
집 >운영 및 유지보수 >리눅스 운영 및 유지 관리 >리눅스 스택이 뭐야?
리눅스 스택이 뭐야?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB원래의
- 2022-07-08 16:41:262695검색
Linux에서 스택은 직렬 데이터 구조입니다. 이 데이터 구조의 특성은 시리즈의 한쪽 끝에서만 데이터를 푸시하고 팝할 수 있습니다. 스택, 스레드 스택, 커널 스택 및 인터럽트 스택.

이 튜토리얼의 운영 환경: linux7.3 시스템, Dell G3 컴퓨터.
리눅스 스택이란?
스택(Stack)은 직렬 형태의 데이터 구조입니다. 이 데이터 구조의 특징은 LIFO(Last In First Out)입니다. 데이터는 문자열의 한쪽 끝(스택 상단이라고 함)에서만 푸시되고 팝될 수 있습니다.
프로세스 스택
스레드 스택
커널 스택
인터럽트 스택

대부분의 프로세서 아키텍처에는 하드웨어 스택이 구현되어 있습니다. 푸시/팝 작업을 완료하기 위한 전용 스택 포인터 레지스터와 특정 하드웨어 명령이 있습니다. 예를 들어 ARM 아키텍처에서 R13(SP) 포인터는 스택 포인터 레지스터이고, PUSH는 스택을 푸시하기 위한 어셈블리 명령어이며, POP는 스택을 팝하기 위한 어셈블리 명령어입니다.
【확장 읽기】ARM 레지스터 소개
ARM 프로세서에는 37개의 레지스터가 있습니다. 이러한 레지스터는 부분적으로 겹치는 그룹으로 배열됩니다. 각 프로세서 모드에는 서로 다른 레지스터 세트가 있습니다. 그룹화된 레지스터는 프로세서 예외 및 권한 있는 작업을 처리하기 위한 빠른 컨텍스트 전환을 제공합니다.
다음 레지스터가 제공됩니다.
30개의 32비트 범용 레지스터:
15개의 범용 레지스터가 있으며 r0-r12, sp, lr
sp(r13)입니다. 스택 포인터입니다. C/C++ 컴파일러는 서브루틴을 호출할 때 반환 주소를 저장하기 위해 항상 sp를 스택 포인터
lr(r14)로 사용합니다. 반환 주소가 스택에 저장되면 lr을 범용 레지스터로 사용할 수 있습니다.
프로그램 카운터(pc): 명령어 레지스터
애플리케이션 상태 레지스터(APSR): 산술 논리 장치(ALU)를 보유합니다. 상태 플래그 복사
현재 프로그램 상태 레지스터(CPSR): APSR 플래그, 현재 프로세서 모드, 인터럽트 비활성화 플래그 등을 저장합니다.
저장된 프로그램 상태 레지스터(SPSR): 예외가 발생하면 SPSR을 사용하여 저장합니다. CPSR
위는 스택의 원리와 구현입니다. 이제 스택이 하는 일을 살펴보겠습니다. 스택의 역할은 함수 호출과 다중 작업 지원이라는 두 가지 측면으로 반영될 수 있습니다.
1. 함수 호출
함수 호출에는 다음 세 가지 기본 프로세스가 있다는 것을 알고 있습니다.
호출 매개변수 전달
지역 변수의 공간 관리
함수 반환
함수 호출은 효율적이어야 하며 CPU 일반 레지스터나 RAM 메모리에 데이터를 저장하는 것이 의심할 여지 없이 최선의 선택입니다. 호출 매개변수 전달을 예로 들면, CPU 일반 레지스터를 사용하여 매개변수를 저장하도록 선택할 수 있습니다. 그러나 범용 레지스터의 수는 제한되어 있습니다. 중첩된 함수 호출이 발생하면 원래 범용 레지스터를 다시 사용하는 하위 함수는 필연적으로 충돌을 발생시킵니다. 따라서 이를 사용하여 매개변수를 전달하려면 하위 함수를 호출하기 전에 원래 레지스터 값을 저장한 다음 하위 함수가 종료될 때 원래 레지스터 값을 복원해야 합니다.
함수의 호출 매개변수 수는 일반적으로 상대적으로 적으므로 범용 레지스터는 특정 요구 사항을 충족할 수 있습니다. 그러나 지역 변수가 차지하는 수와 공간은 상대적으로 크고 제한된 범용 레지스터에 의존하기 어렵습니다. 따라서 특정 RAM 메모리 영역을 사용하여 지역 변수를 저장할 수 있습니다. 그런데 적절한 저장 위치는 어디일까요? 중첩된 함수를 호출할 때 충돌을 피하고 효율성에 중점을 둘 필요가 있습니다.
이 경우 스택은 의심할 여지없이 좋은 솔루션을 제공합니다. 1. 일반 레지스터 매개변수 전송 시 충돌이 발생하는 경우 하위 함수를 호출하기 전에 임시로 일반 레지스터를 스택에 푸시하고 저장된 레지스터를 다시 팝할 수 있습니다. 2. 지역 변수를 위한 공간을 적용하려면 스택의 상단 포인터를 아래로 이동하기만 하면 됩니다. 지역 변수의 공간 해제를 완료하려면 스택의 상단 포인터를 뒤로 이동하면 됩니다. 하위 함수를 호출하기 전에 반환 주소를 스택에 푸시해야 합니다. 하위 함수 호출이 완료된 후 함수 반환 주소를 PC 포인터에 팝하면 함수 호출의 반환이 완료됩니다. 위 함수 호출의 세 가지 기본 프로세스는 스택 포인터를 기록하는 프로세스로 발전합니다. 함수가 호출될 때마다 스택 포인터가 제공됩니다. 중첩 루프에서 함수를 호출하더라도 해당 함수 스택 포인터가 다르면 충돌이 발생하지 않습니다.
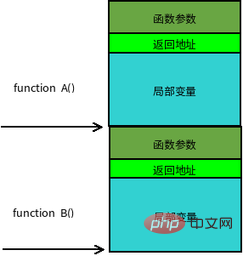
【확장 읽기】: 함수 스택 프레임
함수 호출은 종종 중첩됩니다. 동시에 스택에는 여러 함수에 대한 정보가 있습니다. 완료되지 않은 각 기능은 스택 프레임이라는 독립적인 연속 영역을 차지합니다. 스택 프레임에는 이전 스택 프레임을 복원하는 데 필요한 함수 매개 변수, 지역 변수 및 데이터가 저장됩니다. 함수가 호출될 때 스택에 푸시하는 순서는
실제 매개 변수 N~1 → 함수 반환 주소 호출 → 함수 프레임 베이스 호출입니다. 포인터 EBP → 호출된 함수 로컬 변수 1~N
스택 프레임의 경계는 스택 프레임 기본 주소 포인터 EBP로 정의되며 스택 포인터 EBP는 현재 스택 프레임의 하단(상위 주소)을 가리키고 ESP는 현재 스택 프레임의 맨 위(낮은 주소)를 가리키며 프로그램이 실행될 때 데이터가 스택에서 푸시되고 팝되면서 ESP가 이동합니다. 따라서 함수 내 대부분의 데이터 액세스는 EBP를 기반으로 합니다. 함수 호출 스택의 일반적인 메모리 레이아웃은 아래 그림과 같습니다.
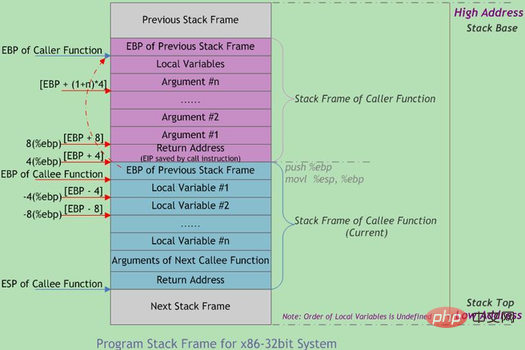
2. 멀티 태스킹 지원
그러나 스택의 의미는 단지 함수 호출만이 아닙니다. -운영 체제의 작업 모드가 구성됩니다. 메인 함수 호출을 예로 들어 보겠습니다. 메인 함수에는 무한 루프 본문이 포함되어 있습니다. 루프 본문에서는 함수 A가 먼저 호출된 다음 함수 B가 호출됩니다.
func B():
return;
func A():
B();
func main():
while (1)
A();단일프로세서 상황에서 프로그램이 이 주 기능에 영원히 머무른다고 상상해 보세요. 대기 상태에 있는 다른 작업이 있더라도 프로그램은 주 기능에서 다른 작업으로 점프할 수 없습니다. 함수 호출 관계라면 본질적으로 여전히 메인 함수의 작업이고 다중 작업 전환으로 간주할 수 없기 때문입니다. 현재 기본 함수 작업 자체는 실제로 해당 스택에 바인딩되어 있습니다. 함수 호출이 아무리 중첩되어 있어도 스택 포인터는 이 스택 범위 내에서 이동합니다.
작업은 다음 정보로 특징지어질 수 있음을 알 수 있습니다:
주 함수 본문 코드
주 함수 스택 포인터
현재 CPU 레지스터 정보
위의 정보를 통해 CPU가 다른 작업을 처리하도록 강제할 수 있습니다. 나중에 이 기본 작업을 계속 실행하려는 경우 위의 정보를 복원할 수 있습니다. 이러한 전제조건으로 멀티태스킹은 그 존재의 기반을 갖게 되는데, 스택의 존재에 대한 또 다른 의미도 볼 수 있다. 멀티 태스킹 모드에서 스케줄러가 작업 전환이 필요하다고 판단하면 작업 정보(즉 위에서 언급한 세 가지)만 저장하면 됩니다. 다른 작업의 상태를 복원한 다음 마지막 실행 위치로 점프하여 실행을 재개합니다.
각 작업에는 자체 스택 공간이 있으므로 코드 재사용을 위해 여러 작업이 작업 자체의 함수 본문을 혼합할 수도 있습니다. 두 개의 작업 인스턴스. 이후 운영 체제의 프레임워크도 형성되었습니다. 예를 들어 작업이 sleep()을 호출하고 대기할 때 CPU를 다른 작업에 적극적으로 양보하거나 다음과 같은 경우 시간 공유 운영 체제 작업이 강제됩니다. 시간 조각이 모두 사용되었습니다. CPU를 포기하세요. 어떤 방법을 사용하든 작업의 컨텍스트 공간을 전환하고 스택을 전환하는 방법을 찾으십시오.
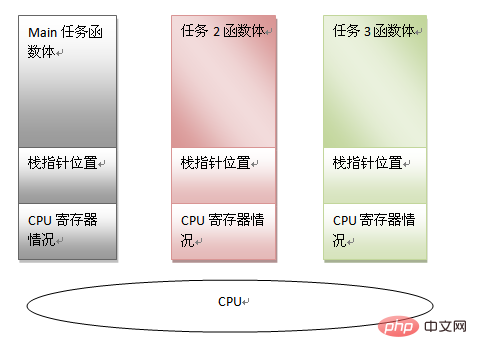
[확장 읽기]: 작업, 스레드 및 프로세스 간의 관계
작업은 소프트웨어가 완료하는 활동을 의미하는 추상적인 개념입니다. 스레드는 작업을 완료하는 데 필요한 작업을 참조합니다. to는 이 작업을 완료하는 데 필요한 리소스의 총칭입니다.
Task = 배달
Thread = 배달 트럭 운전
System Scheduling = 운전할 적절한 배달 트럭을 결정하세요
프로세스 = 도로 + 주유소 + 배달 트럭 + 차고
Linux에는 몇 개의 스택이 있습니까? 다양한 스택의 메모리 위치는 무엇입니까?
스택의 작동 원리와 목적을 소개한 후 Linux 커널로 돌아갑니다. 커널은 스택을 네 가지 유형으로 나눕니다.
Process stack
Thread stack
Kernel stack
Interrupt stack
1. 프로세스 스택
사용자 모드 스택과 프로세스 가상 주소 공간(Virtual Address Space)은 밀접한 관련이 있습니다. 따라서 먼저 가상 주소 공간이 무엇인지 이해해 보겠습니다. 32비트 시스템에서 가상 주소 공간의 크기는 4G입니다. 이러한 가상 주소는 운영 체제에서 유지 관리하고 프로세서의 메모리 관리 장치(MMU) 하드웨어에서 참조하는 페이지 테이블을 통해 실제 메모리에 매핑됩니다. 각 프로세스에는 자체 페이지 테이블 세트가 있으므로 각 프로세스는 전체 가상 주소 공간에 독점적으로 액세스할 수 있는 것처럼 보입니다.
Linux 内核将这 4G 字节的空间分为两部分,将最高的 1G 字节(0xC0000000-0xFFFFFFFF)供内核使用,称为 内核空间。而将较低的3G字节(0x00000000-0xBFFFFFFF)供各个进程使用,称为 用户空间。每个进程可以通过系统调用陷入内核态,因此内核空间是由所有进程共享的。虽然说内核和用户态进程占用了这么大地址空间,但是并不意味它们使用了这么多物理内存,仅表示它可以支配这么大的地址空间。它们是根据需要,将物理内存映射到虚拟地址空间中使用。
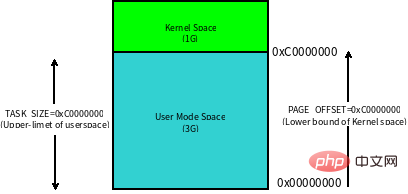
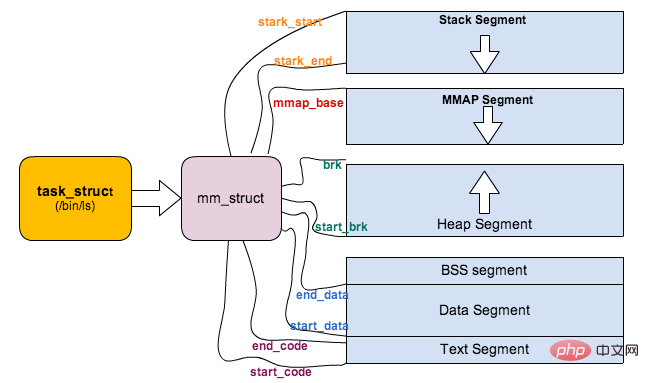
Linux 对进程地址空间有个标准布局,地址空间中由各个不同的内存段组成 (Memory Segment),主要的内存段如下:
程序段 (Text Segment):可执行文件代码的内存映射
数据段 (Data Segment):可执行文件的已初始化全局变量的内存映射
BSS段 (BSS Segment):未初始化的全局变量或者静态变量(用零页初始化)
堆区 (Heap) : 存储动态内存分配,匿名的内存映射
栈区 (Stack) : 进程用户空间栈,由编译器自动分配释放,存放函数的参数值、局部变量的值等
映射段(Memory Mapping Segment):任何内存映射文件

而上面进程虚拟地址空间中的栈区,正指的是我们所说的进程栈。进程栈的初始化大小是由编译器和链接器计算出来的,但是栈的实时大小并不是固定的,Linux 内核会根据入栈情况对栈区进行动态增长(其实也就是添加新的页表)。但是并不是说栈区可以无限增长,它也有最大限制 RLIMIT_STACK (一般为 8M),我们可以通过 ulimit 来查看或更改 RLIMIT_STACK 的值。
【扩展阅读】:如何确认进程栈的大小
我们要知道栈的大小,那必须得知道栈的起始地址和结束地址。栈起始地址 获取很简单,只需要嵌入汇编指令获取栈指针 esp 地址即可。栈结束地址 的获取有点麻烦,我们需要先利用递归函数把栈搞溢出了,然后再 GDB 中把栈溢出的时候把栈指针 esp 打印出来即可。代码如下:
/* file name: stacksize.c */
void *orig_stack_pointer;
void blow_stack() {
blow_stack();
}
int main() {
__asm__("movl %esp, orig_stack_pointer");
blow_stack();
return 0;
}$ g++ -g stacksize.c -o ./stacksize $ gdb ./stacksize (gdb) r Starting program: /home/home/misc-code/setrlimit Program received signal SIGSEGV, Segmentation fault. blow_stack () at setrlimit.c:4 4 blow_stack(); (gdb) print (void *)$esp $1 = (void *) 0xffffffffff7ff000 (gdb) print (void *)orig_stack_pointer $2 = (void *) 0xffffc800 (gdb) print 0xffffc800-0xff7ff000 $3 = 8378368 // Current Process Stack Size is 8M
上面对进程的地址空间有个比较全局的介绍,那我们看下 Linux 内核中是怎么体现上面内存布局的。内核使用内存描述符来表示进程的地址空间,该描述符表示着进程所有地址空间的信息。内存描述符由 mm_struct 结构体表示,下面给出内存描述符结构中各个域的描述,请大家结合前面的 进程内存段布局 图一起看:
struct mm_struct {
struct vm_area_struct *mmap; /* 内存区域链表 */
struct rb_root mm_rb; /* VMA 形成的红黑树 */
...
struct list_head mmlist; /* 所有 mm_struct 形成的链表 */
...
unsigned long total_vm; /* 全部页面数目 */
unsigned long locked_vm; /* 上锁的页面数据 */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long shared_vm; /* 共享页面数目 Shared pages (files) */
unsigned long exec_vm; /* 可执行页面数目 VM_EXEC & ~VM_WRITE */
unsigned long stack_vm; /* 栈区页面数目 VM_GROWSUP/DOWN */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data; /* 代码段、数据段 起始地址和结束地址 */
unsigned long start_brk, brk, start_stack; /* 栈区 的起始地址,堆区 起始地址和结束地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数 和 环境变量的 起始地址和结束地址 */
...
/* Architecture-specific MM context */
mm_context_t context; /* 体系结构特殊数据 */
/* Must use atomic bitops to access the bits */
unsigned long flags; /* 状态标志位 */
...
/* Coredumping and NUMA and HugePage 相关结构体 */
};
【扩展阅读】:进程栈的动态增长实现
进程在运行的过程中,通过不断向栈区压入数据,当超出栈区容量时,就会耗尽栈所对应的内存区域,这将触发一个 缺页异常 (page fault)。通过异常陷入内核态后,异常会被内核的 expand_stack() 函数处理,进而调用 acct_stack_growth() 来检查是否还有合适的地方用于栈的增长。
如果栈的大小低于 RLIMIT_STACK(通常为8MB),那么一般情况下栈会被加长,程序继续执行,感觉不到发生了什么事情,这是一种将栈扩展到所需大小的常规机制。然而,如果达到了最大栈空间的大小,就会发生 栈溢出(stack overflow),进程将会收到内核发出的 段错误(segmentation fault) 信号。
动态栈增长是唯一一种访问未映射内存区域而被允许的情形,其他任何对未映射内存区域的访问都会触发页错误,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
二、线程栈
从 Linux 内核的角度来说,其实它并没有线程的概念。Linux 把所有线程都当做进程来实现,它将线程和进程不加区分的统一到了 task_struct 中。线程仅仅被视为一个与其他进程共享某些资源的进程,而是否共享地址空间几乎是进程和 Linux 中所谓线程的唯一区别。线程创建的时候,加上了 CLONE_VM 标记,这样 线程的内存描述符 将直接指向 父进程的内存描述符。
if (clone_flags & CLONE_VM) {
/*
* current 是父进程而 tsk 在 fork() 执行期间是共享子进程
*/
atomic_inc(¤t->mm->mm_users);
tsk->mm = current->mm;
}虽然线程的地址空间和进程一样,但是对待其地址空间的 stack 还是有些区别的。对于 Linux 进程或者说主线程,其 stack 是在 fork 的时候生成的,实际上就是复制了父亲的 stack 空间地址,然后写时拷贝 (cow) 以及动态增长。然而对于主线程生成的子线程而言,其 stack 将不再是这样的了,而是事先固定下来的,使用 mmap 系统调用,它不带有 VM_STACK_FLAGS 标记。这个可以从 glibc 的 nptl/allocatestack.c 中的 allocate_stack() 函数中看到:
mem = mmap (NULL, size, prot, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0);
由于线程的 mm->start_stack 栈地址和所属进程相同,所以线程栈的起始地址并没有存放在 task_struct 中,应该是使用 pthread_attr_t 中的 stackaddr 来初始化 task_struct->thread->sp(sp 指向 struct pt_regs 对象,该结构体用于保存用户进程或者线程的寄存器现场)。这些都不重要,重要的是,线程栈不能动态增长,一旦用尽就没了,这是和生成进程的 fork 不同的地方。由于线程栈是从进程的地址空间中 map 出来的一块内存区域,原则上是线程私有的。但是同一个进程的所有线程生成的时候浅拷贝生成者的 task_struct 的很多字段,其中包括所有的 vma,如果愿意,其它线程也还是可以访问到的,于是一定要注意。
三、进程内核栈
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};thread_union 进程内核栈 和 task_struct 进程描述符有着紧密的联系。由于内核经常要访问 task_struct,高效获取当前进程的描述符是一件非常重要的事情。因此内核将进程内核栈的头部一段空间,用于存放 thread_info 结构体,而此结构体中则记录了对应进程的描述符,两者关系如下图(对应内核函数为 dup_task_struct()):
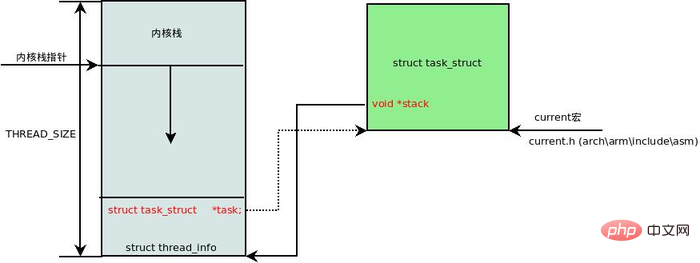
有了上述关联结构后,内核可以先获取到栈顶指针 esp,然后通过 esp 来获取 thread_info。这里有一个小技巧,直接将 esp 的地址与上 ~(THREAD_SIZE - 1) 后即可直接获得 thread_info 的地址。由于 thread_union 结构体是从 thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE 对齐的。因此只需要对栈指针进行 THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_union 的地址。成功获取到 thread_info 后,直接取出它的 task 成员就成功得到了 task_struct。其实上面这段描述,也就是 current 宏的实现方法:
register unsigned long current_stack_pointer asm ("sp");
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()四、中断栈
进程陷入内核态的时候,需要内核栈来支持内核函数调用。中断也是如此,当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。
X86 上中断栈就是独立于内核栈的;独立的中断栈所在内存空间的分配发生在 arch/x86/kernel/irq_32.c 的 irq_ctx_init() 函数中 (如果是多处理器系统,那么每个处理器都会有一个独立的中断栈),函数使用 __alloc_pages 在低端内存区分配 2个物理页面,也就是8KB大小的空间。有趣的是,这个函数还会为 softirq 分配一个同样大小的独立堆栈。如此说来,softirq 将不会在 hardirq 的中断栈上执行,而是在自己的上下文中执行。

而 ARM 上中断栈和内核栈则是共享的;中断栈和内核栈共享有一个负面因素,如果中断发生嵌套,可能会造成栈溢出,从而可能会破坏到内核栈的一些重要数据,所以栈空间有时候难免会捉襟见肘。
추천 학습: Linux 비디오 튜토리얼
위 내용은 리눅스 스택이 뭐야?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!