
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 단일 테이블 쿼리의 고급 요약
MySQL 단일 테이블 쿼리의 고급 요약

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-12-02 17:23:352355검색
이 글은 mysql에 대한 관련 지식을 주로 소개하는 내용으로, 모두에게 도움이 되기를 바랍니다.

추천 학습: mysql 비디오 튜토리얼
쿼리 작업은 의심할 여지 없이 중요하며 개발 요구 사항에 따라 효율적인 쿼리 작업을 설계할 수 있습니다. 사용자에게.
쿼리는 데이터 작업에서 중요한 부분입니다. 예를 들어 모든 제품 중에서 특정 범위 내의 가격을 가진 모든 제품을 찾으려면 데이터베이스의 데이터를 사용자에게 표시하려고 합니다. 클라이언트에서는 일반적으로 쿼리 작업이 수행됩니다. 查询是数据操作至关重要的一部分,比如说在所有商品中查找出价格在规定范围内的所有商品,要想把数据库中的数据在客户端中展示给用户,一般都进行了查询的操作。
在实际开发中,我们要根据不同的需求,并且考虑查询的效率来决定怎样进行查询,学习查询前,可以先看看查询的完整语法:
SELECT 字段列表FROM 表名列表WHERE 条件列表GROUP BY 分组字段HAVING 分组后条件ORDER BY 排序字段LIMIT 分页限定
根据查询的完整语法中的关键字,我们分别来学习基础查询,条件查询,排序查询,分组查询和分页查询。
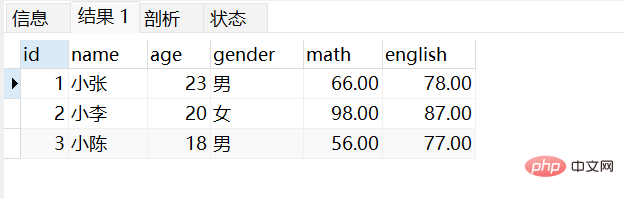
-- 删除stu表 drop table if exists stu; -- 创建stu表 CREATE TABLE stu ( id int, -- 编号 name varchar(10), -- 姓名 age int, -- 年龄 gender varchar(5), -- 性别 math double(5,2), -- 数学成绩 english double(5,2) -- 英语成绩 ); -- 添加数据 INSERT INTO stu(id,name,age,gender,math,english) VALUES (1,'小张',23,'男',66,78), (2,'小李',20,'女',98,87), (3,'小陈',55,'男',56,77), (4,'小樊',20,'女',76,65), (5,'小马',20,'男',86,NULL), (6,'小赵',57,'男',99,99);키워드에 따라 쿼리의 전체 구문에서는
기본 쿼리, 조건 쿼리, 정렬 쿼리, 그룹화 쿼리, 페이징 쿼리를 각각 학습합니다. 다음 사례를 사용하여 단일 테이블 쿼리를 학습합니다:
select 字段列表 from 表名;
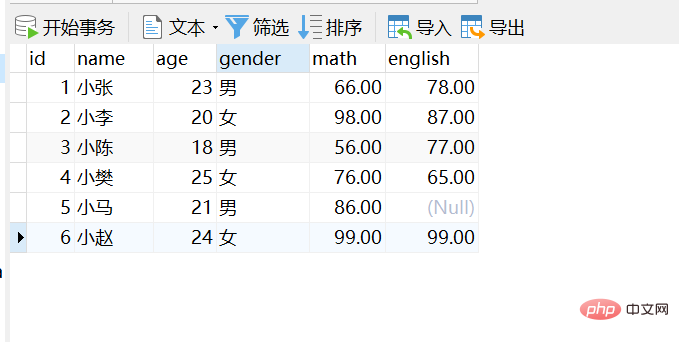 Navicat에서 SQL 실행 선택:
Navicat에서 SQL 실행 선택:1. 기본 쿼리
1.1 기본 쿼리 구문다중 필드 쿼리 :select * from 表名;모든 필드 쿼리:
select distinct 字段列表 from 表名;중복 레코드 제거:
select 字段名 别名 from 表名;
별칭 작업: select name,math from stu;
1.2 기본 쿼리 연습기본 쿼리 연습에서는 서문의 사례를 사용합니다. 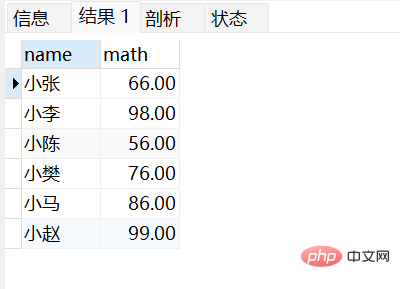 여러 쿼리 필드 연습:
여러 쿼리 필드 연습:
select name,english 英语成绩 from stu;
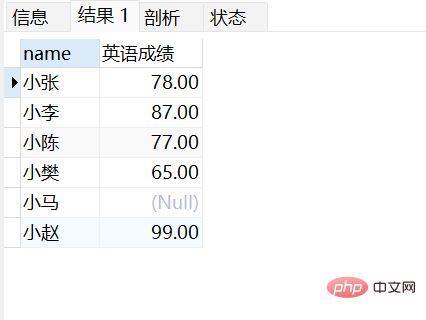 앨리어싱 작업 연습:
앨리어싱 작업 연습:
select 字段列表 from 表名 where 条件列表;
2. 조건부 쿼리
2.1 조건부 쿼리 구문일반 구문:| Operator | |
|---|---|
| …과… | |
| in(…) | |
| 는 null입니다. / null은 아닙니다 | |
| and or && | |
| or or || |
2.2 조건부 쿼리 연습 조건부 쿼리 연습에는 서문의 사례를 사용합니다.
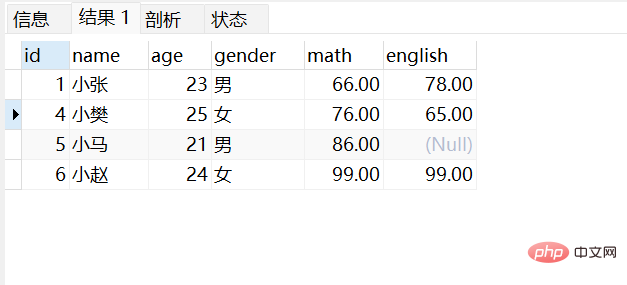 20세 이상의 학생 정보 쿼리:
20세 이상의 학생 정보 쿼리:
select * from stu where age in(18,20,21);
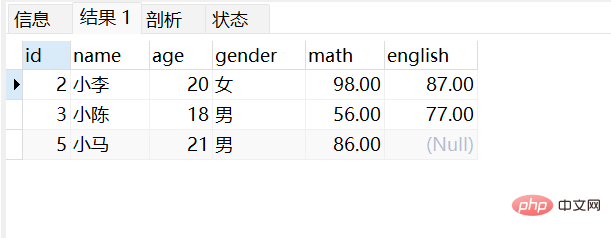 18세, 20세, 21세 학생 정보 쿼리:
18세, 20세, 21세 학생 정보 쿼리: select * from stu where name like '%张%';
- 퍼지 쿼리는 like 키워드를 사용하며 와일드카드를 자리 표시자로 사용할 수 있습니다.
- _: 임의의 단일 문자를 나타냅니다.
%: 임의 개수의 숫자를 나타냅니다.
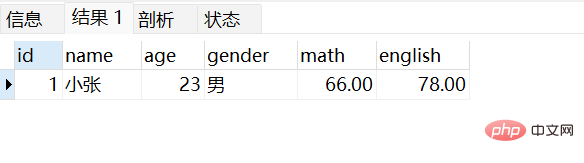 이름에 Zhang이 포함된 학생 정보 쿼리 :
이름에 Zhang이 포함된 학생 정보 쿼리 :
select 字段列表 from 表名 order by 排序字段名1 [排序方式]...;
3. 정렬 쿼리
3.1 정렬 쿼리 구문
select 聚合函数 from 表名;
참고: 정렬 방법에는 오름차순 ASC와 내림차순 DESC가 있습니다.
3.2 쿼리 정렬 연습서문의 사례를 사용하여 쿼리 정렬 연습을 합니다.
4. 집계 함수
4.1 집계 함수 구문| 함수 이름 | |
|---|---|
| count(열 이름) | |
| max(열 이름 ) | |
| min(열명) | |
| sum(열명) | |
| avg(열명) |
一般语法:
select 聚合函数 from 表名;
注:NULL值不参与聚合函数运算。
4.2 聚合函数练习
我们使用前言中的案例进行聚合函数的练习:
统计该表中一共有几个学生:
select count(id) from stu;

上面我们使用某一字段进行运算,这样做可能面临的问题是某一个值可能是NULL,所以我们一般使用 * 进行运算,因为一行中不可能所有的字段都是NULL。
select count(*) from stu;
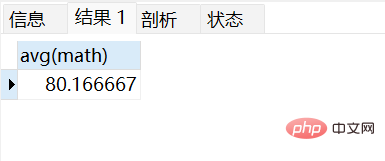
查询数学成绩的平均分:
select avg(math) from stu;
5. 分组查询
5.1 分组查询语法
select 字段列表 from 表名 [where 分组前的条件限定] group by 分组字段名 [having 分组后的条件过滤]
注:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义。
5.2 分组查询练习
我们使用前言中的案例进行分组查询练习:
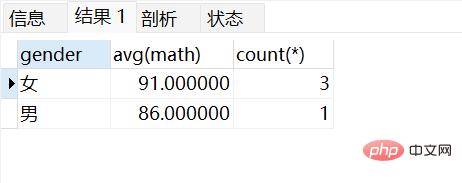
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组:
select gender, avg(math),count(*) from stu where math > 70 group by gender;
查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个的:
select gender, avg(math),count(*) from stu where math > 70 group by gender having count(*) > 2;
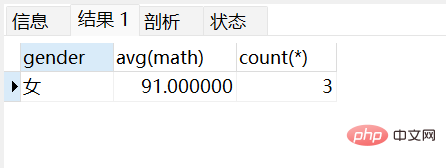
注:where 和 having 执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。所以,where 不能对聚合函数进行判断,having 可以。
6. 分页查询
6.1 分页查询语法
在大家的印象中,网页在展示大量的数据时,往往不是把数据一下全部展示出来,也是用分页展示的形式,其实就是对数据进行分页查询的操作,即每次只查询一页的数据展示到页面上。
select 字段列表 from 表名 limit 查询起始索引,查询条目数;
在 limit 关键字中,查询起始索引这个参数是从0开始的。
5.2 分页查询练习
我们使用前言中的案例进行分页查询练习:
从0开始查询,查询3条数据:
select * from stu limit 0,3;
起始索引 = (当前页码 - 1) * 每页显示的条数
推荐学习:mysql视频教程
위 내용은 MySQL 단일 테이블 쿼리의 고급 요약의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!