
Oracle 아키텍처에 대한 간략한 분석

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-07-22 16:51:372138검색
이 기사에서는 Oracle에 대한 관련 지식을 제공하며, 주로 아키텍처와 관련된 문제를 정리합니다. Oracle의 아키텍처는 일반적으로 인스턴스(인스턴스)와 데이터베이스(데이터베이스)의 두 부분으로 나누어지며, 다음과 같이 살펴보겠습니다. 모두를 돕습니다.

추천 튜토리얼: "Oracle Video Tutorial"
Oracle의 아키텍처는 일반적으로 Instance(인스턴스)와 Database(데이터베이스)의 두 부분으로 나뉩니다.
그림 1과 같이:
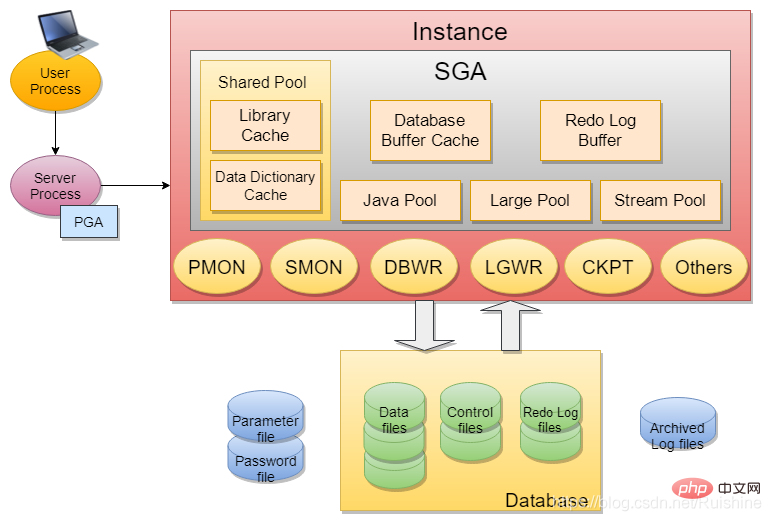
그림 1 Oracle 데이터베이스 아키텍처
우리가 일반적으로 Oracle Server(Oracle 서버)라고 부르는 것은 그림 2와 같이 Oracle 인스턴스와 Oracle Database로 구성됩니다.
그림 2 Oracle Server
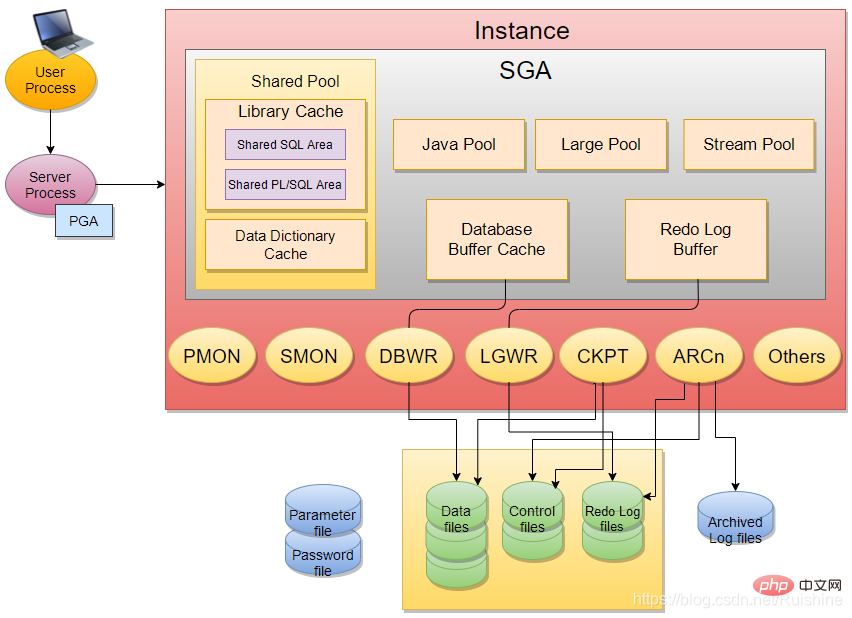
Oracle InstanceInstance에는 주로 SGA 및 일부 백그로우드 프로세스(예: PMON, SMON, DBWR, LGWR, CKPT 등)가 포함됩니다.
SGA
SGA에는 6가지 기본 구성 요소가 포함되어 있습니다: 공유 풀(라이브러리 캐시, 데이터 사전 캐시), 데이터베이스 버퍼 캐시, 리두 로그 버퍼, Java 풀, 대형 풀, 스트림 풀.
이 6가지 기본 구성 요소의 기능은 아래에서 소개됩니다.
1) 공유 풀
- 공유 풀은 SQL 및 PL/SQL 프로그램의 구문 분석, 컴파일, 실행을 위한 메모리 영역입니다.
- 공유 풀은 Library Cache(라이브러리 캐시), Data Dictionary Cache(데이터 사전 캐시), Server Result Cache(결과 캐시)로 구성됩니다.
그 기능은 무엇인가요?
라이브러리 캐시: 모든 사용자가 공유할 수 있도록 컴파일되고 구문 분석된 SQL 및 PL/SQL 문의 내용을 저장하는 SQL 및 PL/SQL용 구문 분석 장소입니다.
* 다음에 동일한 SQL 문을 실행하면 구문 분석할 필요 없이 라이브러리 캐시에서 즉시 실행됩니다.
* 라이브러리 캐시의 크기에 따라 SQL 문을 컴파일하고 구문 분석하는 빈도가 결정되어 성능이 결정됩니다.
* 라이브러리 캐시에는 공유 SQL 영역과 공유 PL/SQL 영역의 두 부분이 포함됩니다.
데이터 사전 캐시: 데이터베이스 사용을 위한 중요한 데이터 사전 정보를 저장합니다.
* 데이터 사전은 가장 자주 사용되며 거의 모든 작업에 데이터 사전 쿼리가 필요합니다. Data Dictionary 접근 속도를 향상시키기 위해서는 이때 Cache가 필요하며, 필요할 때 메모리에 접근할 수 있다.
* 데이터 사전 캐시의 정보에는 데이터베이스 파일, 테이블, 인덱스, 열, 사용자, 권한 및 기타 데이터베이스 개체가 포함됩니다.
서버 결과 캐시: 서버측 SQL 결과 세트와 PL/SQL 함수 반환 값을 저장합니다.
위 설명을 읽어보시면 다소 추상적이라고 느끼실 수 있으니 아래 예를 통해 설명하겠습니다.
클라이언트에 다음과 같은 명령이 제출되었다고 가정해 보겠습니다.
SELECT ename,sal FROM emp WHERE empno=7788;
이 명령문이 처음으로 데이터베이스에 제출되면 구문 분석이 필요합니다. 구문 분석 프로세스는 하드 구문 분석과 소프트 구문 분석으로 구분됩니다.
- 하드 파싱: 구문, 의미, 권한을 확인하고 바인드 변수 등을 분석하여 최종 실행 계획을 생성합니다.
- 소프트 파싱: 실행 계획에 따라 구체적으로 실행합니다. select 문인 경우 실행 후 결과 집합이 반환됩니다. 업데이트 또는 삭제 문인 경우 결과 집합을 반환할 필요가 없습니다.
라이브러리 캐시는 이 SQL 문과 실행 계획을 여기에 로드합니다.
이런 것들을 설치하는 목적은 무엇인가요?
다음번에 같은 문장을 입력할 때(구두점, 대문자, 공백이 정확히 동일함) 하드 파싱을 할 필요가 없습니다.
빠른 질문과 대답:
클라이언트가 이때 다른 명령을 제출하는 경우:
select ename,sal from emp where empno=7788;
맞아요, 이 명령문을 구문 분석해야 합니까?
답변: 그렇습니다.
팁: 구문 분석을 방지하려면 문이 정확히 동일해야 합니다. 구두점, 대문자, 공백 등이 정확히 동일해야 합니다! 정기적인 글쓰기의 이점이 여기에 반영됩니다.
앞서 언급했듯이 select 문인 경우 실행 후 결과 집합이 반환됩니다. 결과 세트는 어디에 저장되나요?
select ename,sal from emp where empno=7788;
이 명령문을 실행하여 반환된 결과 집합은 서버 결과 캐시에 저장됩니다.
2) 데이터베이스 버퍼 캐시
- Database Buffer Cache用于存储从磁盘数据文件中读入的数据,为所有用户共享。
- Server Process(服务器进程)将读入的数据保存在数据缓冲区中,当后续的请求需要这些数据时可以在内存中找到,则不需要再从磁盘读取。
小说明:逻辑读(从内存读)的速度是物理读(从磁盘读)的1万倍呦,所以还是想办法尽量多从内存读哦。
所以,数据缓冲区的大小对数据库的读取速度有直接的影响。
例如用户访问一个表里面的记录时,数据库接收到这个请求后,首先会在Database Buffer Cache中查找是否存在该数据库表的记录,如果有所需的记录就直接从内存中读取该记录返回给用户(有效提升了访问的速度),否则只能去磁盘上去读取。
继续看上面的例子:
select ename,sal from emp where empno=7788;
该条语句以及它的执行计划被放在Library Cache里,但语句涉及到的数据,会放在 Database Buffer Cache 里。
小问答:
Database Buffer Cache是怎么工作的呢?
这就要说一说Database Buffer Cache的设计思想了。
磁盘上存储的是块(block),文件都有文件号,块也有块号。
若要访问磁盘上的块,并不是CPU拿到指令后直接访问磁盘,而是先把块读到内存中的Database Buffer cache里,生成副本,查询或增删改都是对内存中的副本进行操作。如图3所示。
另外,如果是增删操作,操作后会形成脏块,脏块会在恰当时机再写回磁盘原位置,注意哦,可不是立刻写回呦。
也许你会问,为什么不立刻写回呢?
因为:
(1)减少物理IO;
(2)可共享,若后面又有对该块的访问,可直接在内存中进行逻辑读。
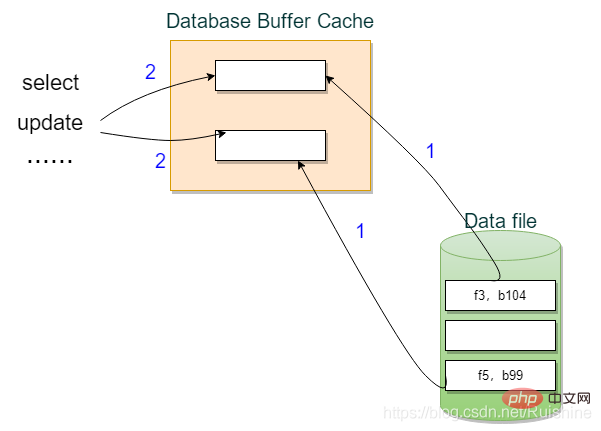
图3 访问数据块
小问答:
为什么要通过内存访问数据块,而不是CPU直接访问磁盘呢?
答:因为相较于CPU,IO的速度实在是太慢了,CPU的速度是IO 的100万倍呢?如果CPU直接访问磁盘的话,会造成大量的IO等待,CPU的利用率会很低。所以,利用速度相当的内存(CPU速度为内存的100倍)做中间缓存,可以有效减少物理IO,提高CPU利用率。
但是,这里会有一个问题。前面说到查询或增删改都是对内存中的副本进行操作,当增删改操作产生脏块时不会立刻写回磁盘。
小问答:
我们设想一下,如果在 Database Buffer Cache 中存放大量未来得及写回磁盘的脏块时,突然出现系统故障(比如断电),导致内存中的数据丢失。而此时磁盘中的块存放的依然是修改前的旧数据,这样岂不是导致前面的修改无效?
要怎样保持事务的一致性呢?
答:如果我们能够保存住提交的记录,在 Database Buffer Cache 中一旦有数据更改,马上写入一个地方记录下来,不就可以保证事务一致性了嘛。
小说明:Instance在断电时会消失,Instance在内存中存放的数据将丢失。这就需要 Redo Log Buffer 发挥它的作用啦。
3)Redo Log Buffer
- 日志条目(Redo Entries )记录了数据库的所有修改信息(包括 DML 和 DDL),一条Redo Entries记录一次对数据库的改变 ,为的是数据库恢复。
- 日志条目首先产生于日志缓冲区。日志缓冲区较小,它是以字节为单位的,它极其重要。
- 在Database Buffer Cache中一旦有数据更改,马上写入Redo Log Buffer,Redo Log Buffer在内存中保留一段时间后,会写入磁盘,然后归档(3级结构)。
4)Large Pool(可选)
为了进行大的后台进程操作而分配的内存空间,与 shared pool 管理不同,主要用于共享服
务器的 session memory,RMAN 备份恢复以及并行查询等。
5)Java Pool(可选)
为了 java 虚拟机及应用而分配的内存空间,包含所有 session 指定的 JAVA 代码和数据。
6)Stream Pool(可选)
为了 stream process 而分配的内存空间。stream 技术是为了在不同数据库之间共享数据,
因此,它只对使用了 stream 数据库特性的系统是重要的。
Background process
在正式介绍 Background Process 之前,先简单介绍 Oracle 的 Process 类型。
Oracle Process 有三种类型:
- User Proces
客户端要与服务器连接,在客户端启动起来的进程就是 User Process,一般分为三种形式(sql*plus, 应用程序,web 方式(OEM))。
- 서버 프로세스
사용자 프로세스는 Oracle에 직접 접근할 수 없습니다. 해당 서버 프로세스를 통해 인스턴스에 접근한 후 데이터베이스에 접근해야 합니다.
사용자가 Oracle Server에 로그인하면 사용자 프로세스와 서버 프로세스가 연결을 설정합니다.
- 백그라운드 프로세스
Oracle 인스턴스의 중요한 부분입니다. 이에 대해서는 다음에 자세히 설명하겠습니다.
추가 사항:
Connection & Session
Connection은 Oracle 클라이언트와 백그라운드 및 백그라운드 프로세스(서버 프로세스)에 의해 설정된 TCP 연결을 의미합니다. 그림 4와 같이:
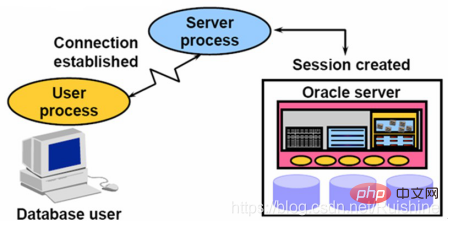
그림 4 연결
연결 설정 프로세스는 다음과 같이 간략하게 설명할 수 있습니다.
1 먼저 TCP 연결을 설정하고 Oracle은 사용자의 신원을 인증하고 보안 감사를 수행합니다. .;
2. Oracle의 서버 프로세스는 클라이언트가 Oracle에서 제공하는 서비스를 사용할 수 있도록 허용합니다.
3. 연결이 끊어지면 세션이 시작됩니다. 세션이 사라집니다.
세션과 연결은 서로를 보완합니다. 세션 정보는 Oracle의 데이터 사전에 저장됩니다.
그림 5를 통해 Connection과 Session의 차이점을 직관적으로 확인할 수 있습니다.
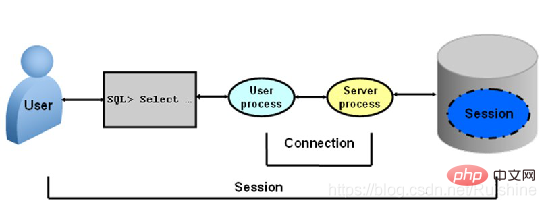
그림 5 연결 및 세션
백그라운드 프로세스(백그라운드 프로세스)에는 주로 SMON(시스템 모니터 프로세스), PMON(프로세스 모니터 프로세스), DBWR(데이터베이스 기록기 프로세스), LGWR(로그 기록기 프로세스), CKPT(체크포인트 프로세스).
1) PMON(프로세스 모니터)
PMON의 주요 기능은 다음과 같습니다.
- 각 오라클 백그라운드 프로세스의 정상 여부를 모니터링하고, 비정상적인 프로세스가 발견되면 클리어하고, 프로세스를 재생성합니다.
- (참고: 사용자 프로세스가 연결 해제되면 서버 프로세스가 남아 있으면 쓸모가 없지만 여전히 공간을 차지합니다. PMON은 서버 프로세스를 정기적으로 확인합니다. 사용자 프로세스에 연결할 수 없는 경우 PMON은 서버 프로세스를 다시 복구하면 PGA 공간이 복구되고 내부 잠금도 복구됩니다.)
- 유휴 세션이 임계값에 도달했는지 모니터링합니다.
- 동적 등록 및 모니터링.
2) SMON(시스템 모니터)
SMON의 주요 기능은 다음과 같습니다.
- Oracle 실행 중 갑자기 충돌이 발생하면 다음 시작을 위해 인스턴스 복구(Instance Recovery)가 필요합니다.
- Oracle 실행 중에 갑자기 충돌이 발생하면 다음에 Oracle 인스턴스를 시작할 때 해당 인스턴스의 일부 릴리스되지 않은 리소스가 SMON에 의해 정리됩니다.
- 일부 트랜잭션도 실패할 때 SMON에 의해 정리됩니다. 메모리 공간이 매우 분산되어 있습니다(불연속적). 이 분산된 공간을 통합하려면 SMON이 필요합니다.
- 더 이상 사용되지 않는 임시 세그먼트(세그먼트)를 해제합니다.
3) DBWR (Database Writer)
DBWn은 오라클에서 가장 많은 작업을 수행하는 프로세스입니다. 주요 기능은 다음과 같습니다.
- 데이터베이스 버퍼 캐시의 더티 블록(Dirty Buffer)을 데이터 파일에 씁니다.
- 데이터 버퍼 캐시 공간을 해제합니다.
참고 사항:
데이터베이스 로드가 상대적으로 크고, 클라이언트의 요청이 많고, IO 작업 수가 많고, 버퍼 내용을 디스크 파일에 자주 써야 하는 경우 여러 개를 구성할 수 있습니다. DBWn(Oracle은 총 20개의 DBWn, DBW0-DBW9, DBWa-DBWg를 지원합니다). 일반적으로 중소 규모의 Oracle에는 DBW0 프로세스가 하나만 필요합니다.
참고: 다음 상황이 발생하면 데이터베이스 버퍼 캐시의 내용을 데이터 파일에 쓰기 위해 DBWR 프로세스가 트리거됩니다.
- 체크포인트 발생
- 더티 버퍼 도달 임계값
- 사용 가능한 버퍼가 없습니다
- 시간 초과 발생
- RAC ping 요청이 이루어졌습니다
- Tablespace OFFLINE
- Tablespace READ ONLY
- Table DROP 또는 TRUNCATE
- Tablespace BEGIN
- BACKUP
작은 추가 사항:
서버 프로세스는 데이터 파일에 대한 읽기 작업을 수행하고 DBWR은 데이터 처리를 담당합니다. 파일은 쓰기 작업을 수행합니다.
빠른 질문과 답변:
커밋 시 DBWR은 무엇을 합니까?
답변: 아무것도 하지 마세요!
4) LGWR ((LOG Writer))
Oracle 인스턴스에는 LGWR 프로세스가 하나만 있습니다. 이 프로세스의 작업은 DBWR 프로세스와 유사합니다. 주요 기능은 다음과 같습니다:
리두 로그 버퍼의 내용을 리두 로그 파일에 기록합니다(DBWR이 더티 블록을 쓰기 전에 로그를 기록해야 합니다).
(Redo Log Buffer는 순환 버퍼이고 해당 Redo Log Files도 순환 파일 그룹입니다. 파일 헤드부터 쓰기 시작합니다. 파일이 가득 차면 다시 파일 헤드부터 쓰기 시작하며, 이전 내용을 덮어쓰게 됩니다. Redo 로그 파일을 덮어쓰는 것을 방지하려면 Archived Redo 로그 파일에 기록하도록 선택할 수 있습니다.)
참고: 다음 상황이 발생하면 LGWR 프로세스가 트리거되어 내용을 기록합니다. 리두 로그 버퍼를 리두 로그 파일로:
- 커밋 시
- 1/3이 찼을 때
- 리두 공간이 1MB일 때
- 3초마다
- DBWn이 쓰기 전
커밋된 트랜잭션이 영구적으로 유지되도록 하려면 어떻게 해야 합니까?
답변: 업데이트 작업은 예시로 수행되었습니다.
1. 수정 사항이 Redo 로그 버퍼에 기록되었습니다.
2. 제출이 성공했다는 것은 수정 사항이 디스크 Redo 로그 파일에 기록되었음을 의미합니다. 제출이 성공적으로 완료되면 변경 사항이 디스크에 동기화되어 손실되지 않습니다.
- 체크포인트 생성, DBWR에 더티 블록 작성 알림 또는 촉구
- * 체크포인트 완료: 데이터 일관성 보장.
- * 증분 체크포인트: 제어 파일의 체크포인트 위치를 지속적으로 업데이트하여 인스턴스 크래시 발생 시 인스턴스 복구 시간을 최대한 단축할 수 있습니다. 데이터 파일의 파일 헤더에서 체크포인트 정보를 업데이트합니다. 제어 파일의 체크포인트 정보를 업데이트합니다.
- ARCn은 선택적 백그라운드 프로세스입니다(거의 필수 프로세스로 간주됨).
- Oracle은 ARCHIVELOG 모드(아카이브 모드)와 NOARCHIVELOG 모드(비아카이브 모드)의 두 가지 모드로 실행할 수 있습니다.
- DBA가 내려야 하는 중요한 결정은 데이터베이스를 ARCHIVELOG 모드 또는 NOARCHIVELOG 모드에서 실행하도록 구성할지 여부입니다.
- 온라인 다시 실행 로그 파일이 채워지면 Oracle 인스턴스는 다음 온라인 다시 실행 로그 파일을 쓰기 시작합니다.
- 한 온라인 리두 로그 파일에서 다른 온라인 리두 로그 파일로 전환하는 프로세스를 로그 전환이라고 합니다.
- ARCn 프로세스는 로그 전환이 수행될 때마다 채워진 로그 그룹의 백업 또는 아카이브를 시작합니다.
- ARCn 프로세스는 로그를 재사용하기 전에 리두 로그 파일을 자동으로 보관하므로 데이터베이스에 대한 모든 변경 사항이 보존됩니다.
이 외에도 매개변수 파일, 비밀번호 파일, 달성 로그 파일 등이 있습니다.
* 예: 데이터베이스에 제출해야 하는 트랜잭션이 있지만 제출이 실패하여 트랜잭션을 롤백해야 합니다. 그런 다음 트랜잭션 롤백의 기반은 Redo 로그 파일에서 나옵니다. Redo Log Files는 데이터베이스 변경 사항을 기록합니다. 이러한 트랜잭션 변경과 관련하여 롤백이 필요한 경우 Redo Log Files의 데이터를 꺼내고 Redo Log Files의 데이터에 따라 Data Files를 수정 전 상태로 복원해야 합니다.
빠른 질문과 답변: 인스턴스와 데이터베이스의 대응 관계는 무엇인가요?
답변: 인스턴스: 데이터베이스 = n: 1
1 인스턴스는 1개의 데이터베이스에만 속할 수 있으며, 여러 인스턴스가 동시에 1개의 데이터베이스에 액세스할 수 있습니다.
Oracle의 메모리 구조
- 하나의 Oracle 인스턴스는 하나의 SGA에 해당합니다. SGA는 Oracle 인스턴스가 시작될 때 할당됩니다. SGA는 Oracle 인스턴스의 기본 구성 요소입니다.
- Oracle 인스턴스에는 SGA가 하나만 있습니다. SGA는 매우 큰 메모리 공간이며 물리적 메모리의 80%를 차지할 수도 있습니다.
PGA (Program Global Area)
- 서버 프로세스가 시작되면 PGA가 할당됩니다. Oracle 인스턴스에는 많은 PGA가 있을 수 있습니다. 예를 들어, 10개의 서버 프로세스를 시작하면 10개의 PGA가 있게 됩니다.
- PGA는 사용자 커서, 변수, 컨트롤, 데이터 정렬을 저장하고 해시 값을 저장합니다.
- SGA와 달리 PGA는 독립적이며 공유되지 않습니다. 프로세스에 할당되고 해당 프로세스에만 사용되는 메모리 영역입니다.
추천 튜토리얼: "Oracle Video Tutorial"
위 내용은 Oracle 아키텍처에 대한 간략한 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!