환하는 방식입니다.
구현 아이디어
이 도구는 대략 JSDoc 매몰점 추출, 라우팅 종속성 분석 및 ESLint 플러그인의 세 부분으로 나눌 수 있습니다.
- JSDoc은 JavaScript의 주석 정보를 기반으로 API 문서를 생성하는 도구입니다. JSDoc의 이러한 기능과 결합된 이 추적 도구는 JSDoc을 핵심 부분으로 사용하여 코드에 추적 데이터를 출력합니다.
- Webpack 플러그인은 JSDoc에 대한 라우팅 정보를 제공하는 보조 역할을 합니다.
- ESLint 플러그인은 파일에 묻혀 있는 코드에 해당 JSDoc 주석이 있는지 확인하는 최종 검사로 사용됩니다.
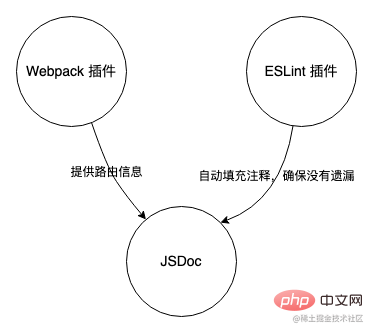
맞춤형 JSDoc 마크업 포인트
우리는 JSDoc이 코드의 주석을 기반으로 문서를 출력할 수 있다는 것을 알고 있습니다. 먼저 JSDoc 태그를 사용자 정의하여 숨겨진 주석으로 표시하여 후속 처리 중에 다른 주석의 간섭을 필터링할 수 있습니다. 특정 프로젝트에서 사용되는 코드를 조합하면 다음과 같은 흐름도를 그릴 수 있습니다.

다음은 구체적인 코드 구현 과정입니다.
JSDoc 플러그인을 작성하고 태그를 사용자 정의하세요.
// jsdoc.plugin.js
// 自定义一个 @log,含有 @log 才是埋点的注释
exports.defineTags = function (dictionary) {
dictionary.defineTag('log', {
canHaveName: true,
onTagged: function (doclet, tag) {
doclet.meta.log = tag.text;
},
});
};.ts 및 .vue 파일을 구문 분석하세요.
// jsdoc.plugin.js
exports.handlers = {
beforeParse: function (e) {
// 对文件预处理
if (/.vue/.test(e.filename)) {
// 解析 vue 文件
const component = compiler.parseComponent(e.source);
// 获取 vue 文件的 script 代码
const ast = parse.parse(component.script.content, {
// ...
});
}
if (/.ts/.test(e.filename)) {
// ts 转 js
}
},
};맞춤형 JSDoc 템플릿.
// publish.js
exports.publish = function (taffyData, opts, tutorials) {
// ...
data().each(function (doclet) {
// 有 log 这个 tag 的才是埋点注释
if (doclet.meta && doclet.meta.log) {
doclet.tags?.forEach((item) => {
// 获取对应的路由地址
});
// 拿到埋点数据
logData.push({});
}
});
// 输出 md 文档
fs.writeFileSync(outpath, mdContent, 'utf8');
};이 시점에서 코드의 모든 숨겨진 지점이 완전히 출력될 수 있습니다. 이번에는 이 도구의 현재 기능을 살펴보겠습니다.
- 매장지 정보 자동 추출 및 매장지 문서 생성: ✅
- 매장지 댓글에 사용자 정의 태그(@log) 자동 추가: ❌
- 자동으로 매장지 댓글 추가 보고된 매장지 정보 추가: ❌
- 매장지 댓글에 라우팅 정보 자동 추가: ❌
- 매장지 댓글에 매장지 설명 정보 자동 추가: ❌
- 주석 처리되지 않은 매장지 코드 자동 프롬프트: ❌
통과 위의 분석에서 알 수 있습니다.
- 매장지점에 댓글을 수동으로 추가해야 합니다
- 매장지점에 해당하는 경로를 수동으로 확인해야 합니다
- 매장지점에 댓글을 추가하는 것을 잊었다면 어떻게 되나요?
이 도구를 만든 원래 의도는 반복적이고 지루한 작업을 줄이는 것입니다. 코드에서 문서를 자동으로 입력하기 위해 다른 작업량을 추가하면 손실의 가치가 조금 더 커질 것입니다. 이러한 문제의 분석을 통해 다음과 같은 해결책을 도출할 수 있습니다.
- 각 묻힌 지점에 수동으로 주석을 추가해야 합니다. -> 코드 자동 채우기 -> ESLint 수정 기능/VSCode 플러그인
- 이 필요합니다. 각 매몰지점에 해당하는 경로를 수동으로 확인 -> 해당 컴포넌트에 해당하는 경로를 자동으로 찾기 -> Webpack 종속성 분석
- 숨겨진 지점에 대한 주석을 잊어버린 경우 어떻게 해야 하나요? -> 댓글 작성을 잊어버리면 알림이 표시됩니다. -> ESLint 플러그인
이 시점에서 문제에 대한 해결책이 명확해졌습니다. 다음으로 webpack 플러그인과 ESLint 플러그인의 구현 과정을 살펴보겠습니다.
경로 종속성 분석
webpack 자체에는 종속성 분석이 포함되어 있으며, 구성 요소 간의 상위-하위 관계를 쉽게 얻을 수 있습니다.
compiler.hooks.normalModuleFactory.tap('routeAnalysePlugin', (nmf) => {
nmf.hooks.afterResolve.tapAsync('routeAnalysePlugin', (result, callback) => {
const { resourceResolveData } = result;
// 子组件
const path = resourceResolveData.path;
// 父组件
const fatherPath = resourceResolveData.context.issuer;
// 只获取 vue 文件的依赖关系
if (/.vue/.test(path) && /.vue/.test(fatherPath)) {
// 将组件间的父子关系存到变量中
}
});
});구성요소 간의 종속성을 우리가 원하는 데이터 형식으로 넣습니다
[
{
"path": "src/views/register-v2/index.vue",
"deps": [
{
"path": "src/components/landing-banner/index.vue",
"deps": []
}
]
}
// ...
]组件之间的依赖关系有了,接下来就是找到组件和路由的对应关系,这里我们用 AST 来解析路由文件,获取路由和组件的对应关系。
// 遍历路由文件
for (let i = 0; i < this.routePaths.length; i++) {
// ...
traverse(ast, {
enter(path) {
// 找出组件和路由的对应关系
path.node.properties.forEach((item) => {
// 组件
if (item.key.name === 'component') {
}
// 路由地址
if (item.key.name === 'path') {
}
});
},
});
}同样地,把组件与路由的映射关系拼成合适的数据格式。
{
"src/views/register-v3/index.vue": "/register"
// ...
}再将路由的映射关系和组件间的依赖关系整合到一起,得出每个组件与路由的对应关系。
{
"src/components/landing-banner/index.vue": [
"/register_v2",
"/register"
//...
]
// ...
}因为使用 AST 遍历的方式来解析路由文件,目前支持的解析的路由文件写法有以下四种,基本上满足了当前的场景:
const page1 = (resolve) => {
require.ensure(
[],
() => {
resolve(require('page1.vue'));
},
'page1',
);
};
const page2 = () =>
import(
/* webpackChunkName: "page2" */
'page2.vue'
);
export default [
{ path: '/page1', component: page1 },
{ path: '/page2', component: page2 },
{
path: '/page3',
component: (resolve) => {
require.ensure(
[],
() => {
resolve(require('page3.vue'));
},
'page3',
);
},
},
{
path: '/page4',
component: () =>
import(
/* webpackChunkName: "page4" */
'page4.vue'
),
},
];
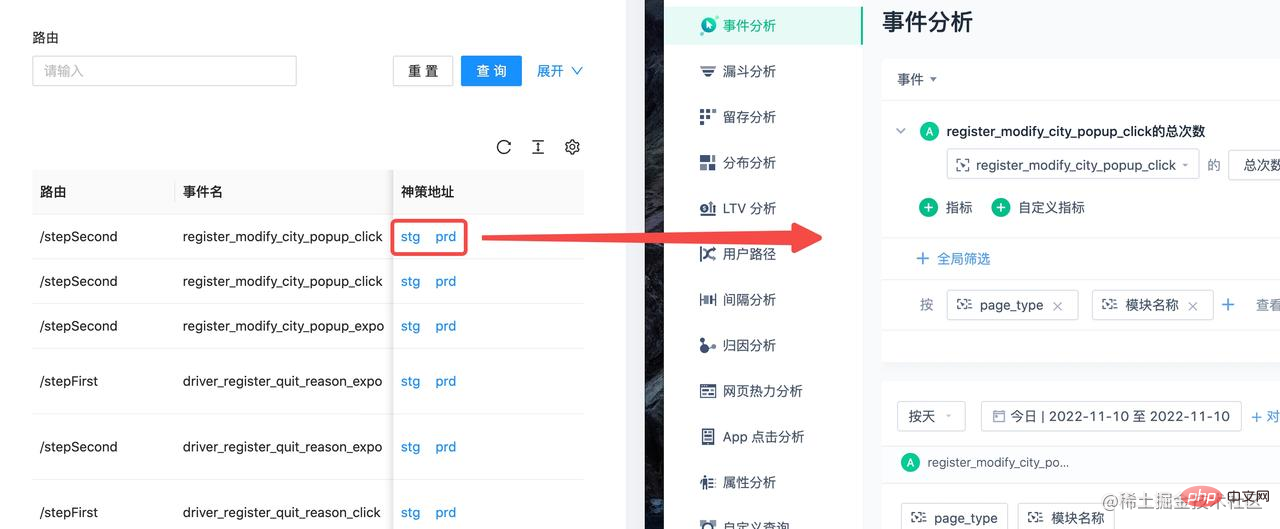
再得到了上面的对应关系之后,可以把埋点数据放到传到埋点管理平台上,从而实现一键查询:
编写 ESLint 插件
先来看看代码中埋点上报的三种方式:
// 神策 sdk
sensors.track('xxx', {});
// 挂载到 Vue 实例中
this.$sa.track('xxx', {});
// 装饰器
@SensorTrack('xxx', {})观察上面三种方式,可以知道埋点上报是通过 track 函数和 SensorTrack 函数,所以我们的 ESLint 插件对这两个函数进行校验。
function create(context) {
// 调用 track 函数的对象
const checkList = ['sensor', 'sensors', '$sa', 'sa'];
return {
Literal: function (node) {
// ...
// 调用埋点函数而缺少注释时
if (
isNoComment &&
((isTrack && isSensor) || (is$Track && isThisExpression))
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
// 使用修饰器但没有注释时
if (
callee.name === 'SensorTrack' &&
sourceCode.getCommentsBefore(node).length === 0
) {
context.report({
node,
messageId: 'missingComment',
fix: function (fixer) {
// 自动修复
},
});
}
},
};
}看下完成后的效果:
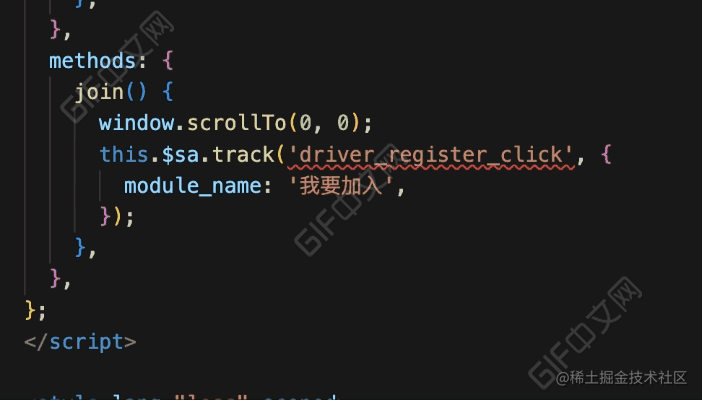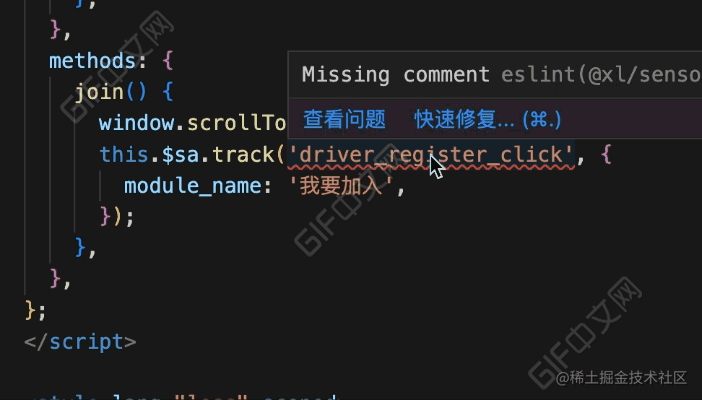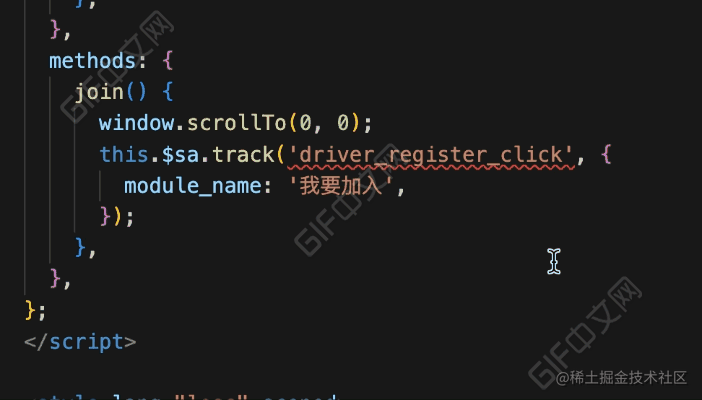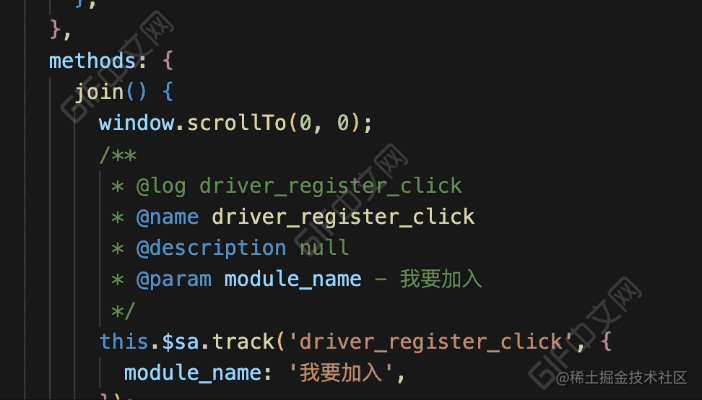
效果对比
我们再来对比下优化前后的区别:
| 优化前 | 优化后 | |
|---|---|---|
| 自动提取埋点信息,生成埋点文档 | ✅ | ✅ |
| 自动给埋点注释添加自定义 tag(@log) | ❌ | ✅ |
| 自动给埋点注释添加上报的埋点信息 | ❌ | ✅ |
| 自动给埋点注释添加路由信息 | ❌ | ✅ |
| 自动给埋点注释添加埋点描述信息 | ❌ | ❌ |
| 自动提示没有注释的埋点代码 | ❌ | ✅ |
优化之后除了整个流程基本都由工具自动完成,剩下一个埋点描述信息。因为埋点的描述信息只是为了让我们更好地理解这个埋点,本身并不在上报的代码中,所以工具没有办法自动生成,但是我们可以直接在产品提供的埋点文档中拷贝过来完成这一步。
总结
在项目中接入这个工具之后,可以快速地知道项目的埋点有哪些以及各个埋点所在的页面,也方便我们对埋点的梳理,同时利用导出的埋点数据开发后台应用,有效地提升了开发者效率。
这个工具的实现是在 JSDoc、webpack 和 ESLint 插件的加持下水到渠成的,说是水到渠成是因为一开始的想法只是做到第一步,先有个一键查询功能和能够输出一份文档用着先。但是第一版出来后发现要手动去处理这些埋点注释还是比较繁琐,恰巧平常开发中常见的 webpack 插件和 ESLint 插件可以很好地解决这些问题,于是便有路由依赖分析和 ESLint 插件。像是《牧羊少年奇幻之旅》中所说的,“如果你下定决心要做一件事情,整个宇宙都会合力帮助你。”
위 내용은 도구 공유: 프론트엔드 매몰점 자동 관리 구현의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!