
집 >데이터 베이스 >MySQL 튜토리얼 >MySQL 인덱스 최적화 프로그램의 작동 방식에 대한 심층적인 이해
MySQL 인덱스 최적화 프로그램의 작동 방식에 대한 심층적인 이해

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-11-09 14:05:241719검색
이 기사에서는 mysql에 대한 관련 지식을 제공합니다. MySQL 서버의 구성, MySQL 옵티마이저에 의한 인덱스 선택 원리 및 SQL 비용 분석 등 인덱스 옵티마이저의 작동 원리에 대한 관련 내용을 주로 소개하고 마지막으로 전체 쿼리 과정을 Select 쿼리를 통해 요약해 보도록 하겠습니다. 모두에게 도움이 되기를 바랍니다.

추천 학습: mysql 동영상 튜토리얼
1. MySQL 옵티마이저가 인덱스를 선택하는 방법
이 테이블을 살펴보겠습니다. SUB_ODR_ID 필드는 앞서 말한 내용에 따라 2개의 관련 인덱스를 생성합니다. 우리는 PRIMARY KEY(ID)自增主键索引,(LOG_ID, SUB_ODR_ID)를 생성하고 이를 공동 인덱스와 고유 인덱스로 설정하고 CREATE_TIME 및 UPDATE_TIME이라는 두 개의 인덱스를 두 번 설정한다는 것을 배웠습니다.
CREATE TABLE `***` ( `ID` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `LOG_ID` varchar(32) NOT NULL COMMENT '交易流水号', `ODR_ID` varchar(32) NOT NULL COMMENT '父单号', `SUB_ODR_ID` varchar(32) NOT NULL COMMENT '子单号', `CREATE_TIME` datetime(0) NOT NULL COMMENT '创建时间', `CREATE_BY` varchar(32) NOT NULL COMMENT ' 创建人', `UPDATE_TIME` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间', `UPDATE_BY` varchar(32) NOT NULL COMMENT '更新人', PRIMARY KEY (`ID`) USING BTREE, UNIQUE INDEX `UNQ_LOG_SUBODR_ID`(`LOG_ID`, `SUB_ODR_ID`) USING BTREE, INDEX `IDX_ODR_ID`(`ODR_ID`) USING BTREE, INDEX `IDX_SUB_ID`(`SUB_ODR_ID`) USING BTREE, INDEX `IDX_CREATE_TIME`(`CREATE_TIME`) USING BTREE, INDEX `IDX_UPDATE_TIME`(`UPDATE_TIME`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1 SET = utf8 COLLATE = utf8_general_ci COMMENT = '分摊业务明细表' ROW_FORMAT = Dynamic;
쿼리 필드 SUB_ODR_ID에서는 이론적으로 UNQ_LOG_SUBODR_ID, IDX_SUB_ID라는 세 가지 관련 인덱스를 사용할 수 있습니다. MySQL 최적화 프로그램은 이 세 가지 인덱스 중에서 어떻게 선택합니까?
관계형 데이터베이스에서 B+ 트리는 저장에 사용되는 데이터 구조일 뿐입니다.
사용 방법은 데이터베이스의 최적화 프로그램에 따라 다릅니다. 최적화 프로그램은 실행 계획이라고 알려진 특정 인덱스의 선택을 결정합니다. 옵티마이저 선택은 비용을 기준으로 하며, 비용이 낮을수록 선호도 지수가 높아집니다.
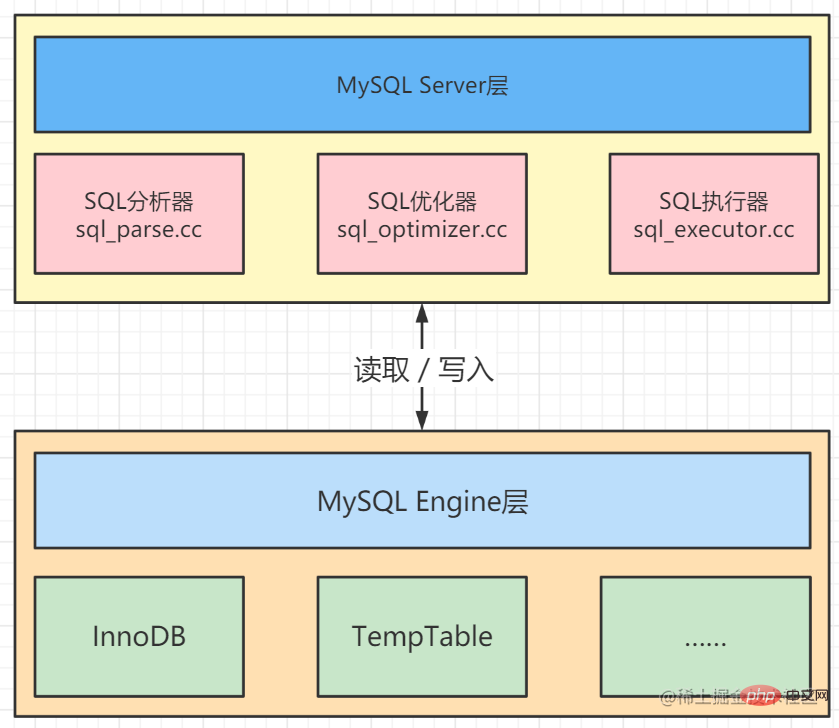
1. MySQL 데이터베이스 구성
MySQL 데이터베이스는 Server(서버) 계층과 Engine(엔진) 계층으로 구성됩니다.
서브 계층에는 SQL 문의 특정 실행 프로세스를 담당하는 SQL 분석기, SQL 최적화 프로그램 및 SQL 실행 프로그램이 있습니다.
엔진 레이어는 가장 일반적으로 사용되는 InnoDB 스토리지 엔진, 임시 결과 세트를 메모리에 저장하는 데 사용되는 TempTable 엔진 등 특정 데이터를 저장하는 역할을 담당합니다.
SQL 최적화 프로그램은 가능한 모든 실행 계획을 분석하고 가장 낮은 비용의 실행을 선택합니다. 이 옵티마이저를 CBO(비용 기반 옵티마이저)라고 합니다.
2. MySQL 데이터베이스 비용 계산
MySQL에서 SQL의 계산 비용은 데이터베이스 액세스(데이터베이스 페이지, 디스크) + 데이터 처리라는 것을 이해하기 쉽습니다.
CPU 비용. 인덱스 키 값 비교, 레코드 값 비교, 결과 집합 정렬 등의 계산 비용을 나타냅니다. 이러한 작업은 엔진 수준 IO 비용을 나타내는 서버 계층
IO 비용에서 완료됩니다. MySQL 8.0은 테이블 데이터가 메모리에 있는지 구별하여 메모리 IO와 디스크 IO를 읽는 비용을 별도로 계산할 수 있습니다.
Cost = Server Cost + Engine Cost = CPU Cost + IO Cost
MySQL 옵티마이저는 SQL 조각이 디스크 기반 임시 테이블을 생성해야 하는 경우 이때 비용이 가장 크며 이는 메모리 기반 임시 테이블의 20배라고 믿습니다. 인덱스 키 값과 레코드를 비교하는 비용은 매우 낮지만, 비교할 레코드가 많으면 비용이 매우 높을 수 있습니다.
MySQL 최적화 프로그램은 디스크에서 읽는 비용이 메모리 비용의 4배라고 믿습니다(비용은 고정되어 있지 않으며 하드웨어에 따라 달라질 수 있음).
2. MySQL 쿼리 비용
MySQL 옵티마이저의 각 비용 값과 작동 원리를 확인하고 SQL 실행 비용을 기준으로 MySQL 인덱스 선택을 분석합니다.
read_cost는 InnoDB 스토리지 엔진의 읽기 비용을 의미합니다. eval_cost는 서버 계층의 CPU 비용을 나타냅니다. prefix_cost는 SQL의 총 비용을 나타냅니다. data_read_per_join은 읽기 레코드의 총 바이트 수를 나타냅니다.EXPLAIN FORMAT=json select * from test.fork_business_detail f where f.sub_odr_id = ''
3. SELECT 실행 프로세스
MySQL 쿼리 성능을 향상시키는 방법은 무엇입니까? 먼저, 쿼리 최적화 프로그램이 SQL을 처리하는 전체 과정을 이해해야 합니다. SELECT SQL의 실행과정은 아래 그림과 같습니다.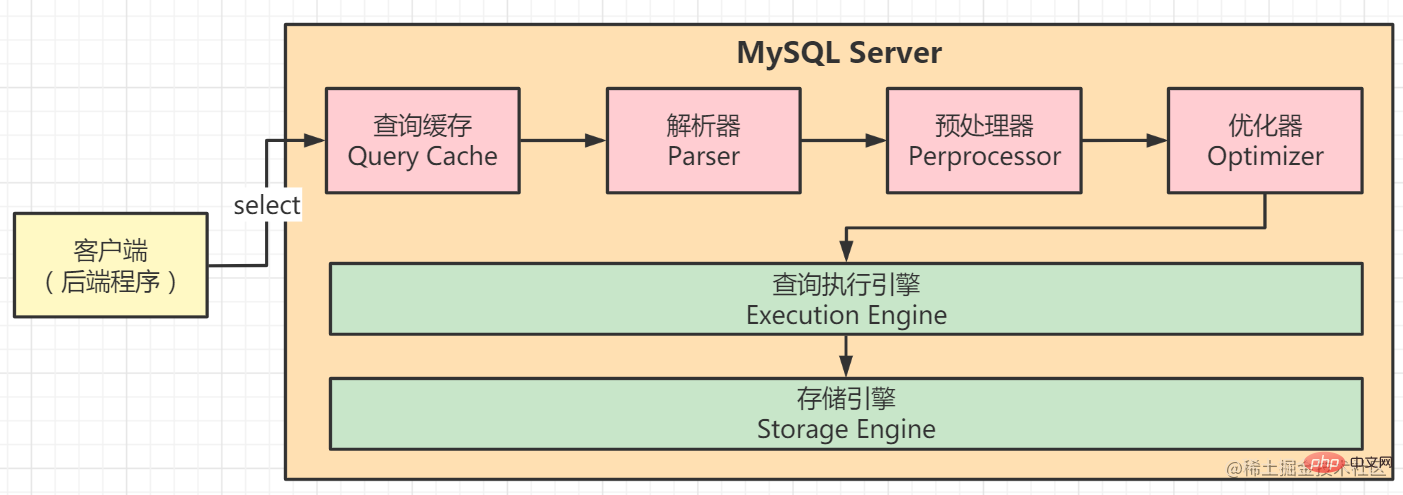
위 내용은 MySQL 인덱스 최적화 프로그램의 작동 방식에 대한 심층적인 이해의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!