
인터페이스 멱등성을 처리하기 위한 Redis의 두 가지 솔루션에 대해 간략하게 이야기해 보겠습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-08-18 17:57:112803검색

추천 학습: Redis 동영상 튜토리얼
서문: 인터페이스 멱등성 문제는 개발자를 위한 언어와는 아무런 관련이 없는 공개 문제입니다. 일부 사용자 요청의 경우 경우에 따라 반복적으로 전송될 수 있습니다. 쿼리 작업인 경우에는 큰 문제가 아니지만 일부는 쓰기 작업이 반복되면 트랜잭션과 같은 심각한 결과를 초래할 수 있습니다. 인터페이스를 반복적으로 요청하는 경우 반복해서 주문할 수 있습니다. 인터페이스 멱등성은 동일한 작업에 대해 사용자가 시작한 하나의 요청 또는 여러 요청의 결과가 일관되며 여러 번의 클릭으로 인한 부작용이 없음을 의미합니다. 接口幂等性问题,对于开发人员来说,是一个跟语言无关的公共问题。对于一些用户请求,在某些情况下是可能重复发送的,如果是查询类操作并无大碍,但其中有些是涉及写入操作的,一旦重复了,可能会导致很严重的后果,例如交易的接口如果重复请求可能会重复下单。接口幂等性是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
一、接口幂等性
1.1、什么是接口幂等性
在HTTP/1.1中,对幂等性进行了定义。它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果,即第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。这里的副作用是不会对结果产生破坏或者产生不可预料的结果。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
这类问题多发于接口的:
-
insert操作,这种情况下多次请求,可能会产生重复数据。 -
update操作,如果只是单纯的更新数据,比如:update user set status=1 where id=1,是没有问题的。如果还有计算,比如:update user set status=status+1 where id=1,这种情况下多次请求,可能会导致数据错误。
1.2、为什么需要实现幂等性
在接口调用时一般情况下都能正常返回信息不会重复提交,不过在遇见以下情况时可以就会出现问题,如:
- 前端重复提交表单: 在填写一些表格时候,用户填写完成提交,很多时候会因网络波动没有及时对用户做出提交成功响应,致使用户认为没有成功提交,然后一直点提交按钮,这时就会发生重复提交表单请求。
- 用户恶意进行刷单: 例如在实现用户投票这种功能时,如果用户针对一个用户进行重复提交投票,这样会导致接口接收到用户重复提交的投票信息,这样会使投票结果与事实严重不符。
- 接口超时重复提交: 很多时候 HTTP 客户端工具都默认开启超时重试的机制,尤其是第三方调用接口时候,为了防止网络波动超时等造成的请求失败,都会添加重试机制,导致一个请求提交多次。
- 消息进行重复消费: 当使用 MQ 消息中间件时候,如果发生消息中间件出现错误未及时提交消费信息,导致发生重复消费。
本文讨论的是如何在服务端优雅地统一处理这种接口幂等性情况,如何禁止用户重复点击等客户端操作不在此次讨论范围。
1.3、引入幂等性后对系统的影响
幂等性是为了简化客户端逻辑处理,能放置重复提交等操作,但却增加了服务端的逻辑复杂性和成本,其主要是:
- 把并行执行的功能改为串行执行,降低了执行效率。
- 增加了额外控制幂等的业务逻辑,复杂化了业务功能;
所以在使用时候需要考虑是否引入幂等性的必要性,根据实际业务场景具体分析,除了业务上的特殊要求外,一般情况下不需要引入的接口幂等性。
二、如何设计幂等
幂等意味着一条请求的唯一性。不管是你哪个方案去设计幂等,都需要一个全局唯一的ID ,去标记这个请求是独一无二的。
- 如果你是利用唯一索引控制幂等,那唯一索引是唯一的
- 如果你是利用数据库主键控制幂等,那主键是唯一的
- 如果你是悲观锁的方式,底层标记还是全局唯一的ID
2.1、全局的唯一性ID
全局唯一性ID,我们怎么去生成呢?你可以回想下,数据库主键Id怎么生成的呢?
是的,我们可以使用UUID
1. 인터페이스 멱등성
1.1. 인터페이스 멱등성이란 무엇입니까
HTTP/1.1에서는 멱등성을 정의합니다. 리소스에 대한 하나 이상의 요청은 리소스 자체에 대해 동일한 결과를 가져야 함을 설명합니다. 즉, 첫 번째 요청은 리소스에 부작용이 있지만 후속 요청은 리소스에 부작용이 없습니다. 여기서 나타나는 부작용은 결과를 손상시키거나 예측할 수 없는 결과를 초래하지 않습니다. 즉, 여러 번 실행하면 리소스 자체에 한 번의 실행과 동일한 영향을 미칩니다. 🎜🎜이 유형의 문제는 인터페이스에서 자주 발생합니다: 🎜-
삽입이 경우 여러 요청으로 인해 중복 데이터가 생성될 수 있습니다. -
update작업, 데이터만 업데이트하는 경우(예:update user set status=1 where id=1) 문제가 없습니다.update user set status=status+1 where id=1와 같은 계산이 있는 경우 이 경우 여러 요청으로 인해 데이터 오류가 발생할 수 있습니다.
1.2.멱등성을 구현해야 하는 이유는 무엇인가요?
🎜일반적으로 인터페이스가 호출되면 정보가 정상적으로 반환될 수 있습니다. 그러나 다음과 같은 상황에 직면하면 문제가 발생할 수 있습니다: 🎜- 프런트 엔드에서 양식을 반복적으로 제출: 일부 양식을 작성할 때 사용자가 제출을 완료하고 종종 실패합니다. 네트워크 변동으로 인해 사용자에게 제때에 응답하기 위해 사용자는 제출이 성공하지 못했다고 생각하고 계속 제출 버튼을 클릭하게 됩니다.
- 사용자의 악의적인 스와이프 주문: 예를 들어 사용자 투표 기능을 구현할 때 사용자가 사용자에 대해 반복적으로 투표를 제출하면 인터페이스는 사용자가 반복적으로 제출한 투표 정보를 수신하게 됩니다. 투표 결과는 사실과 심각하게 불일치합니다.
- 인터페이스 시간 초과 및 반복 제출: 많은 HTTP 클라이언트 도구는 특히 제3자가 인터페이스를 호출할 때 네트워크 변동, 시간 초과 등으로 인한 요청 실패를 방지하기 위해 기본적으로 시간 초과 재시도 메커니즘을 활성화합니다. 재시도 메커니즘이 추가되어 요청이 여러 번 제출됩니다.
- 메시지의 반복 소비: MQ 메시지 미들웨어 사용 시, 메시지 미들웨어에 오류가 발생하여 소비 정보가 제때 제출되지 않으면 반복 소비가 발생합니다.
1.3. 멱등성 도입 후 시스템에 미치는 영향
🎜멱등성은 클라이언트 논리 처리를 단순화하고 반복 제출과 같은 작업을 배치할 수 있지만 서비스 논리 복잡성과 터미널 비용은 주로 다음과 같습니다. 🎜- 병렬 실행 기능을 직렬 실행으로 변경하면 실행 효율성이 떨어집니다.
- 멱등성을 제어하기 위해 추가 비즈니스 로직을 추가하여 비즈니스 기능을 복잡하게 했습니다.
2. 멱등성을 설계하는 방법
🎜불능은 요청의 고유성을 의미합니다. 멱등성을 설계하기 위해 어떤 솔루션을 선택하든 이 요청을 고유한 것으로 표시하려면 전역적으로 고유한 ID가 필요합니다. 🎜- 멱등성을 제어하기 위해 고유 인덱스를 사용하는 경우 고유 인덱스는 고유합니다
- 멱등성을 제어하기 위해 데이터베이스 기본 키를 사용하는 경우 기본 키는 고유합니다 비관적 잠금을 사용하는 경우 기본 태그는 여전히 전역 고유 ID입니다.
2.1 전역 고유 ID
🎜전역 고유 ID입니다. , 어떻게 생성합니까? 데이터베이스 기본 키 ID가 어떻게 생성되는지 생각해 볼 수 있습니다. 🎜🎜예,UUID를 사용할 수 있지만 UUID의 단점은 문자열이 많은 공간을 차지하고 생성된 ID가 너무 무작위적이며 가독성이 좋지 않고 증가하지 않는다는 점입니다. 🎜눈송이 알고리즘(Snowflake)을 사용하여 고유 ID를 생성할 수도 있습니다. 雪花算法(Snowflake) 生成唯一性ID。
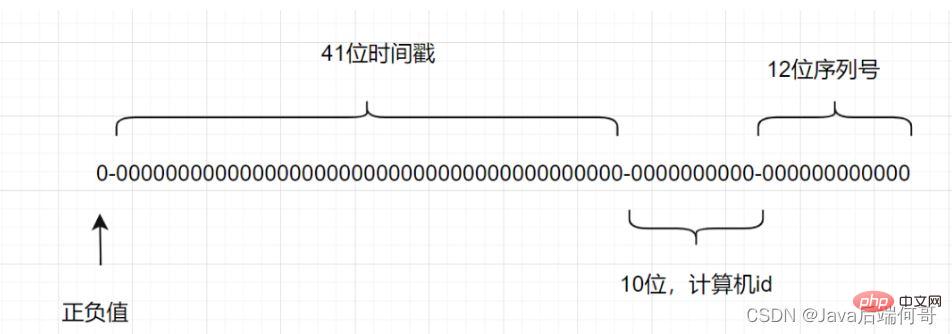
雪花算法是一种生成分布式全局唯一ID的算法,生成的ID称为Snowflake IDs。这种算法由Twitter创建,并用于推文的ID。
一个Snowflake ID有64位。
- 第1位:Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 接下来前41位是时间戳,表示了自选定的时期以来的毫秒数。
- 接下来的10位代表计算机ID,防止冲突。
- 其余12位代表每台机器上生成ID的序列号,这允许在同一毫秒内创建多个Snowflake ID。
当然,全局唯一性的ID,还可以使用百度的Uidgenerator,或者美团的Leaf。
2.2、幂等设计的基本流程
幂等处理的过程,说到底其实就是过滤一下已经收到的请求,当然,请求一定要有一个全局唯一的ID标记
Snowflake ID라고 합니다. 이 알고리즘은 Twitter에서 만들었으며 트윗 ID에 사용됩니다. Snowflake ID는 64비트입니다. 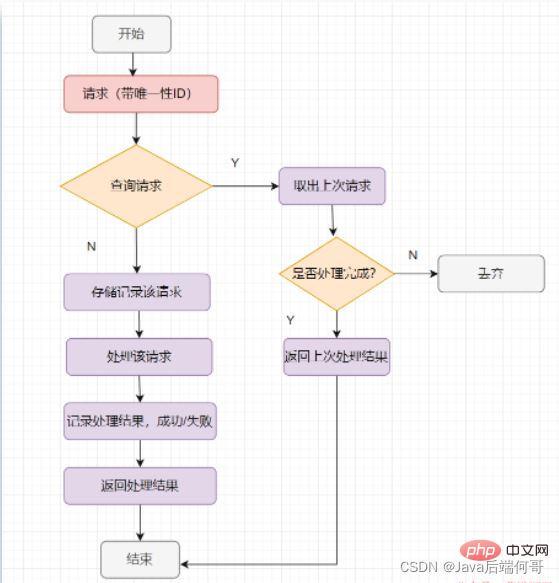
다음 10자리는 충돌 방지를 위한 컴퓨터 ID를 나타냅니다.
나머지 12비트는 ID가 생성된 각 컴퓨터의 일련 번호를 나타내며, 이를 통해 동일한 밀리초 내에 여러 Snowflake ID를 생성할 수 있습니다.
물론 전역적으로 고유한 ID인 Baidu의 Uidgenerator 또는 Meituan의 Leaf를 사용할 수도 있습니다.
- 최종 분석에서 멱등성 처리 프로세스는 수신된 요청을 필터링하는 것입니다. 물론 요청에는
전역 고유 ID 태그가 있어야 합니다. >하. 그렇다면 이전에 요청을 받은 적이 있는지 확인하는 방법은 무엇입니까? 요청을 저장하면 먼저 저장 기록을 확인하고, 기록이 존재하지 않으면 마지막 결과를 반환합니다. - 일반적인 멱등성 처리는 다음과 같습니다.
- 3. 인터페이스 멱등성에 대한 일반적인 솔루션
- 3.1. 고유 요청 번호를 다운스트림으로 전달
- 소위 고유 요청 시퀀스 번호는 실제로 서버에 요청이 이루어질 때마다 짧은 시간 내에 고유하고 반복되지 않는 시퀀스 번호가 동반되는 것을 의미합니다. 일반적으로 다운스트림에서 생성되는 순차 ID 또는 주문 번호일 수 있으며, 업스트림 서버 인터페이스를 호출할 때 인증에 사용되는 일련번호와 ID가 추가됩니다.
- 업스트림 서버는 요청 정보를 수신하면 일련번호와 다운스트림 인증 ID를 결합하여 Redis를 운영하기 위한 Key를 형성한 후, 이에 따라 Redis에 해당 Key에 대한 키-값 쌍이 있는지 쿼리합니다. 결과:
존재하는 경우 일련번호에 대한 다운스트림 요청이 처리되었음을 의미하며, 이때 반복 요청의 오류 메시지에 직접 응답할 수 있습니다.
존재하지 않는 경우 키를 Redis의 키로 사용하고, 다운스트림 키 정보를 저장된 값(예: 다운스트림 공급자가 전달한 일부 비즈니스 로직 정보)으로 사용하고, 키-값 쌍을 Redis에 저장하고, 그런 다음 일반적으로 비즈니스 로직에 대한 대응을 실행합니다. 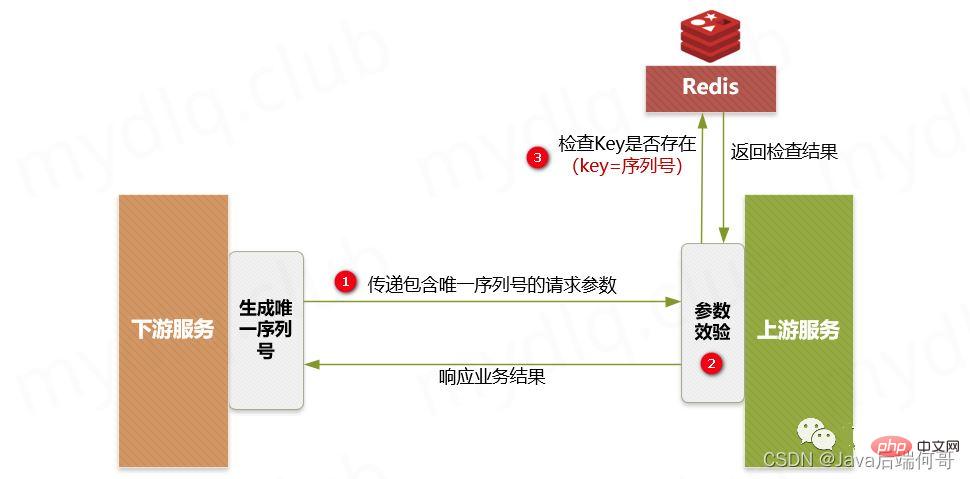
적용 가능한 작업:
- 삽입 작업
- 업데이트 작업
- 삭제 작업
사용 제한:
제3자가 고유 일련 번호를 전달해야 합니다.
제3자 구성 요소를 사용해야 합니다. 데이터 검증을 위한 Redis주요 프로세스:
🎜🎜🎜🎜 주요 단계: 🎜🎜🎜 다운스트림 서비스는 일련번호로 분산 ID를 생성한 다음 "고유 인터페이스"와 함께 업스트림 인터페이스를 호출하는 요청을 실행합니다. 일련 번호" 및 요청된 "인증 자격증명 ID"입니다. 🎜🎜 업스트림 서비스는 보안 검증을 수행하고 다운스트림으로 전달된 매개변수에 "일련번호" 및 "자격 증명 ID"가 존재하는지 감지합니다. 🎜🎜 업스트림 서비스는 Redis에 해당 "일련번호"와 "인증 ID"로 구성된 Key가 있는지 감지하고, 존재하는 경우 반복 실행 예외 메시지를 발생시킨 후 해당 오류 메시지에 응답합니다. 하류. 존재하지 않는 경우 "일련번호"와 "인증 ID"의 조합을 Key로 사용하고 다운스트림 키 정보를 Value로 사용하여 Redis에 저장한 후 후속 비즈니스 로직을 수행합니다. 정상적으로 실행됩니다. 🎜🎜🎜위 단계에서 Redis에 데이터를 삽입할 때 만료 시간을 설정해야 합니다. 이렇게 하면 이 시간 범위 내에서 인터페이스가 반복적으로 호출되는 경우 판단 및 식별이 이루어질 수 있습니다. 만료 시간을 설정하지 않으면 Redis에 무제한의 데이터가 저장되어 Redis가 제대로 작동하지 않을 가능성이 있습니다. 🎜🎜🎜3.2.중복 방지 토큰 토큰🎜🎜🎜프로젝트 설명: 🎜🎜주문 제출과 같은 클라이언트의 연속 클릭 또는 호출자의 시간 초과 재시도를 고려하여 이 작업은 토큰 메커니즘을 사용하여 반복 제출을 방지할 수 있습니다. 간단히 말하면 호출자는 인터페이스를 호출할 때 먼저 백엔드에서 글로벌 ID(토큰)를 요청하고 요청과 함께 이 글로벌 ID를 전달합니다(토큰을 헤더에 넣는 것이 가장 좋습니다). Key로서 Key 값 내용 확인을 위해 사용자 정보를 Value로 Redis에 전달하며, Key가 존재하고 Value가 일치하면 삭제 명령이 실행된 후 후속 비즈니스 로직이 정상적으로 실행됩니다. 해당 키가 없거나 값이 일치하지 않으면 멱등성 작업을 보장하기 위해 반복되는 오류 메시지가 반환됩니다. 🎜사용 제한:
- 전역적으로 고유한 토큰 문자열을 생성해야 합니다.
- 데이터 검증을 위해 타사 구성 요소 Redis를 사용해야 합니다.
주요 프로세스:
서버는 토큰을 얻기 위한 인터페이스를 제공합니다. 이는 시퀀스 번호일 수도 있고 분산 ID 또는 UUID 문자열일 수도 있습니다.
클라이언트는 토큰을 얻기 위해 인터페이스를 호출합니다. 이때 서버는 토큰 문자열을 생성합니다.
그런 다음 토큰을 Redis 키로 사용하여 Redis 데이터베이스에 문자열을 저장합니다(만료 시간 참고).
클라이언트가 토큰을 받은 후에는 양식의 숨겨진 필드에 저장해야 합니다.
클라이언트가 양식을 실행하고 제출할 때 토큰을 헤더에 저장하고 비즈니스 요청을 실행할 때 헤더를 전달합니다.
서버는 요청을 받은 후 헤더로부터 토큰을 가져온 후, 토큰을 기반으로 Redis에 키가 존재하는지 확인합니다.
서버는 Redis에 키가 있는지 확인합니다. 키가 있으면 삭제한 후 정상적으로 비즈니스 로직을 실행합니다. 존재하지 않는 경우 예외가 발생하고 반복 제출에 대한 오류 메시지가 반환됩니다.
동시 조건에서 Redis 데이터 검색 및 삭제를 실행하려면 원자성을 보장해야 합니다. 그렇지 않으면 동시성에서 멱등성이 보장되지 않을 수 있습니다. 구현에서는 분산 잠금을 사용하거나 Lua 표현식을 사용하여 쿼리를 로그아웃하고 작업을 삭제할 수 있습니다.
추천 학습: Redis 비디오 튜토리얼
위 내용은 인터페이스 멱등성을 처리하기 위한 Redis의 두 가지 솔루션에 대해 간략하게 이야기해 보겠습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!