
Java 기본 휘발성에 대한 자세한 설명

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2022-07-06 13:49:542603검색
이 글은 java에 대한 관련 지식을 제공합니다. 휘발성은 가시성을 보장하고, 휘발성은 원자성을 보장하지 않으며, 휘발성은 명령 재배열을 금지하는 등 휘발성과 관련된 문제를 주로 정리합니다. 살펴보겠습니다. 모든 사람에게 도움이 되기를 바랍니다. .

추천 학습: "java 비디오 튜토리얼"
Q:휘발성에 대한 이해에 대해 이야기해 주세요.
답변: Volatile은 Java 가상 머신에서 제공하는 경량 동기화 메커니즘입니다. 여기에는 3가지 기능이 있습니다. :
1) 가시성 보장
2) 원자성을 보장하지 않음
3) 명령어 중복을 금지합니다. Pai
이제 막 Java의 기본을 배웠습니다. 누군가 휘발성이 무엇인지 묻는다면? 어떤 기능이 있다면 매우 혼란스러우실 거라 생각합니다...
답변을 읽고 나서 전혀 이해하지 못하실 수도 있는데, 동기화 메커니즘이 무엇인가요? 가시성이란 무엇입니까? 원자성이란 무엇입니까? 명령어 재정렬이란 무엇입니까?
1. Volatile은 가시성을 보장합니다
1.1 JMM 모델이 무엇인가요?
가시성이 무엇인지 이해하려면 먼저 JMM을 이해해야 합니다.
JMM(Java Memory Model, Java Memory Model) 자체는 추상적인 개념이며 실제로 존재하지 않습니다. 일련의 규칙이나 사양을 설명하며, 이 사양 세트를 통해 프로그램의 다양한 변수에 대한 액세스 방법이 결정됩니다. JMM의 동기화 규정:
1) 스레드가 잠금 해제되기 전에 공유 변수의 값이 주 메모리로 다시 새로 고쳐져야 합니다.
2) 스레드가 잠기기 전에 주 메모리의 최신 값을 읽어야 합니다.
3) 잠금 해제는 동일한 잠금입니다.
JVM 실행 프로그램의 엔터티는 스레드이므로 각 스레드가 생성될 때 JMM은 작업 메모리(어떤 곳에서는 스택 공간이라고 함)를 생성합니다. 작업 메모리는 각 스레드 영역의 개인 데이터입니다.
Java 메모리 모델은 모든 변수가 메인 메모리에 저장된다고 규정합니다. 메인 메모리는 모든 스레드가 접근할 수 있는 공유 메모리 영역입니다.
그러나 스레드의 변수 작업(읽기, 할당 등)은 작업 메모리에서 수행되어야 합니다. 따라서 먼저 메인 메모리의 변수를 자신의 작업 메모리로 복사한 후 변수를 연산하고, 연산이 완료된 후 변수를 메인 메모리에 써야 합니다.
위의 JMM 소개를 읽은 후에도 여전히 장점에 대해 혼란스러울 수 있습니다. 티켓 판매 시스템을 예로 들어 보겠습니다.
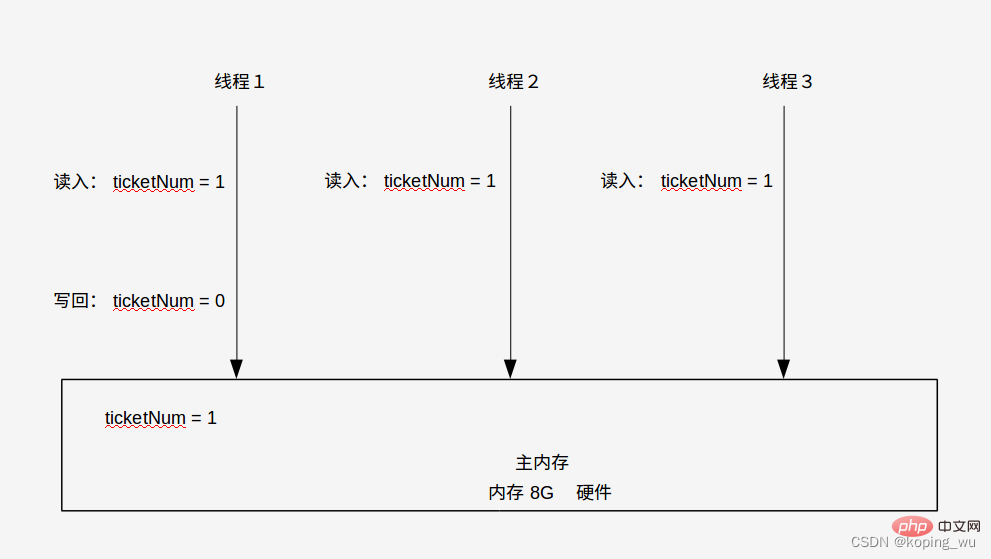
1) 아래와 같이 현재 백엔드에는 티켓이 1장만 남아 있습니다. 티켓 판매 시스템의 메인 메모리로 읽어왔습니다: ticketNum=1.
2) 현재 네트워크에는 티켓을 구매하는 사용자가 여러 명 있으므로 동시에 티켓 구매 서비스를 수행하는 스레드가 여러 개 있습니다. 현재 티켓 수를 읽은 스레드가 3개 있다고 가정합니다. 이번에는 ticketNum=1 , 그러면 티켓을 구매하겠습니다.
3) 스레드 1이 먼저 CPU 리소스를 점유하고, 티켓을 먼저 구매하고, 자체 작업 메모리에서 ticketNum 값을 0으로 변경한다고 가정합니다(ticketNum=0). 그런 다음 이를 다시 주 메모리에 씁니다.
이때 스레드 1의 사용자는 이미 티켓을 구매했기 때문에 스레드 2와 스레드 3은 현재 티켓을 계속 구매할 수 없어야 하므로 시스템은 스레드 2와 스레드 3에 ticketNum이 있음을 알려야 합니다. 이제 0과 같습니다: ticketNum =0. 이러한 알림 작업이 있으면 가시성이 있는 것으로 이해하시면 됩니다.
위의 JMM 소개와 예시를 통해 간략하게 요약해 볼 수 있습니다.
JMM 메모리 모델의 가시성은 여러 스레드가 주 메모리의 리소스에 액세스할 때 스레드가 자체 작업 메모리의 리소스를 수정하고 이를 다시 주 메모리에 쓰는 경우 JMM 메모리 모델이 이를 알려야 함을 의미합니다. 최신 리소스의 가시성을 보장하기 위해 최신 리소스를 다시 얻기 위한 다른 스레드.
1.2 가시성을 보장하는 휘발성의 코드 검증
1.1에서는 가시성의 의미를 기본적으로 이해했습니다. 다음으로, 휘발성이 실제로 가시성을 보장할 수 있는지 확인하는 코드를 사용합니다.
1.2.1.가시성 없는 코드 검증
먼저 휘발성을 사용하지 않으면 가시성이 없는지 확인합니다.
package com.koping.test;import java.util.concurrent.TimeUnit;class MyData{
int number = 0;
public void add10() {
this.number += 10;
}}public class VolatileVisibilityDemo {
public static void main(String[] args) {
MyData myData = new MyData();
// 启动一个线程修改myData的number,将number的值加10
new Thread(
() -> {
System.out.println("线程" + Thread.currentThread().getName()+"\t 正在执行");
try{
TimeUnit.SECONDS.sleep(3);
} catch (Exception e) {
e.printStackTrace();
}
myData.add10();
System.out.println("线程" + Thread.currentThread().getName()+"\t 更新后,number的值为" + myData.number);
}
).start();
// 看一下主线程能否保持可见性
while (myData.number == 0) {
// 当上面的线程将number加10后,如果有可见性的话,那么就会跳出循环;
// 如果没有可见性的话,就会一直在循环里执行
}
System.out.println("具有可见性!");
}}
실행 결과는 아래와 같습니다. 스레드 0이 숫자 값을 10으로 변경했지만 이때 숫자가 표시되지 않고 시스템이 적극적으로 알리지 않기 때문에 메인 스레드가 여전히 루프에 있음을 알 수 있습니다. . 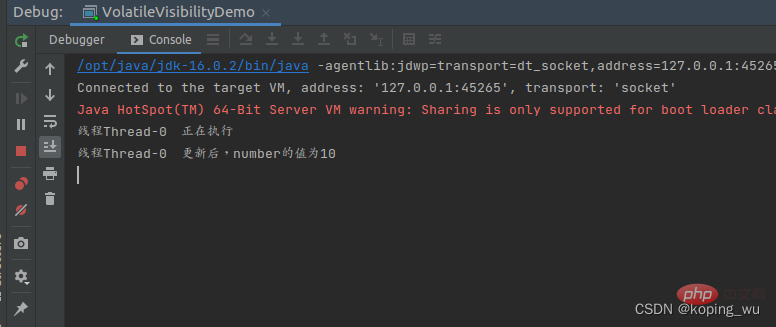
1.2.1, 휘발성 보증 가시성 검증
아래와 같이 위 코드의 7번째 줄에 변수 번호에 휘발성을 추가한 후 다시 테스트합니다. 이때 JMM이 적극적으로 알림을 보내므로 메인 스레드가 성공적으로 루프를 종료했습니다. 메인 스레드의 값이 업데이트되었습니다. Number는 더 이상 0이 아닙니다. 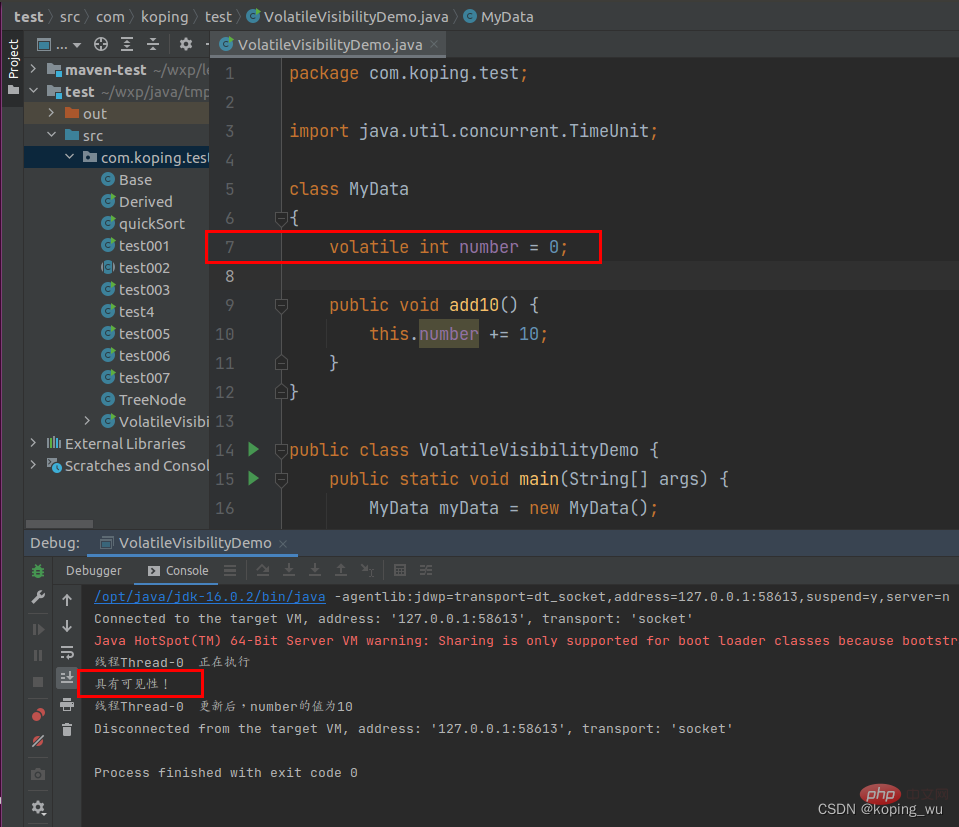
2、volatile不保证原子性
2.1 什么是原子性?
理解了上面说的可见性之后,再来理解下什么叫原子性?
原子性是指不可分隔,完整性,即某个线程正在做某个业务时,中间不能被分割。要么同时成功,要么同时失败。
还是有点抽象,接下来举个例子。
如下图,创建了一个测试原子性的类:TestPragma。在add方法中将n加1,通过查看编译后的代码可以看到,n++被拆分为3个指令进行执行。
因此可能存在线程1正在执行第1个指令,紧接着线程2也正在执行第1个指令,这样当线程1和线程2都执行完3个指令之后,很容易理解,此时n的值只加了1,而实际是有2个线程加了2次,因此这种情况就是不保证原子性。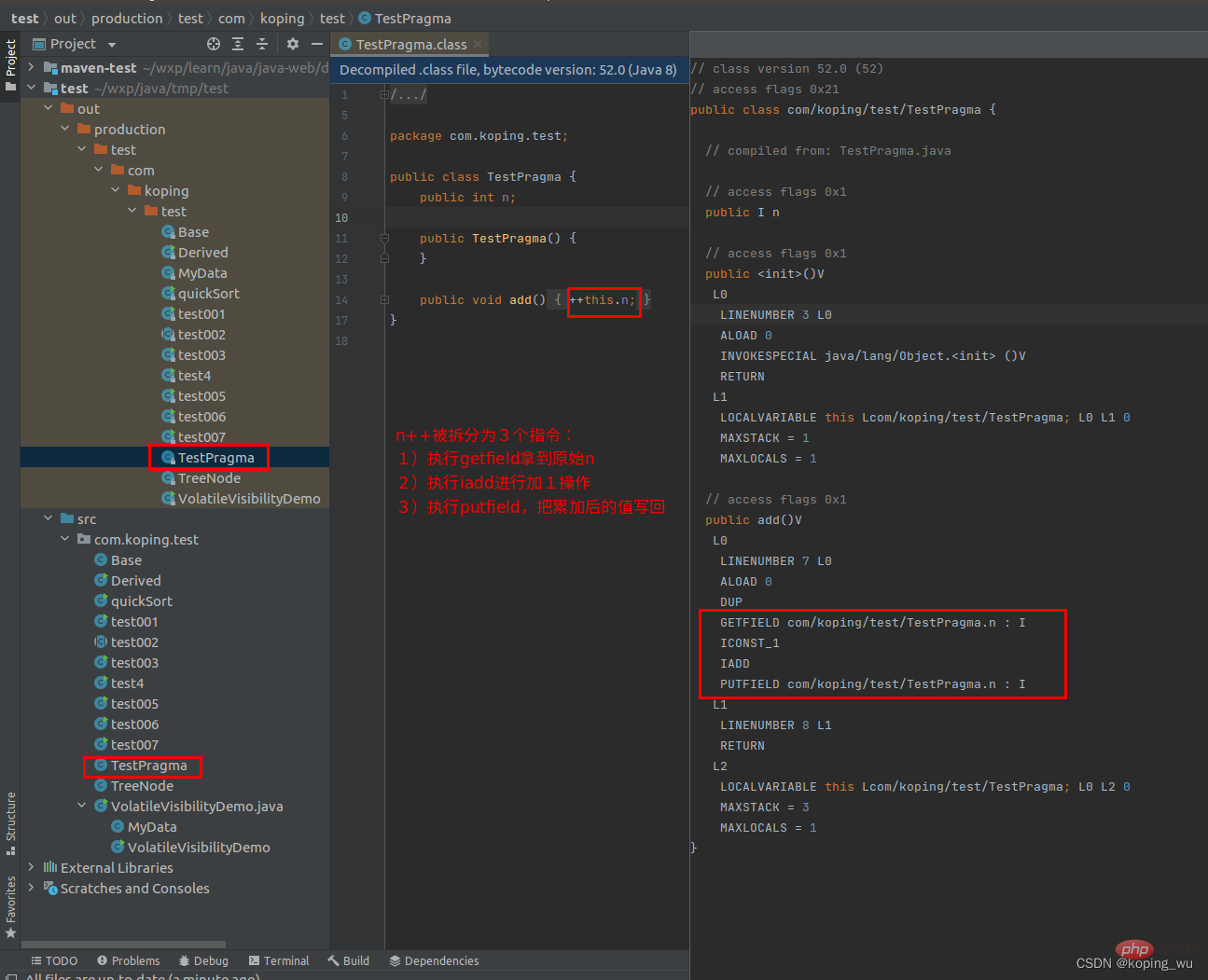
2.2 不保证原子性的代码验证
在2.1中已经进行了举例,可能存在2个线程执行n++的操作,但是最终n的值却只加了1的情况,接下来对这种情况再用代码进行演示下。
首先给MyData类添加一个add方法
package com.koping.test;class MyData {
volatile int number = 0;
public void add() {
number++;
}}
然后创建测试原子性的类:TestPragmaDemo。测试下20个线程给number各加1000次之后,number的值是否是20000。
package com.koping.test;public class TestPragmaDemo {
public static void main(String[] args) {
MyData myData = new MyData();
// 启动20个线程,每个线程将myData的number值加1000次,那么理论上number值最终是20000
for (int i=0; i {
for (int j=0; j2){
Thread.yield();
}
System.out.println("number值加了20000次,此时number的实际值是:" + myData.number);
}}
运行结果如下图,最终number的值仅为18410。
可以看到即使加了volatile,依然不保证有原子性。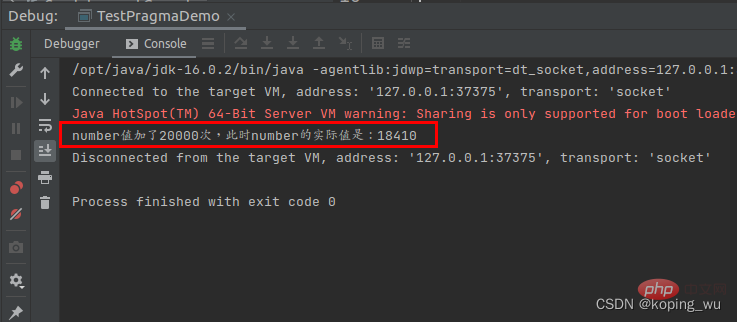
2.3 volatile不保证原子性的解决方法
上面介绍并证明了volatile不保证原子性,那如果希望保证原子性,怎么办呢?以下提供了2种方法
2.3.1 方法1:使用synchronized
方法1是在add方法上添加synchronized,这样每次只有1个线程能执行add方法。
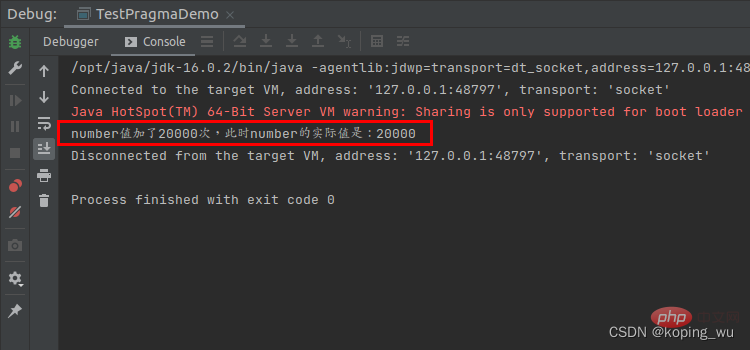
结果如下图,最终确实可以使number的值为20000,保证了原子性。
但是,实际业务逻辑方法中不可能只有只有number++这1行代码,上面可能还有n行代码逻辑。现在为了保证number的值是20000,就把整个方法都加锁了(其实另外那n行代码,完全可以由多线程同时执行的)。所以就优点杀鸡用牛刀,高射炮打蚊子,小题大做了。
package com.koping.test;class MyData {
volatile int number = 0;
public synchronized void add() {
// 在n++上面可能还有n行代码进行逻辑处理
number++;
}}
2.3.2 方法1:使用JUC包下的AtomicInteger
给MyData新曾一个原子整型类型的变量num,初始值为0。
package com.koping.test;import java.util.concurrent.atomic.AtomicInteger;class MyData {
volatile int number = 0;
volatile AtomicInteger num = new AtomicInteger();
public void add() {
// 在n++上面可能还有n行代码进行逻辑处理
number++;
num.getAndIncrement();
}}
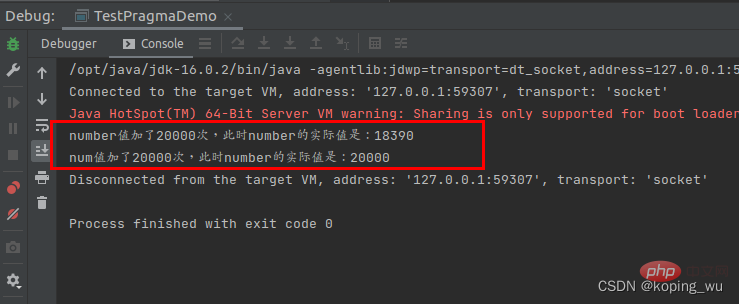
让num也同步加20000次。结果如下图,可以看到,使用原子整型的num可以保证原子性,也就是number++的时候不会被抢断。
package com.koping.test;public class TestPragmaDemo {
public static void main(String[] args) {
MyData myData = new MyData();
// 启动20个线程,每个线程将myData的number值加1000次,那么理论上number值最终是20000
for (int i=0; i {
for (int j=0; j2){
Thread.yield();
}
System.out.println("number值加了20000次,此时number的实际值是:" + myData.number);
System.out.println("num值加了20000次,此时number的实际值是:" + myData.num);
}}
3、volatile禁止指令重排
3.1 什么是指令重排?
在第2节中理解了什么是原子性,现在要理解下什么是指令重排?
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令进行重排:
源代码–>编译器优化重排–>指令并行重排–>内存系统重排–>最终执行指令
处理器在进行重排时,必须要考虑指令之间的数据依赖性。
单线程环境中,可以确保最终执行结果和代码顺序执行的结果一致。
但是多线程环境中,线程交替执行,由于编译器优化重排的存在,两个线程使用的变量能否保持一致性是无法确定的,结果无法预测。
看了上面的文字性表达,然后看一个很简单的例子。
比如下面的mySort方法,在系统指令重排后,可能存在以下3种语句的执行情况:
1)1234
2)2134
3)1324
以上这3种重排结果,对最后程序的结果都不会有影响,也考虑了指令之间的数据依赖性。
public void mySort() {
int x = 1; // 语句1
int y = 2; // 语句2
x = x + 3; // 语句3
y = x * x; // 语句4}
3.2 单线程单例模式
看完指令重排的简单介绍后,然后来看下单例模式的代码。
package com.koping.test;public class SingletonDemo {
private static SingletonDemo instance = null;
private SingletonDemo() {
System.out.println(Thread.currentThread().getName() + "\t 执行构造方法SingletonDemo()");
}
public static SingletonDemo getInstance() {
if (instance == null) {
instance = new SingletonDemo();
}
return instance;
}
public static void main(String[] args) {
// 单线程测试
System.out.println("单线程的情况测试开始");
System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());
System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());
System.out.println("单线程的情况测试结束\n");
}}
首先是在单线程情况下进行测试,结果如下图。可以看到,构造方法只执行了一次,是没有问题的。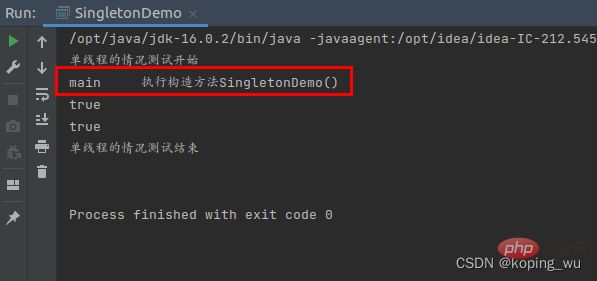
3.3 多线程单例模式
接下来在多线程情况下进行测试,代码如下。
package com.koping.test;public class SingletonDemo {
private static SingletonDemo instance = null;
private SingletonDemo() {
System.out.println(Thread.currentThread().getName() + "\t 执行构造方法SingletonDemo()");
}
public static SingletonDemo getInstance() {
if (instance == null) {
instance = new SingletonDemo();
}
// DCL(Double Check Lock双端检索机制)// if (instance == null) {// synchronized (SingletonDemo.class) {// if (instance == null) {// instance = new SingletonDemo();// }// }// }
return instance;
}
public static void main(String[] args) {
// 单线程测试// System.out.println("单线程的情况测试开始");// System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());// System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());// System.out.println("单线程的情况测试结束\n");
// 多线程测试
System.out.println("多线程的情况测试开始");
for (int i=1; i {
SingletonDemo.getInstance();
}, String.valueOf(i)).start();
}
}}
在多线程情况下的运行结果如下图。可以看到,多线程情况下,出现了构造方法执行了2次的情况。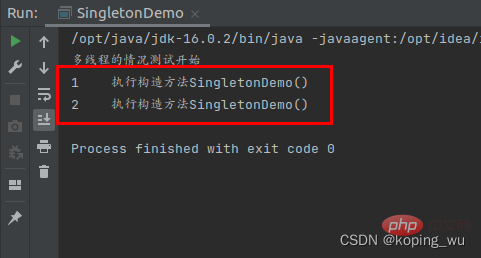
3.4 多线程单例模式改进:DCL
在3.3中的多线程单里模式下,构造方法执行了两次,因此需要进行改进,这里使用双端检锁机制:Double Check Lock, DCL。即加锁之前和之后都进行检查。
package com.koping.test;public class SingletonDemo {
private static SingletonDemo instance = null;
private SingletonDemo() {
System.out.println(Thread.currentThread().getName() + "\t 执行构造方法SingletonDemo()");
}
public static SingletonDemo getInstance() {// if (instance == null) {// instance = new SingletonDemo();// }
// DCL(Double Check Lock双端检锁机制)
if (instance == null) { // a行
synchronized (SingletonDemo.class) {
if (instance == null) { // b行
instance = new SingletonDemo(); // c行
}
}
}
return instance;
}
public static void main(String[] args) {
// 单线程测试// System.out.println("单线程的情况测试开始");// System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());// System.out.println(SingletonDemo.getInstance() == SingletonDemo.getInstance());// System.out.println("单线程的情况测试结束\n");
// 多线程测试
System.out.println("多线程的情况测试开始");
for (int i=1; i {
SingletonDemo.getInstance();
}, String.valueOf(i)).start();
}
}}
在多次运行后,可以看到,在多线程情况下,此时构造方法也只执行1次了。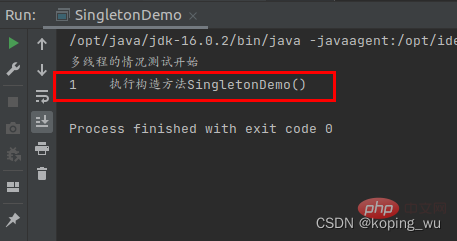
3.5 多线程单例模式改进,DCL版存在的问题
需要注意的是3.4中的DCL版的单例模式依然不是100%准确的!!!
是不是不太明白为什么3.4DCL版单例模式不是100%准确的原因?
是不是不太明白在3.1讲完指令重排的简单理解后,为什么突然要讲多线程的单例模式?
因为3.4DCL版单例模式可能会由于指令重排而导致问题,虽然该问题出现的可能性可能是千万分之一,但是该代码依然不是100%准确的。如果要保证100%准确,那么需要添加volatile关键字,添加volatile可以禁止指令重排。
接下来分析下,为什么3.4DCL版单例模式不是100%准确?
查看instance = new SingletonDemo();编译后的指令,可以分为以下3步:
1)分配对象内存空间:memory = allocate();
2)初始化对象:instance(memory);
3)设置instance指向分配的内存地址:instance = memory;
由于步骤2和步骤3不存在数据依赖关系,因此可能出现执行132步骤的情况。
比如线程1执行了步骤13,还没有执行步骤2,此时instance!=null,但是对象还没有初始化完成;
如果此时线程2抢占到cpu,然后发现instance!=null,然后直接返回使用,就会发现instance为空,就会出现异常。
这就是指令重排可能导致的问题,因此要想保证程序100%正确就需要加volatile禁止指令重排。
3.6 volatile保证禁止指令重排的原理
在3.1中简单介绍了下执行重排的含义,然后通过3.2-3.5,借助单例模式来举例说明多线程情况下,为什么要使用volatile的原因,因为可能存在指令重排导致程序异常。
接下来就介绍下volatile能保证禁止指令重排的原理。
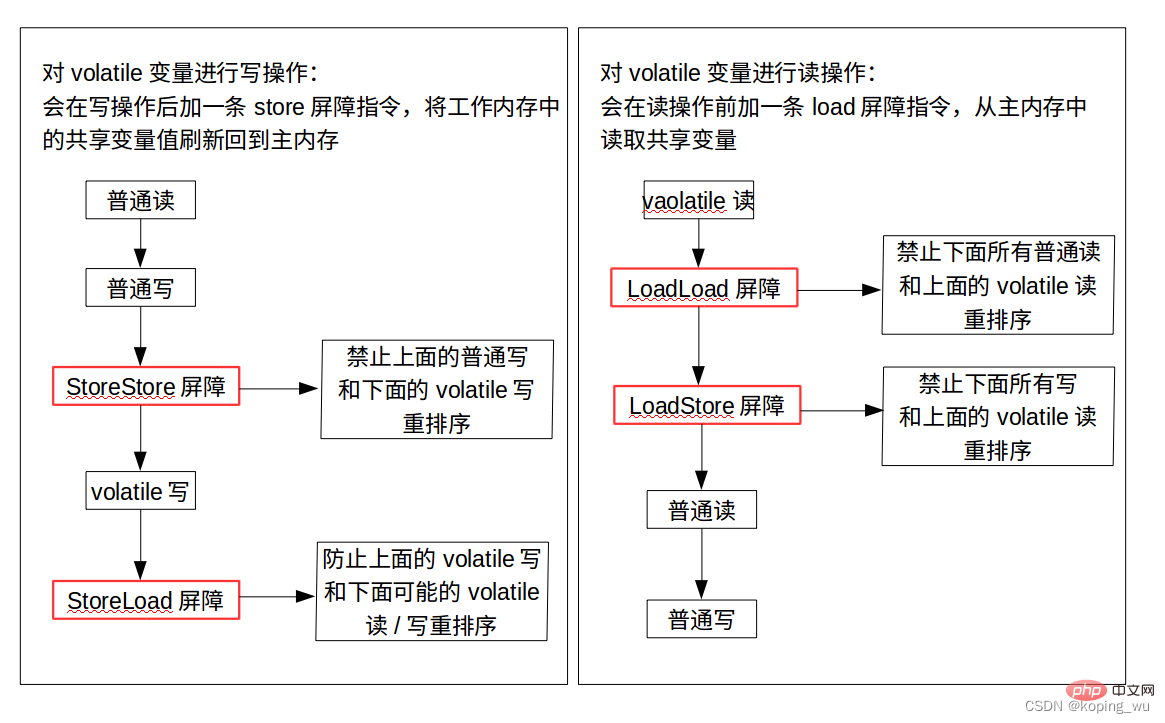
首先要了解一个概念:内存屏障(Memory Barrier),又称为内存栅栏。它是一个CPU指令,有2个作用:
1)保证特定操作的执行顺序;
2)保证某些变量的内存可见性;
由于编译器和处理器都能执行指令重排。如果在指令之间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序,也就是说,通过插入内存屏障,禁止在内存屏障前后的指令执行重排需优化。
内存屏障的另一个作用是强制刷出各种CPU的缓存数据,因此任何CPU上的线程都能读取到这些数据的最新版本。
推荐学习:《java视频教程》
위 내용은 Java 기본 휘발성에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!